Correcting Biased Centered Kernel Alignment Measures in Biological and Artificial Neural Networks

0
Sign in to get full access
Overview
- Centered Kernel Alignment (CKA) is a popular method for measuring the similarity between neural network representations.
- However, recent research has shown that CKA can be biased, leading to misleading conclusions about the relationships between neural networks.
- This paper proposes a corrected version of CKA that addresses these biases, improving the accuracy and reliability of CKA-based analyses.
Plain English Explanation
Correcting Biased Centered Kernel Alignment Measures in Biological and Artificial Neural Networks explores an issue with a common technique used to compare neural networks, called Centered Kernel Alignment (CKA). CKA is often used to understand how the internal representations of neural networks are related, but the authors show that CKA can sometimes give misleading results due to hidden biases in the way it works.
To fix this problem, the researchers propose a new version of CKA that corrects these biases. This improved CKA measure can provide more accurate and reliable insights into the relationships between neural networks, whether they are artificial intelligence models or biological neural networks in the brain.
Technical Explanation
Centered Kernel Alignment (CKA) is a widely used method for quantifying the similarity between the internal representations of neural networks. It works by comparing the "kernel" or pattern of activations in one network to the kernel in another network.
However, the authors of this paper show that standard CKA can be biased, meaning it can sometimes suggest networks are more similar than they really are. This bias can lead to incorrect conclusions about how neural networks are related, which is problematic for applications like knowledge distillation and architecture design.
To address this, the researchers propose a corrected version of CKA that removes the bias. They demonstrate through experiments that this debiased CKA provides more accurate and reliable comparisons of neural network representations, enabling better causal analysis and a deeper understanding of network architectures.
Critical Analysis
The paper provides a thorough analysis of the biases inherent in standard CKA and presents a compelling solution in the form of debiased CKA. However, the authors acknowledge that their method relies on certain assumptions, such as the independence of layer activations, which may not always hold true in practice.
Additionally, the paper focuses on CKA in the context of neural networks, but the biases they identify could potentially apply to other kernel-based similarity measures used in different domains. Further research may be needed to understand the broader implications and applicability of the debiased CKA method.
Conclusion
This paper makes an important contribution by revealing and correcting the biases in Centered Kernel Alignment, a widely used technique for analyzing neural networks. The proposed debiased CKA measure can lead to more accurate and reliable comparisons of neural network representations, with potentially significant implications for fields like knowledge distillation, architecture design, and causal analysis. The findings in this paper encourage researchers to think critically about the assumptions and limitations of the tools they use to study complex systems like artificial and biological neural networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Correcting Biased Centered Kernel Alignment Measures in Biological and Artificial Neural Networks
Alex Murphy, Joel Zylberberg, Alona Fyshe
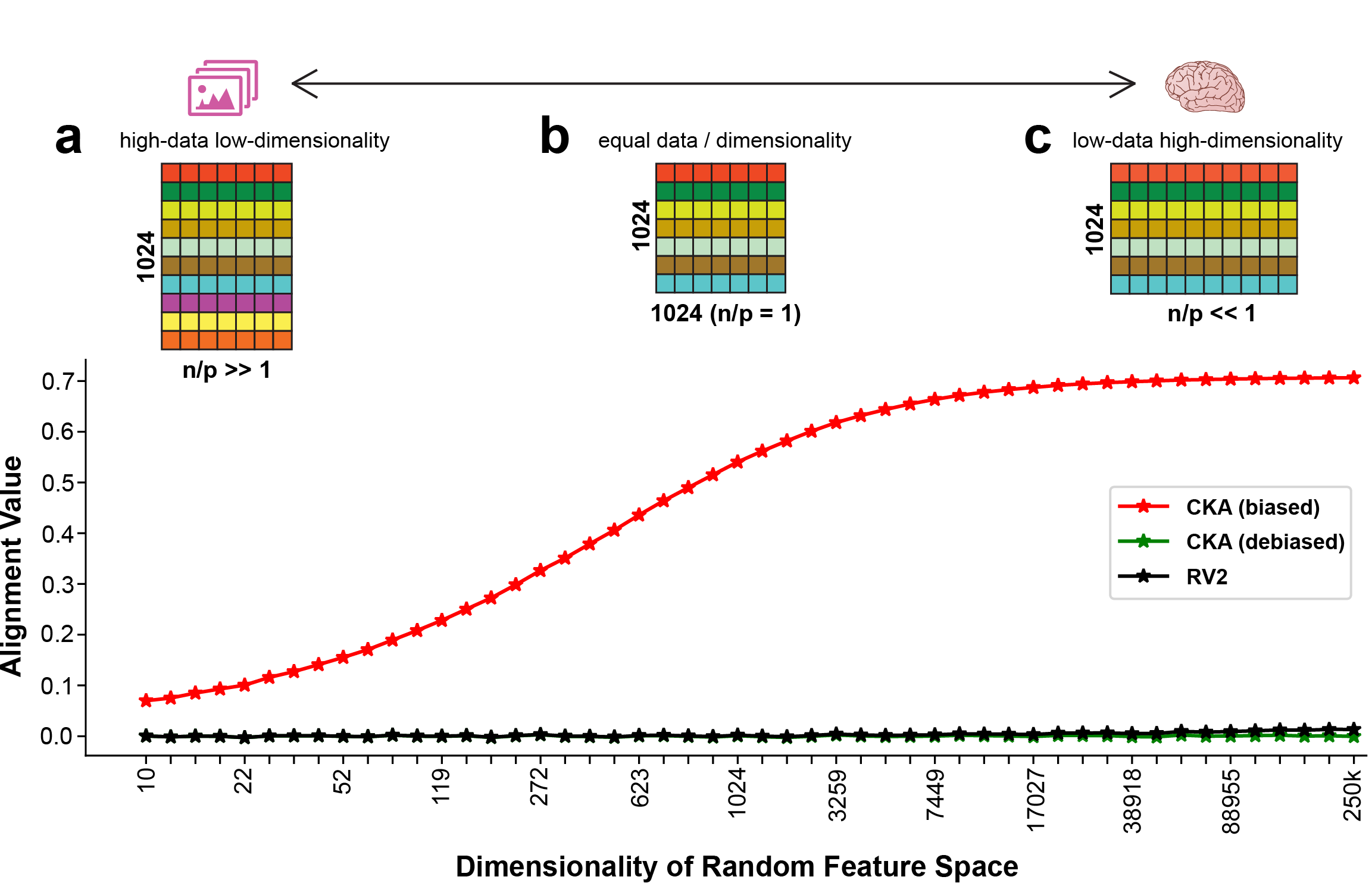
Centred Kernel Alignment (CKA) has recently emerged as a popular metric to compare activations from biological and artificial neural networks (ANNs) in order to quantify the alignment between internal representations derived from stimuli sets (e.g. images, text, video) that are presented to both systems. In this paper we highlight issues that the community should take into account if using CKA as an alignment metric with neural data. Neural data are in the low-data high-dimensionality domain, which is one of the cases where (biased) CKA results in high similarity scores even for pairs of random matrices. Using fMRI and MEG data from the THINGS project, we show that if biased CKA is applied to representations of different sizes in the low-data high-dimensionality domain, they are not directly comparable due to biased CKA's sensitivity to differing feature-sample ratios and not stimuli-driven responses. This situation can arise both when comparing a pre-selected area of interest (e.g. ROI) to multiple ANN layers, as well as when determining to which ANN layer multiple regions of interest (ROIs) / sensor groups of different dimensionality are most similar. We show that biased CKA can be artificially driven to its maximum value when using independent random data of different sample-feature ratios. We further show that shuffling sample-feature pairs of real neural data does not drastically alter biased CKA similarity in comparison to unshuffled data, indicating an undesirable lack of sensitivity to stimuli-driven neural responses. Positive alignment of true stimuli-driven responses is only achieved by using debiased CKA. Lastly, we report findings that suggest biased CKA is sensitive to the inherent structure of neural data, only differing from shuffled data when debiased CKA detects stimuli-driven alignment.
Read more5/3/2024
🧪
0
Rethinking Centered Kernel Alignment in Knowledge Distillation
Zikai Zhou, Yunhang Shen, Shitong Shao, Linrui Gong, Shaohui Lin
Knowledge distillation has emerged as a highly effective method for bridging the representation discrepancy between large-scale models and lightweight models. Prevalent approaches involve leveraging appropriate metrics to minimize the divergence or distance between the knowledge extracted from the teacher model and the knowledge learned by the student model. Centered Kernel Alignment (CKA) is widely used to measure representation similarity and has been applied in several knowledge distillation methods. However, these methods are complex and fail to uncover the essence of CKA, thus not answering the question of how to use CKA to achieve simple and effective distillation properly. This paper first provides a theoretical perspective to illustrate the effectiveness of CKA, which decouples CKA to the upper bound of Maximum Mean Discrepancy~(MMD) and a constant term. Drawing from this, we propose a novel Relation-Centered Kernel Alignment~(RCKA) framework, which practically establishes a connection between CKA and MMD. Furthermore, we dynamically customize the application of CKA based on the characteristics of each task, with less computational source yet comparable performance than the previous methods. The extensive experiments on the CIFAR-100, ImageNet-1k, and MS-COCO demonstrate that our method achieves state-of-the-art performance on almost all teacher-student pairs for image classification and object detection, validating the effectiveness of our approaches. Our code is available in https://github.com/Klayand/PCKA
Read more5/1/2024

0
Differentiable Optimization of Similarity Scores Between Models and Brains
Nathan Cloos, Moufan Li, Markus Siegel, Scott L. Brincat, Earl K. Miller, Guangyu Robert Yang, Christopher J. Cueva
What metrics should guide the development of more realistic models of the brain? One proposal is to quantify the similarity between models and brains using methods such as linear regression, Centered Kernel Alignment (CKA), and angular Procrustes distance. To better understand the limitations of these similarity measures we analyze neural activity recorded in five experiments on nonhuman primates, and optimize synthetic datasets to become more similar to these neural recordings. How similar can these synthetic datasets be to neural activity while failing to encode task relevant variables? We find that some measures like linear regression and CKA, differ from angular Procrustes, and yield high similarity scores even when task relevant variables cannot be linearly decoded from the synthetic datasets. Synthetic datasets optimized to maximize similarity scores initially learn the first principal component of the target dataset, but angular Procrustes captures higher variance dimensions much earlier than methods like linear regression and CKA. We show in both theory and simulations how these scores change when different principal components are perturbed. And finally, we jointly optimize multiple similarity scores to find their allowed ranges, and show that a high angular Procrustes similarity, for example, implies a high CKA score, but not the converse.
Read more7/10/2024

0
How Aligned are Different Alignment Metrics?
Jannis Ahlert, Thomas Klein, Felix Wichmann, Robert Geirhos
In recent years, various methods and benchmarks have been proposed to empirically evaluate the alignment of artificial neural networks to human neural and behavioral data. But how aligned are different alignment metrics? To answer this question, we analyze visual data from Brain-Score (Schrimpf et al., 2018), including metrics from the model-vs-human toolbox (Geirhos et al., 2021), together with human feature alignment (Linsley et al., 2018; Fel et al., 2022) and human similarity judgements (Muttenthaler et al., 2022). We find that pairwise correlations between neural scores and behavioral scores are quite low and sometimes even negative. For instance, the average correlation between those 80 models on Brain-Score that were fully evaluated on all 69 alignment metrics we considered is only 0.198. Assuming that all of the employed metrics are sound, this implies that alignment with human perception may best be thought of as a multidimensional concept, with different methods measuring fundamentally different aspects. Our results underline the importance of integrative benchmarking, but also raise questions about how to correctly combine and aggregate individual metrics. Aggregating by taking the arithmetic average, as done in Brain-Score, leads to the overall performance currently being dominated by behavior (95.25% explained variance) while the neural predictivity plays a less important role (only 33.33% explained variance). As a first step towards making sure that different alignment metrics all contribute fairly towards an integrative benchmark score, we therefore conclude by comparing three different aggregation options.
Read more7/11/2024