Rethinking Out-of-Distribution Detection on Imbalanced Data Distribution

0

Sign in to get full access
Overview
- The paper investigates out-of-distribution (OOD) detection on imbalanced datasets
- It proposes a new framework called ROOD to address the challenges of OOD detection in imbalanced settings
- The framework leverages a combination of techniques to improve OOD detection performance
Plain English Explanation
When machine learning models are deployed in real-world applications, they often encounter data that is different from the data they were trained on. This is known as out-of-distribution (OOD) data, and it can cause the model to make incorrect predictions. Detecting OOD data is an important problem in machine learning.
One challenge that arises in OOD detection is when the training data is imbalanced, meaning that some classes are much more common than others. This can make it difficult for the model to identify unusual or rare data points as OOD. The paper proposes a new framework called ROOD that aims to address this challenge.
The ROOD framework combines several techniques to improve OOD detection on imbalanced datasets. It uses a combination of regularization and adversarial training to learn a more robust representation of the data, and it also incorporates anomaly detection to identify outliers.
By using these techniques, the ROOD framework is able to achieve better OOD detection performance on imbalanced datasets compared to existing methods. This is an important step forward in making machine learning models more robust and reliable in real-world applications.
Technical Explanation
The paper proposes a new framework called ROOD (Rethinking Out-of-Distribution Detection) to address the challenge of OOD detection on imbalanced data distributions. The key components of the ROOD framework are:
-
Representation Learning: The framework uses a combination of regularization and adversarial training to learn a more robust representation of the data. This helps the model capture the underlying structure of the data more effectively, even in the presence of imbalance.
-
Anomaly Detection: The framework incorporates an anomaly detection module to identify outliers in the data. This complements the representation learning component by providing a way to explicitly detect instances that are significantly different from the training data.
-
Adaptive Thresholding: The framework uses an adaptive thresholding mechanism to determine the OOD score threshold, which is critical for accurate OOD detection. This helps the model adjust to the specific characteristics of the imbalanced dataset.
The authors evaluate the ROOD framework on several benchmark datasets and show that it outperforms state-of-the-art OOD detection methods, especially in the presence of imbalanced data distributions. The framework's ability to learn robust representations and effectively detect anomalies contributes to its improved performance.
Critical Analysis
The paper presents a well-designed and comprehensive framework for addressing the challenge of OOD detection on imbalanced data distributions. The key strengths of the ROOD framework are its ability to learn robust representations, incorporate anomaly detection, and adapt the OOD score threshold to the dataset at hand.
However, the paper does not discuss the computational complexity and training time of the ROOD framework, which could be an important consideration for practical deployment. Additionally, the paper could have explored the performance of the framework on a wider range of imbalanced datasets and tasks, to further validate its generalizability.
It would also be interesting to see how the ROOD framework performs in comparison to other recently proposed OOD detection methods that specifically target imbalanced data, such as Continual Unsupervised Out-of-Distribution Detection or Noisy Elephant in the Room: Is Your Out-of-Distribution Detection Really Robust?.
Conclusion
The ROOD framework presented in this paper is a promising approach for addressing the challenge of OOD detection on imbalanced data distributions. By combining representation learning, anomaly detection, and adaptive thresholding, the framework demonstrates improved performance compared to existing methods.
The framework's ability to learn robust representations and effectively identify outliers in imbalanced datasets is a significant contribution to the field of machine learning. As machine learning models are increasingly deployed in real-world applications, the need for reliable OOD detection on diverse and imbalanced datasets will only continue to grow. The ROOD framework represents an important step forward in addressing this challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking Out-of-Distribution Detection on Imbalanced Data Distribution
Kai Liu, Zhihang Fu, Sheng Jin, Chao Chen, Ze Chen, Rongxin Jiang, Fan Zhou, Yaowu Chen, Jieping Ye
Detecting and rejecting unknown out-of-distribution (OOD) samples is critical for deployed neural networks to void unreliable predictions. In real-world scenarios, however, the efficacy of existing OOD detection methods is often impeded by the inherent imbalance of in-distribution (ID) data, which causes significant performance decline. Through statistical observations, we have identified two common challenges faced by different OOD detectors: misidentifying tail class ID samples as OOD, while erroneously predicting OOD samples as head class from ID. To explain this phenomenon, we introduce a generalized statistical framework, termed ImOOD, to formulate the OOD detection problem on imbalanced data distribution. Consequently, the theoretical analysis reveals that there exists a class-aware bias item between balanced and imbalanced OOD detection, which contributes to the performance gap. Building upon this finding, we present a unified training-time regularization technique to mitigate the bias and boost imbalanced OOD detectors across architecture designs. Our theoretically grounded method translates into consistent improvements on the representative CIFAR10-LT, CIFAR100-LT, and ImageNet-LT benchmarks against several state-of-the-art OOD detection approaches. Code will be made public soon.
Read more7/24/2024
0
Toward a Realistic Benchmark for Out-of-Distribution Detection
Pietro Recalcati, Fabio Garcea, Luca Piano, Fabrizio Lamberti, Lia Morra
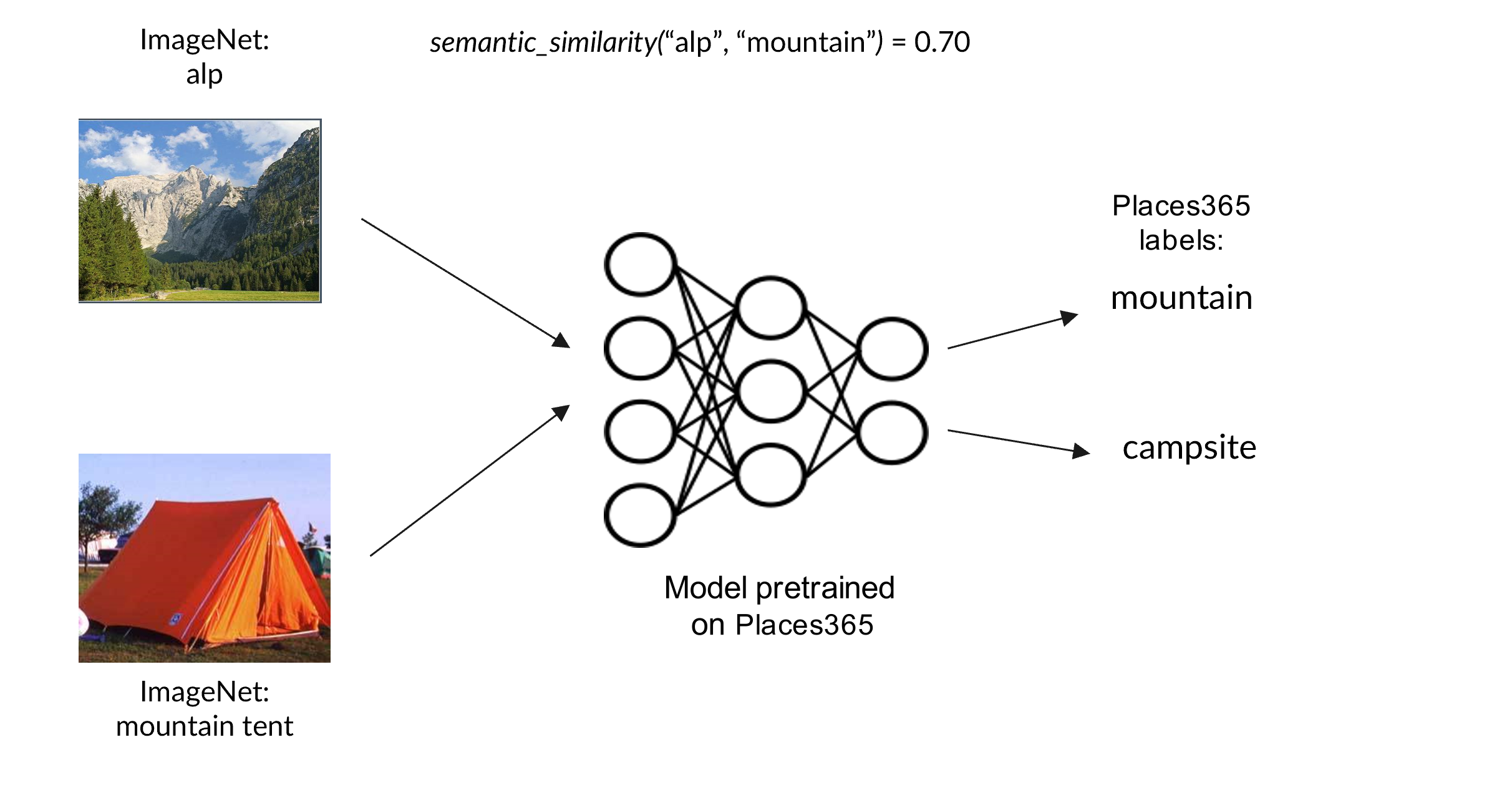
Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
Read more4/17/2024

0
Continual Unsupervised Out-of-Distribution Detection
Lars Doorenbos, Raphael Sznitman, Pablo M'arquez-Neila
Deep learning models excel when the data distribution during training aligns with testing data. Yet, their performance diminishes when faced with out-of-distribution (OOD) samples, leading to great interest in the field of OOD detection. Current approaches typically assume that OOD samples originate from an unconcentrated distribution complementary to the training distribution. While this assumption is appropriate in the traditional unsupervised OOD (U-OOD) setting, it proves inadequate when considering the place of deployment of the underlying deep learning model. To better reflect this real-world scenario, we introduce the novel setting of continual U-OOD detection. To tackle this new setting, we propose a method that starts from a U-OOD detector, which is agnostic to the OOD distribution, and slowly updates during deployment to account for the actual OOD distribution. Our method uses a new U-OOD scoring function that combines the Mahalanobis distance with a nearest-neighbor approach. Furthermore, we design a confidence-scaled few-shot OOD detector that outperforms previous methods. We show our method greatly improves upon strong baselines from related fields.
Read more6/5/2024

0
Long-Tailed Out-of-Distribution Detection: Prioritizing Attention to Tail
Yina He, Lei Peng, Yongcun Zhang, Juanjuan Weng, Zhiming Luo, Shaozi Li
Current out-of-distribution (OOD) detection methods typically assume balanced in-distribution (ID) data, while most real-world data follow a long-tailed distribution. Previous approaches to long-tailed OOD detection often involve balancing the ID data by reducing the semantics of head classes. However, this reduction can severely affect the classification accuracy of ID data. The main challenge of this task lies in the severe lack of features for tail classes, leading to confusion with OOD data. To tackle this issue, we introduce a novel Prioritizing Attention to Tail (PATT) method using augmentation instead of reduction. Our main intuition involves using a mixture of von Mises-Fisher (vMF) distributions to model the ID data and a temperature scaling module to boost the confidence of ID data. This enables us to generate infinite contrastive pairs, implicitly enhancing the semantics of ID classes while promoting differentiation between ID and OOD data. To further strengthen the detection of OOD data without compromising the classification performance of ID data, we propose feature calibration during the inference phase. By extracting an attention weight from the training set that prioritizes the tail classes and reduces the confidence in OOD data, we improve the OOD detection capability. Extensive experiments verified that our method outperforms the current state-of-the-art methods on various benchmarks.
Read more8/27/2024