CKD: Contrastive Knowledge Distillation from A Sample-wise Perspective
2404.14109
0
0
Abstract
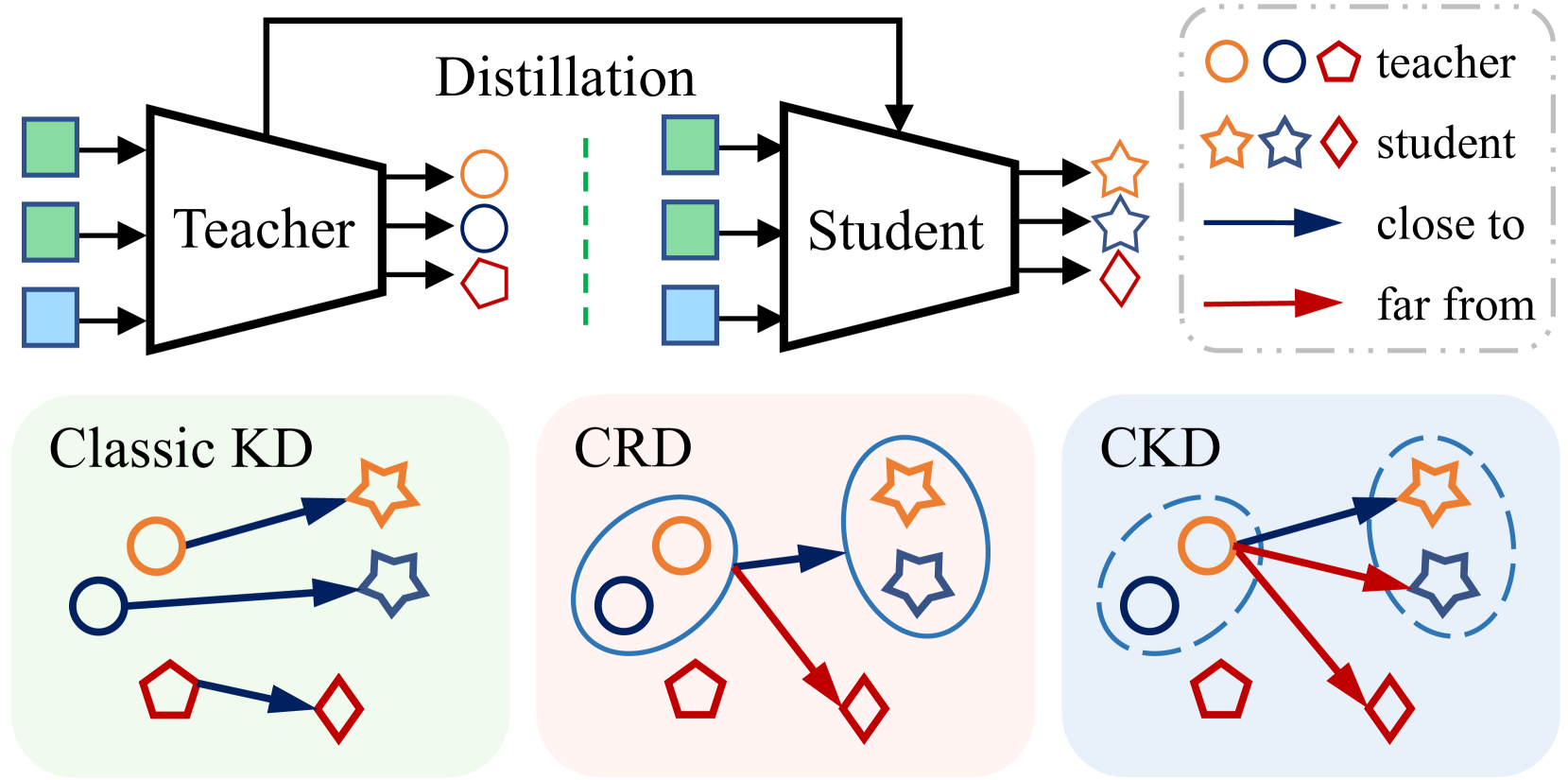
In this paper, we present a simple yet effective contrastive knowledge distillation approach, which can be formulated as a sample-wise alignment problem with intra- and inter-sample constraints. Unlike traditional knowledge distillation methods that concentrate on maximizing feature similarities or preserving class-wise semantic correlations between teacher and student features, our method attempts to recover the dark knowledge by aligning sample-wise teacher and student logits. Specifically, our method first minimizes logit differences within the same sample by considering their numerical values, thus preserving intra-sample similarities. Next, we bridge semantic disparities by leveraging dissimilarities across different samples. Note that constraints on intra-sample similarities and inter-sample dissimilarities can be efficiently and effectively reformulated into a contrastive learning framework with newly designed positive and negative pairs. The positive pair consists of the teacher's and student's logits derived from an identical sample, while the negative pairs are formed by using logits from different samples. With this formulation, our method benefits from the simplicity and efficiency of contrastive learning through the optimization of InfoNCE, yielding a run-time complexity that is far less than $O(n^2)$, where $n$ represents the total number of training samples. Furthermore, our method can eliminate the need for hyperparameter tuning, particularly related to temperature parameters and large batch sizes. We conduct comprehensive experiments on three datasets including CIFAR-100, ImageNet-1K, and MS COCO. Experimental results clearly confirm the effectiveness of the proposed method on both image classification and object detection tasks. Our source codes will be publicly available at https://github.com/wencheng-zhu/CKD.
Create account to get full access
Overview
- This paper proposes Contrastive Knowledge Distillation (CKD), a novel knowledge distillation technique that aligns student and teacher models at the sample level.
- CKD introduces intra- and inter-sample constraints to improve the quality of knowledge transfer, leading to enhanced performance of the student model.
- The authors demonstrate the effectiveness of CKD on various computer vision tasks, including image classification and object detection.
Plain English Explanation
Knowledge distillation is a technique used to train a smaller, more efficient "student" model by transferring knowledge from a larger, more complex "teacher" model. Robust Feature Knowledge Distillation for Enhanced Performance of Lightweight Models and CrossKD: Cross-Head Knowledge Distillation for Object Detection are two examples of previous work in this area.
The key innovation of this paper is the use of "contrastive learning" to improve the knowledge transfer process. Contrastive learning encourages the student model to learn features that are similar to the teacher model for the same input sample, while being dissimilar for different input samples. This helps the student model better capture the underlying patterns and relationships in the data.
The authors introduce two types of constraints to achieve this sample-wise alignment:
- Intra-sample constraint: This ensures that the student model's output for a given input sample is similar to the teacher model's output for the same sample.
- Inter-sample constraint: This ensures that the student model's outputs for different input samples are dissimilar, mirroring the differences in the teacher model's outputs.
By incorporating these constraints, the CKD approach can more effectively transfer knowledge from the teacher to the student model, leading to improved performance of the lightweight student model on a variety of computer vision tasks.
Technical Explanation
The authors propose a Contrastive Knowledge Distillation (CKD) framework that aligns the student and teacher models at the sample level, in contrast to previous knowledge distillation methods that typically focus on aligning the models' outputs or intermediate representations in a global manner.
CKD introduces two key components:
-
Intra-sample constraint: This constraint ensures that the student model's output for a given input sample is similar to the teacher model's output for the same sample. This is achieved by minimizing the distance between the student and teacher outputs for each input.
-
Inter-sample constraint: This constraint encourages the student model to produce dissimilar outputs for different input samples, mirroring the differences in the teacher model's outputs. This is accomplished by maximizing the distance between the student model's outputs for different inputs.
By incorporating these intra- and inter-sample constraints, CKD can better capture the underlying patterns and relationships in the data, leading to more effective knowledge transfer from the teacher to the student model.
The authors evaluate CKD on various computer vision tasks, including image classification and object detection. They demonstrate that CKD outperforms traditional knowledge distillation techniques, such as Knowledge Distillation via Target-Aware Transformer and MiniLLM: Knowledge Distillation for Large Language Models, in terms of the student model's performance.
Critical Analysis
The authors provide a thorough evaluation of CKD and demonstrate its effectiveness on several computer vision tasks. However, the paper does not address the potential limitations or caveats of the proposed approach.
One potential concern is the computational overhead associated with the additional intra- and inter-sample constraints. The authors do not discuss the impact of these constraints on the training time or resources required, which could be an important consideration for real-world applications.
Additionally, the paper does not explore the generalization of CKD to other domains beyond computer vision, such as natural language processing or speech recognition. It would be valuable to understand how the approach could be adapted and applied to a wider range of tasks.
Further research could also investigate the robustness of CKD to different types of noise or distribution shifts in the input data, as well as its performance on more challenging or diverse datasets.
Conclusion
This paper presents Contrastive Knowledge Distillation (CKD), a novel knowledge distillation technique that aligns student and teacher models at the sample level. By introducing intra- and inter-sample constraints, CKD can more effectively transfer knowledge from the teacher to the student model, leading to enhanced performance of the lightweight student model on computer vision tasks.
The authors demonstrate the effectiveness of CKD through extensive experiments, but further research is needed to address potential limitations and explore the generalization of the approach to other domains. Overall, CKD represents an important contribution to the field of knowledge distillation and has the potential to improve the efficiency of deep learning models in various applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
Rethinking Centered Kernel Alignment in Knowledge Distillation
Zikai Zhou, Yunhang Shen, Shitong Shao, Linrui Gong, Shaohui Lin
0
0
Knowledge distillation has emerged as a highly effective method for bridging the representation discrepancy between large-scale models and lightweight models. Prevalent approaches involve leveraging appropriate metrics to minimize the divergence or distance between the knowledge extracted from the teacher model and the knowledge learned by the student model. Centered Kernel Alignment (CKA) is widely used to measure representation similarity and has been applied in several knowledge distillation methods. However, these methods are complex and fail to uncover the essence of CKA, thus not answering the question of how to use CKA to achieve simple and effective distillation properly. This paper first provides a theoretical perspective to illustrate the effectiveness of CKA, which decouples CKA to the upper bound of Maximum Mean Discrepancy~(MMD) and a constant term. Drawing from this, we propose a novel Relation-Centered Kernel Alignment~(RCKA) framework, which practically establishes a connection between CKA and MMD. Furthermore, we dynamically customize the application of CKA based on the characteristics of each task, with less computational source yet comparable performance than the previous methods. The extensive experiments on the CIFAR-100, ImageNet-1k, and MS-COCO demonstrate that our method achieves state-of-the-art performance on almost all teacher-student pairs for image classification and object detection, validating the effectiveness of our approaches. Our code is available in https://github.com/Klayand/PCKA
5/1/2024

Small Scale Data-Free Knowledge Distillation
He Liu, Yikai Wang, Huaping Liu, Fuchun Sun, Anbang Yao
0
0
Data-free knowledge distillation is able to utilize the knowledge learned by a large teacher network to augment the training of a smaller student network without accessing the original training data, avoiding privacy, security, and proprietary risks in real applications. In this line of research, existing methods typically follow an inversion-and-distillation paradigm in which a generative adversarial network on-the-fly trained with the guidance of the pre-trained teacher network is used to synthesize a large-scale sample set for knowledge distillation. In this paper, we reexamine this common data-free knowledge distillation paradigm, showing that there is considerable room to improve the overall training efficiency through a lens of ``small-scale inverted data for knowledge distillation. In light of three empirical observations indicating the importance of how to balance class distributions in terms of synthetic sample diversity and difficulty during both data inversion and distillation processes, we propose Small Scale Data-free Knowledge Distillation SSD-KD. In formulation, SSD-KD introduces a modulating function to balance synthetic samples and a priority sampling function to select proper samples, facilitated by a dynamic replay buffer and a reinforcement learning strategy. As a result, SSD-KD can perform distillation training conditioned on an extremely small scale of synthetic samples (e.g., 10X less than the original training data scale), making the overall training efficiency one or two orders of magnitude faster than many mainstream methods while retaining superior or competitive model performance, as demonstrated on popular image classification and semantic segmentation benchmarks. The code is available at https://github.com/OSVAI/SSD-KD.
6/13/2024

On the Theory of Cross-Modality Distillation with Contrastive Learning
Hangyu Lin, Chen Liu, Chengming Xu, Zhengqi Gao, Yanwei Fu, Yuan Yao
0
0
Cross-modality distillation arises as an important topic for data modalities containing limited knowledge such as depth maps and high-quality sketches. Such techniques are of great importance, especially for memory and privacy-restricted scenarios where labeled training data is generally unavailable. To solve the problem, existing label-free methods leverage a few pairwise unlabeled data to distill the knowledge by aligning features or statistics between the source and target modalities. For instance, one typically aims to minimize the L2 distance or contrastive loss between the learned features of pairs of samples in the source (e.g. image) and the target (e.g. sketch) modalities. However, most algorithms in this domain only focus on the experimental results but lack theoretical insight. To bridge the gap between the theory and practical method of cross-modality distillation, we first formulate a general framework of cross-modality contrastive distillation (CMCD), built upon contrastive learning that leverages both positive and negative correspondence, towards a better distillation of generalizable features. Furthermore, we establish a thorough convergence analysis that reveals that the distance between source and target modalities significantly impacts the test error on downstream tasks within the target modality which is also validated by the empirical results. Extensive experimental results show that our algorithm outperforms existing algorithms consistently by a margin of 2-3% across diverse modalities and tasks, covering modalities of image, sketch, depth map, and audio and tasks of recognition and segmentation.
5/29/2024

Densely Distilling Cumulative Knowledge for Continual Learning
Zenglin Shi, Pei Liu, Tong Su, Yunpeng Wu, Kuien Liu, Yu Song, Meng Wang
0
0
Continual learning, involving sequential training on diverse tasks, often faces catastrophic forgetting. While knowledge distillation-based approaches exhibit notable success in preventing forgetting, we pinpoint a limitation in their ability to distill the cumulative knowledge of all the previous tasks. To remedy this, we propose Dense Knowledge Distillation (DKD). DKD uses a task pool to track the model's capabilities. It partitions the output logits of the model into dense groups, each corresponding to a task in the task pool. It then distills all tasks' knowledge using all groups. However, using all the groups can be computationally expensive, we also suggest random group selection in each optimization step. Moreover, we propose an adaptive weighting scheme, which balances the learning of new classes and the retention of old classes, based on the count and similarity of the classes. Our DKD outperforms recent state-of-the-art baselines across diverse benchmarks and scenarios. Empirical analysis underscores DKD's ability to enhance model stability, promote flatter minima for improved generalization, and remains robust across various memory budgets and task orders. Moreover, it seamlessly integrates with other CL methods to boost performance and proves versatile in offline scenarios like model compression.
5/17/2024