Rethinking Sparse Lexical Representations for Image Retrieval in the Age of Rising Multi-Modal Large Language Models

0

Sign in to get full access
Overview
- Examines the use of sparse lexical representations for image retrieval in the context of rising multi-modal large language models (LLMs)
- Argues that the effectiveness of sparse lexical representations may be diminishing as LLMs become more prominent
- Proposes a rethinking of the role of sparse lexical representations for image retrieval
Plain English Explanation
In the past, image retrieval systems often relied on sparse lexical representations - ways of representing images using a small set of keywords or tags. This approach had its advantages, as it was relatively simple and efficient. However, with the rapid development of multi-modal large language models, the authors argue that the effectiveness of sparse lexical representations may be diminishing.
LLMs are powerful AI models that can understand and generate human-like text, and they are increasingly being trained on both textual and visual data. This allows them to learn rich, multi-modal representations that can capture the relationship between images and language in a more nuanced way than traditional sparse lexical representations.
The authors propose that as LLMs become more prominent, it may be necessary to rethink the role of sparse lexical representations for image retrieval. They suggest that LLMs could be leveraged to create more efficient and interpretable information retrieval systems that are better able to understand and respond to complex queries.
Technical Explanation
The paper examines the use of sparse lexical representations for image retrieval in the context of the rise of multi-modal large language models (LLMs). The authors argue that as LLMs become more prominent, the effectiveness of traditional sparse lexical representations may be diminishing.
Sparse lexical representations involve representing images using a small set of keywords or tags. This approach has advantages, such as efficiency and simplicity. However, the authors suggest that LLMs, which can learn rich multi-modal representations by training on both textual and visual data, may be better able to capture the nuanced relationships between images and language.
The paper proposes that as LLMs become more widely adopted, it may be necessary to rethink the role of sparse lexical representations for image retrieval. The authors suggest that LLMs could be leveraged to create more efficient and interpretable information retrieval systems that are better able to understand and respond to complex queries, potentially enhancing interactive image retrieval and improving cross-modal image retrieval.
Critical Analysis
The paper raises important points about the potential limitations of traditional sparse lexical representations for image retrieval in the age of rising multi-modal LLMs. The authors make a compelling case that as these powerful language models become more widespread, it may be necessary to explore alternative approaches that better leverage their ability to understand and reason about the relationships between images and text.
However, the paper does not provide a detailed empirical evaluation of the relative performance of sparse lexical representations and LLM-based approaches for image retrieval. More research would be needed to fully understand the tradeoffs and determine the most effective strategies moving forward.
Additionally, the paper does not address potential challenges or concerns around the use of LLMs for image retrieval, such as issues related to data bias, interpretability, or privacy.
Conclusion
This paper presents an interesting perspective on the role of sparse lexical representations for image retrieval in the context of the rising prominence of multi-modal large language models. The authors make a compelling case that as LLMs become more advanced, it may be necessary to rethink the use of traditional sparse lexical representations and explore alternative approaches that better leverage the capabilities of these powerful language models.
The proposed shift could have significant implications for the design of efficient and interpretable information retrieval systems, potentially leading to enhanced interactive image retrieval and improved cross-modal image retrieval. However, further research is needed to fully understand the tradeoffs and develop effective strategies for integrating LLMs into image retrieval systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking Sparse Lexical Representations for Image Retrieval in the Age of Rising Multi-Modal Large Language Models
Kengo Nakata, Daisuke Miyashita, Youyang Ng, Yasuto Hoshi, Jun Deguchi
In this paper, we rethink sparse lexical representations for image retrieval. By utilizing multi-modal large language models (M-LLMs) that support visual prompting, we can extract image features and convert them into textual data, enabling us to utilize efficient sparse retrieval algorithms employed in natural language processing for image retrieval tasks. To assist the LLM in extracting image features, we apply data augmentation techniques for key expansion and analyze the impact with a metric for relevance between images and textual data. We empirically show the superior precision and recall performance of our image retrieval method compared to conventional vision-language model-based methods on the MS-COCO, PASCAL VOC, and NUS-WIDE datasets in a keyword-based image retrieval scenario, where keywords serve as search queries. We also demonstrate that the retrieval performance can be improved by iteratively incorporating keywords into search queries.
Read more8/30/2024
🖼️
0
Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
Hongyi Zhu, Jia-Hong Huang, Stevan Rudinac, Evangelos Kanoulas
Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.
Read more4/30/2024
📊
0
Efficient and Interpretable Information Retrieval for Product Question Answering with Heterogeneous Data
Biplob Biswas, Rajiv Ramnath
Expansion-enhanced sparse lexical representation improves information retrieval (IR) by minimizing vocabulary mismatch problems during lexical matching. In this paper, we explore the potential of jointly learning dense semantic representation and combining it with the lexical one for ranking candidate information. We present a hybrid information retrieval mechanism that maximizes lexical and semantic matching while minimizing their shortcomings. Our architecture consists of dual hybrid encoders that independently encode queries and information elements. Each encoder jointly learns a dense semantic representation and a sparse lexical representation augmented by a learnable term expansion of the corresponding text through contrastive learning. We demonstrate the efficacy of our model in single-stage ranking of a benchmark product question-answering dataset containing the typical heterogeneous information available on online product pages. Our evaluation demonstrates that our hybrid approach outperforms independently trained retrievers by 10.95% (sparse) and 2.7% (dense) in MRR@5 score. Moreover, our model offers better interpretability and performs comparably to state-of-the-art cross encoders while reducing response time by 30% (latency) and cutting computational load by approximately 38% (FLOPs).
Read more5/24/2024
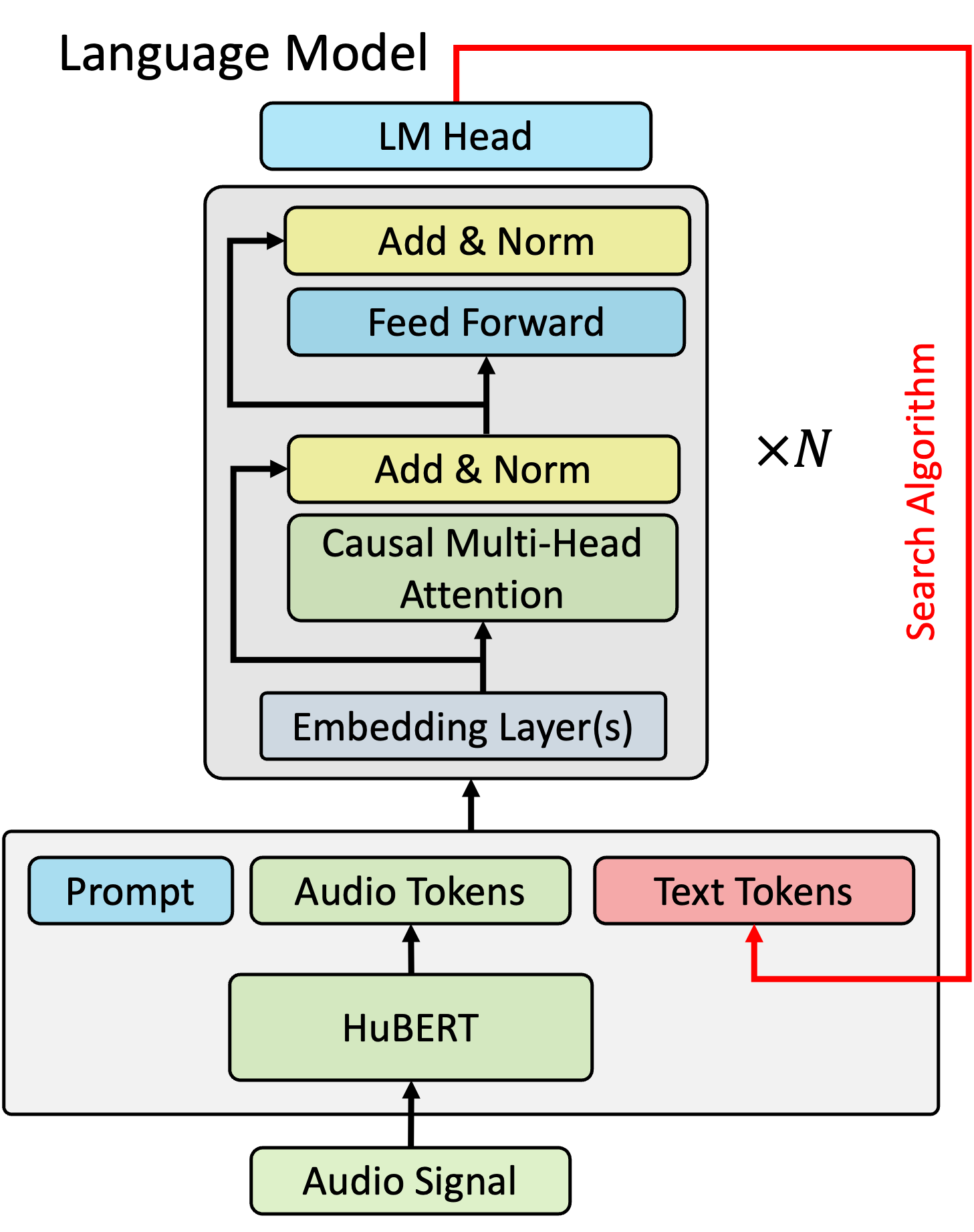
0
Multi-Modal Retrieval For Large Language Model Based Speech Recognition
Jari Kolehmainen, Aditya Gourav, Prashanth Gurunath Shivakumar, Yile Gu, Ankur Gandhe, Ariya Rastrow, Grant Strimel, Ivan Bulyko
Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.
Read more6/17/2024