Rethinking the Influence of Source Code on Test Case Generation

0
🛸
Sign in to get full access
Overview
- Large language models (LLMs) have been used to generate test cases for software code.
- This paper investigates whether LLMs can still generate effective tests if the code they are given is incorrect.
- The researchers evaluated the accuracy, coverage, and bug-detecting ability of tests generated by LLMs on both correct and incorrect code.
Plain English Explanation
When software developers are creating new features or fixing bugs, they often write test cases to ensure their code is working as expected. These test cases check that the software behaves correctly in different scenarios.
Researchers have started using large language models (LLMs) to help generate these test cases automatically, using the software code as input. This can save developers time and effort.
However, the researchers in this paper wanted to know: what happens if the software code that the LLM is given is incorrect or buggy? Will the LLM still be able to generate effective test cases, or will it be "misguided" by the faulty code?
To find out, the researchers evaluated how well the tests generated by five open-source and six closed-source LLMs performed on both correct and incorrect code, across four different datasets. They looked at the accuracy of the tests, how much of the code they covered, and how well they detected bugs.
The results showed that incorrect code can significantly reduce the quality of the tests generated by LLMs. For example, on the HumanEval dataset, LLMs achieved 80.45% test accuracy when given correct code, but only 57.12% when given incorrect code. And on the APPS dataset, tests generated from correct code detected 39.85% of bugs, while tests from incorrect code only detected 19.61%.
These findings have important implications for using LLM-based testing in real-world software development. Using LLMs on mature, well-tested code may help catch future regressions. But using them on early-stage, buggy code may simply perpetuate the existing errors. The researchers conclude that more research is needed to improve LLMs' resilience to incorrect code and generate more reliable, bug-revealing tests.
Technical Explanation
The researchers conducted experiments using five open-source and six closed-source LLMs on four different datasets: HumanEval, APPS, CodeXGLUE, and DeepFix. They evaluated the LLMs' performance in generating test cases for both correct and incorrect versions of the code in these datasets.
The key metrics they used to assess the test cases were:
- Accuracy: How well the generated tests matched the expected outputs.
- Coverage: How much of the code was exercised by the generated tests.
- Bug detection: How many bugs in the code were detected by the generated tests.
The results showed a substantial drop in performance when the LLMs were given incorrect code as input. For example, on the HumanEval dataset, the LLMs achieved 80.45% test accuracy with correct code, but only 57.12% with incorrect code. And on the APPS dataset, tests generated from correct code detected 39.85% of bugs, while those from incorrect code detected only 19.61%.
The researchers attribute this degradation in performance to the LLMs being "misguided" by the faulty code, leading them to generate tests that perpetuate the existing errors rather than revealing new ones.
Critical Analysis
The paper provides valuable insights into the limitations of using LLMs for automated test case generation, particularly when the code being tested is incorrect or immature.
One key caveat is that the researchers only evaluated the LLMs on a limited number of datasets and code defects. More research is needed to understand how these findings generalize to a wider range of software projects and bug types.
Additionally, the paper does not explore potential strategies for mitigating the impact of incorrect code on LLM-generated tests. Techniques like code sanitization, anomaly detection, or incorporating additional information sources may help improve the LLMs' resilience. Further research in this area could lead to more robust LLM-based testing tools.
Overall, this paper raises important concerns about the limitations of using LLMs for test case generation on immature or buggy code. The findings underscore the need for caution and further research to ensure the reliability and effectiveness of LLM-based testing solutions.
Conclusion
This paper demonstrates that large language models (LLMs) can be significantly misguided when generating test cases for software code that contains errors or bugs. The researchers found that LLMs achieved substantially lower accuracy, coverage, and bug-detecting ability when working with incorrect code, compared to correct code.
These findings have important implications for the real-world deployment of LLM-based testing tools. While such tools may be helpful for maintaining mature, well-tested codebases, they may simply perpetuate existing errors when used on early-stage, immature code. The paper emphasizes the need for further research to improve the resilience of LLMs to incorrect code and generate more reliable, bug-revealing tests.
As the use of LLMs in software engineering continues to grow, studies like this one will be crucial for understanding the limitations and challenges of these powerful models. By addressing these issues, researchers can help ensure that LLM-based tools are deployed safely and effectively in software development workflows.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
New!Rethinking the Influence of Source Code on Test Case Generation
Dong Huang, Jie M. Zhang, Mingzhe Du, Mark Harman, Heming Cui
Large language models (LLMs) have been widely applied to assist test generation with the source code under test provided as the context. This paper aims to answer the question: If the source code under test is incorrect, will LLMs be misguided when generating tests? The effectiveness of test cases is measured by their accuracy, coverage, and bug detection effectiveness. Our evaluation results with five open- and six closed-source LLMs on four datasets demonstrate that incorrect code can significantly mislead LLMs in generating correct, high-coverage, and bug-revealing tests. For instance, in the HumanEval dataset, LLMs achieve 80.45% test accuracy when provided with task descriptions and correct code, but only 57.12% when given task descriptions and incorrect code. For the APPS dataset, prompts with correct code yield tests that detect 39.85% of the bugs, while prompts with incorrect code detect only 19.61%. These findings have important implications for the deployment of LLM-based testing: using it on mature code may help protect against future regression, but on early-stage immature code, it may simply bake in errors. Our findings also underscore the need for further research to improve LLMs resilience against incorrect code in generating reliable and bug-revealing tests.
Read more9/17/2024

0
What's Wrong with Your Code Generated by Large Language Models? An Extensive Study
Shihan Dou, Haoxiang Jia, Shenxi Wu, Huiyuan Zheng, Weikang Zhou, Muling Wu, Mingxu Chai, Jessica Fan, Caishuang Huang, Yunbo Tao, Yan Liu, Enyu Zhou, Ming Zhang, Yuhao Zhou, Yueming Wu, Rui Zheng, Ming Wen, Rongxiang Weng, Jingang Wang, Xunliang Cai, Tao Gui, Xipeng Qiu, Qi Zhang, Xuanjing Huang
The increasing development of large language models (LLMs) in code generation has drawn significant attention among researchers. To enhance LLM-based code generation ability, current efforts are predominantly directed towards collecting high-quality datasets and leveraging diverse training technologies. However, there is a notable lack of comprehensive studies examining the limitations and boundaries of these existing methods. To bridge this gap, we conducted an extensive empirical study evaluating the performance of three leading closed-source LLMs and four popular open-source LLMs on three commonly used benchmarks. Our investigation, which evaluated the length, cyclomatic complexity and API number of the generated code, revealed that these LLMs face challenges in generating successful code for more complex problems, and tend to produce code that is shorter yet more complicated as compared to canonical solutions. Additionally, we developed a taxonomy of bugs for incorrect codes that includes three categories and 12 sub-categories, and analyze the root cause for common bug types. Furthermore, to better understand the performance of LLMs in real-world projects, we manually created a real-world benchmark comprising 140 code generation tasks. Our analysis highlights distinct differences in bug distributions between actual scenarios and existing benchmarks. Finally, we propose a novel training-free iterative method that introduces self-critique, enabling LLMs to critique and correct their generated code based on bug types and compiler feedback. Experimental results demonstrate that our approach can significantly mitigate bugs and increase the passing rate by 29.2% after two iterations, indicating substantial potential for LLMs to handle more complex problems.
Read more7/9/2024
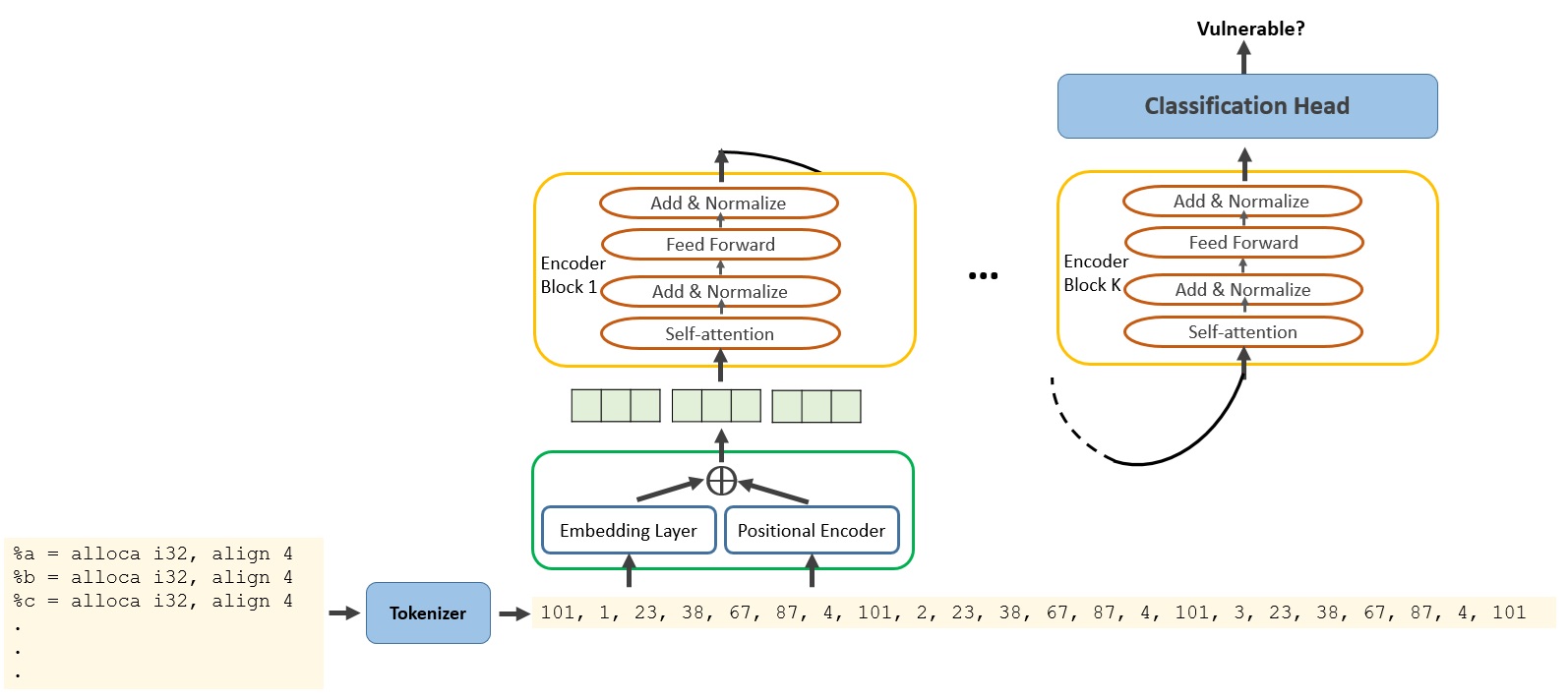
0
Harnessing the Power of LLMs in Source Code Vulnerability Detection
Andrew A Mahyari
Software vulnerabilities, caused by unintentional flaws in source code, are a primary root cause of cyberattacks. Static analysis of source code has been widely used to detect these unintentional defects introduced by software developers. Large Language Models (LLMs) have demonstrated human-like conversational abilities due to their capacity to capture complex patterns in sequential data, such as natural languages. In this paper, we harness LLMs' capabilities to analyze source code and detect known vulnerabilities. To ensure the proposed vulnerability detection method is universal across multiple programming languages, we convert source code to LLVM IR and train LLMs on these intermediate representations. We conduct extensive experiments on various LLM architectures and compare their accuracy. Our comprehensive experiments on real-world and synthetic codes from NVD and SARD demonstrate high accuracy in identifying source code vulnerabilities.
Read more8/9/2024
🤔
0
Understanding Defects in Generated Codes by Language Models
Ali Mohammadi Esfahani, Nafiseh Kahani, Samuel A. Ajila
This study investigates the reliability of code generation by Large Language Models (LLMs), focusing on identifying and analyzing defects in the generated code. Despite the advanced capabilities of LLMs in automating code generation, ensuring the accuracy and functionality of the output remains a significant challenge. By using a structured defect classification method to understand their nature and origins this study categorizes and analyzes 367 identified defects from code snippets generated by LLMs, with a significant proportion being functionality and algorithm errors. These error categories indicate key areas where LLMs frequently fail, underscoring the need for targeted improvements. To enhance the accuracy of code generation, this paper implemented five prompt engineering techniques, including Scratchpad Prompting, Program of Thoughts Prompting, Chain-of-Thought Prompting, Chain of Code Prompting, and Structured Chain-of-Thought Prompting. These techniques were applied to refine the input prompts, aiming to reduce ambiguities and improve the models' accuracy rate. The research findings suggest that precise and structured prompting significantly mitigates common defects, thereby increasing the reliability of LLM-generated code.
Read more8/27/2024