Rethinking Centered Kernel Alignment in Knowledge Distillation

0
🧪
Sign in to get full access
Overview
- Knowledge distillation is a method for transferring knowledge from a large, complex model (the "teacher") to a smaller, more efficient model (the "student")
- Centered Kernel Alignment (CKA) is a widely used technique for measuring the similarity between representations in knowledge distillation
- However, existing CKA-based methods are complex and fail to fully explain how CKA can be used effectively for simple and effective distillation
Plain English Explanation
Knowledge distillation is a way to take the knowledge from a big, powerful AI model and transfer it to a smaller, more lightweight model. This is useful when you want to deploy an AI system on a device with limited computing power, like a smartphone. The big model is the "teacher" and the small model is the "student."
To transfer the knowledge, researchers often use a technique called Centered Kernel Alignment (CKA) to measure how similar the representations (the way the models understand the data) are between the teacher and the student. However, the current CKA-based methods are quite complicated and don't fully explain how to use CKA in a simple and effective way to do this knowledge distillation.
Technical Explanation
This paper provides a new theoretical perspective on CKA, showing that it is related to the Upper Bound of Maximum Mean Discrepancy (MMD), which is a way to measure the difference between two probability distributions. Based on this insight, the authors propose a novel framework called Relation-Centered Kernel Alignment (RCKA), which establishes a direct connection between CKA and MMD.
Furthermore, the paper demonstrates how to dynamically customize the application of CKA based on the specific characteristics of each task, achieving comparable performance to previous methods but with less computational resources required.
The researchers extensively tested their approach on image classification and object detection tasks, using datasets like CIFAR-100, ImageNet-1k, and MS-COCO. They found that their method achieves state-of-the-art performance on almost all teacher-student pairs, validating the effectiveness of their approach.
Critical Analysis
The paper provides a solid theoretical foundation for understanding CKA and how it can be used effectively for knowledge distillation. The RCKA framework is a novel contribution that simplifies the application of CKA while maintaining strong performance.
However, the paper does not discuss any potential limitations or caveats of their approach. It would be helpful to understand the scenarios where RCKA may not perform as well, or if there are any trade-offs in terms of model accuracy or computational efficiency.
Additionally, the authors could have explored more diverse applications of their method, such as distillation for other types of AI models beyond computer vision tasks.
Conclusion
This paper presents a significant advancement in the field of knowledge distillation by providing a deeper understanding of Centered Kernel Alignment (CKA) and leveraging this insight to develop a more efficient and effective distillation framework, Relation-Centered Kernel Alignment (RCKA). The extensive experiments demonstrate the state-of-the-art performance of RCKA, making it a promising approach for deploying powerful AI models on resource-constrained devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
0
Rethinking Centered Kernel Alignment in Knowledge Distillation
Zikai Zhou, Yunhang Shen, Shitong Shao, Linrui Gong, Shaohui Lin
Knowledge distillation has emerged as a highly effective method for bridging the representation discrepancy between large-scale models and lightweight models. Prevalent approaches involve leveraging appropriate metrics to minimize the divergence or distance between the knowledge extracted from the teacher model and the knowledge learned by the student model. Centered Kernel Alignment (CKA) is widely used to measure representation similarity and has been applied in several knowledge distillation methods. However, these methods are complex and fail to uncover the essence of CKA, thus not answering the question of how to use CKA to achieve simple and effective distillation properly. This paper first provides a theoretical perspective to illustrate the effectiveness of CKA, which decouples CKA to the upper bound of Maximum Mean Discrepancy~(MMD) and a constant term. Drawing from this, we propose a novel Relation-Centered Kernel Alignment~(RCKA) framework, which practically establishes a connection between CKA and MMD. Furthermore, we dynamically customize the application of CKA based on the characteristics of each task, with less computational source yet comparable performance than the previous methods. The extensive experiments on the CIFAR-100, ImageNet-1k, and MS-COCO demonstrate that our method achieves state-of-the-art performance on almost all teacher-student pairs for image classification and object detection, validating the effectiveness of our approaches. Our code is available in https://github.com/Klayand/PCKA
Read more5/1/2024
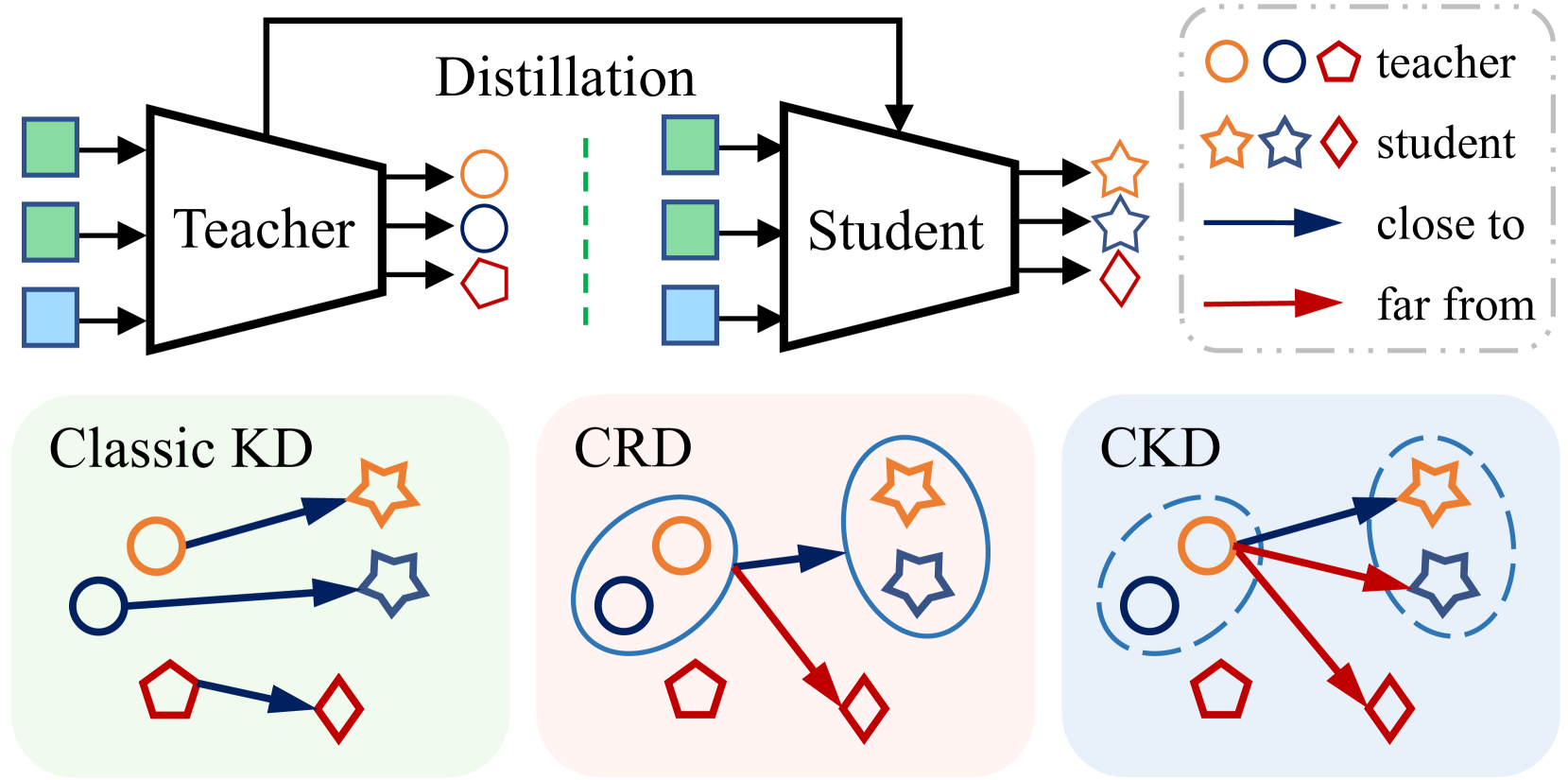
0
CKD: Contrastive Knowledge Distillation from A Sample-wise Perspective
Wencheng Zhu, Xin Zhou, Pengfei Zhu, Yu Wang, Qinghua Hu
In this paper, we present a simple yet effective contrastive knowledge distillation approach, which can be formulated as a sample-wise alignment problem with intra- and inter-sample constraints. Unlike traditional knowledge distillation methods that concentrate on maximizing feature similarities or preserving class-wise semantic correlations between teacher and student features, our method attempts to recover the dark knowledge by aligning sample-wise teacher and student logits. Specifically, our method first minimizes logit differences within the same sample by considering their numerical values, thus preserving intra-sample similarities. Next, we bridge semantic disparities by leveraging dissimilarities across different samples. Note that constraints on intra-sample similarities and inter-sample dissimilarities can be efficiently and effectively reformulated into a contrastive learning framework with newly designed positive and negative pairs. The positive pair consists of the teacher's and student's logits derived from an identical sample, while the negative pairs are formed by using logits from different samples. With this formulation, our method benefits from the simplicity and efficiency of contrastive learning through the optimization of InfoNCE, yielding a run-time complexity that is far less than $O(n^2)$, where $n$ represents the total number of training samples. Furthermore, our method can eliminate the need for hyperparameter tuning, particularly related to temperature parameters and large batch sizes. We conduct comprehensive experiments on three datasets including CIFAR-100, ImageNet-1K, and MS COCO. Experimental results clearly confirm the effectiveness of the proposed method on both image classification and object detection tasks. Our source codes will be publicly available at https://github.com/wencheng-zhu/CKD.
Read more4/23/2024

0
Relational Representation Distillation
Nikolaos Giakoumoglou, Tania Stathaki
Knowledge distillation (KD) is an effective method for transferring knowledge from a large, well-trained teacher model to a smaller, more efficient student model. Despite its success, one of the main challenges in KD is ensuring the efficient transfer of complex knowledge while maintaining the student's computational efficiency. Unlike previous works that applied contrastive objectives promoting explicit negative instances with little attention to the relationships between them, we introduce Relational Representation Distillation (RRD). Our approach leverages pairwise similarities to explore and reinforce the relationships between the teacher and student models. Inspired by self-supervised learning principles, it uses a relaxed contrastive loss that focuses on similarity rather than exact replication. This method aligns the output distributions of teacher samples in a large memory buffer, improving the robustness and performance of the student model without the need for strict negative instance differentiation. Our approach demonstrates superior performance on CIFAR-100 and ImageNet ILSVRC-2012, outperforming traditional KD and sometimes even outperforms the teacher network when combined with KD. It also transfers successfully to other datasets like Tiny ImageNet and STL-10. Code is available at https://github.com/giakoumoglou/distillers.
Read more9/10/2024
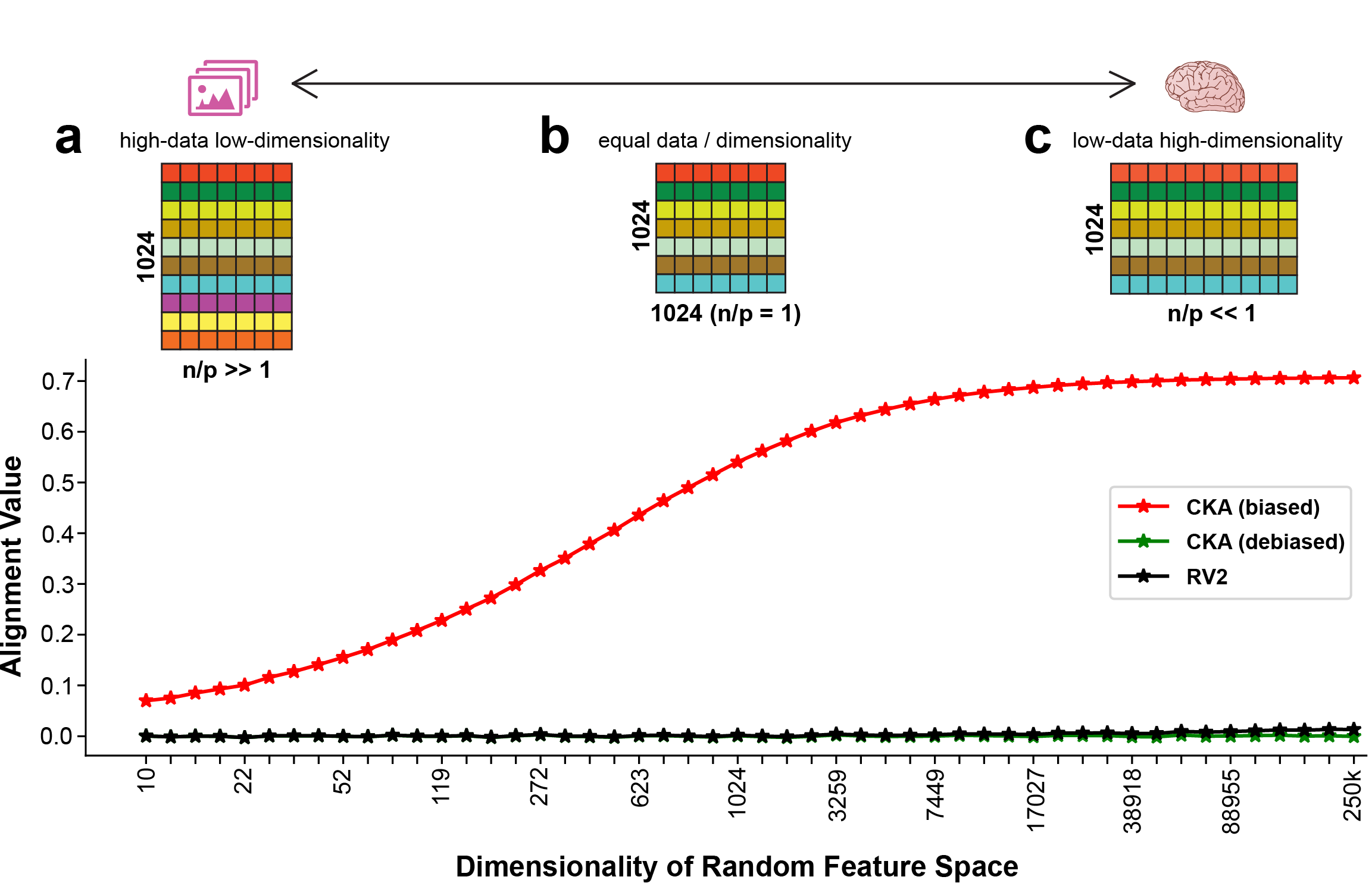
0
Correcting Biased Centered Kernel Alignment Measures in Biological and Artificial Neural Networks
Alex Murphy, Joel Zylberberg, Alona Fyshe
Centred Kernel Alignment (CKA) has recently emerged as a popular metric to compare activations from biological and artificial neural networks (ANNs) in order to quantify the alignment between internal representations derived from stimuli sets (e.g. images, text, video) that are presented to both systems. In this paper we highlight issues that the community should take into account if using CKA as an alignment metric with neural data. Neural data are in the low-data high-dimensionality domain, which is one of the cases where (biased) CKA results in high similarity scores even for pairs of random matrices. Using fMRI and MEG data from the THINGS project, we show that if biased CKA is applied to representations of different sizes in the low-data high-dimensionality domain, they are not directly comparable due to biased CKA's sensitivity to differing feature-sample ratios and not stimuli-driven responses. This situation can arise both when comparing a pre-selected area of interest (e.g. ROI) to multiple ANN layers, as well as when determining to which ANN layer multiple regions of interest (ROIs) / sensor groups of different dimensionality are most similar. We show that biased CKA can be artificially driven to its maximum value when using independent random data of different sample-feature ratios. We further show that shuffling sample-feature pairs of real neural data does not drastically alter biased CKA similarity in comparison to unshuffled data, indicating an undesirable lack of sensitivity to stimuli-driven neural responses. Positive alignment of true stimuli-driven responses is only achieved by using debiased CKA. Lastly, we report findings that suggest biased CKA is sensitive to the inherent structure of neural data, only differing from shuffled data when debiased CKA detects stimuli-driven alignment.
Read more5/3/2024