Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
2404.18746
0
0
🖼️
Abstract
Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes an interactive image retrieval system that can refine search queries based on user feedback, improving the accuracy and recall of image search results.
- The system uses a vision language model (VLM) to enhance text-based queries, and a large language model (LLM) to denoise and refine the generated query expansions.
- The authors also curate a new dataset for evaluating image retrieval systems, adapting the MSR-VTT video dataset to the image retrieval task.
Plain English Explanation
Image search is a crucial task in multimedia and computer vision, with applications ranging from internet search to medical diagnostics. Conventional image search systems typically accept text or visual queries and retrieve the most relevant results from a database. However, these methods often rely on a single-turn process, which can lead to inaccuracies and limited recall due to challenges like vocabulary mismatch and the semantic gap.
To address these issues, the researchers have developed an interactive image retrieval system that allows users to refine their queries based on relevance feedback in a multi-turn setting. This system incorporates a VLM-based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Additionally, the researchers introduce an LLM-based denoiser to refine the text-based query expansions, mitigating inaccuracies in the image descriptions generated by the captioning model.
To evaluate their system, the researchers curated a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, providing multiple relevant ground truth images for each query. Through comprehensive experiments, they validated the effectiveness of their proposed system, achieving state-of-the-art performance with a notable 10% improvement in terms of recall compared to baseline methods.
Technical Explanation
The researchers propose an interactive image retrieval system that refines search queries based on user relevance feedback. This system incorporates a VLM-based image captioner to enhance the quality of text-based queries, generating more informative queries with each iteration. Additionally, the researchers introduce an LLM-based denoiser to refine the text-based query expansions, mitigating inaccuracies in the image descriptions generated by the captioning model.
To evaluate their system, the researchers curated a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task. This dataset offers multiple relevant ground truth images for each query, providing a more comprehensive evaluation of the system's performance.
Through comprehensive experiments, the researchers validated the effectiveness of their proposed system, achieving state-of-the-art performance with a notable 10% improvement in terms of recall compared to baseline methods.
Critical Analysis
The paper presents a well-designed interactive image retrieval system that addresses some of the key challenges in conventional image search, such as vocabulary mismatch and the semantic gap. The integration of the VLM-based image captioner and the LLM-based denoiser is a promising approach to enhance the quality of text-based queries and mitigate inaccuracies in the generated query expansions.
However, the authors do not discuss the computational complexity or real-time performance of their system, which could be important considerations for practical applications. Additionally, the proposed dataset, while offering a more comprehensive evaluation, may not fully represent the diversity and complexity of real-world image search scenarios.
Further research could explore the robustness of the system to noisy or ambiguous user feedback, as well as its scalability to larger and more diverse image databases. Investigating the transferability of the system to different domains, such as enhancing robot explanation capabilities, could also be a fruitful avenue for future work.
Conclusion
The proposed interactive image retrieval system represents a significant advancement in addressing the limitations of conventional image search methods. By incorporating VLM and LLM technologies, the system can refine queries based on user feedback, leading to more accurate and comprehensive search results. The curated dataset and thorough experimental validation further strengthen the contributions of this work, which has the potential to impact a wide range of applications in multimedia and computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Harnessing the Power of Large Vision Language Models for Synthetic Image Detection
Mamadou Keita, Wassim Hamidouche, Hassen Bougueffa, Abdenour Hadid, Abdelmalik Taleb-Ahmed
0
0
In recent years, the emergence of models capable of generating images from text has attracted considerable interest, offering the possibility of creating realistic images from text descriptions. Yet these advances have also raised concerns about the potential misuse of these images, including the creation of misleading content such as fake news and propaganda. This study investigates the effectiveness of using advanced vision-language models (VLMs) for synthetic image identification. Specifically, the focus is on tuning state-of-the-art image captioning models for synthetic image detection. By harnessing the robust understanding capabilities of large VLMs, the aim is to distinguish authentic images from synthetic images produced by diffusion-based models. This study contributes to the advancement of synthetic image detection by exploiting the capabilities of visual language models such as BLIP-2 and ViTGPT2. By tailoring image captioning models, we address the challenges associated with the potential misuse of synthetic images in real-world applications. Results described in this paper highlight the promising role of VLMs in the field of synthetic image detection, outperforming conventional image-based detection techniques. Code and models can be found at https://github.com/Mamadou-Keita/VLM-DETECT.
4/4/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
💬
Redefining Information Retrieval of Structured Database via Large Language Models
Mingzhu Wang, Yuzhe Zhang, Qihang Zhao, Juanyi Yang, Hong Zhang
0
0
Retrieval augmentation is critical when Language Models (LMs) exploit non-parametric knowledge related to the query through external knowledge bases before reasoning. The retrieved information is incorporated into LMs as context alongside the query, enhancing the reliability of responses towards factual questions. Prior researches in retrieval augmentation typically follow a retriever-generator paradigm. In this context, traditional retrievers encounter challenges in precisely and seamlessly extracting query-relevant information from knowledge bases. To address this issue, this paper introduces a novel retrieval augmentation framework called ChatLR that primarily employs the powerful semantic understanding ability of Large Language Models (LLMs) as retrievers to achieve precise and concise information retrieval. Additionally, we construct an LLM-based search and question answering system tailored for the financial domain by fine-tuning LLM on two tasks including Text2API and API-ID recognition. Experimental results demonstrate the effectiveness of ChatLR in addressing user queries, achieving an overall information retrieval accuracy exceeding 98.8%.
5/10/2024
Large Language Model Informed Patent Image Retrieval
Hao-Cheng Lo, Jung-Mei Chu, Jieh Hsiang, Chun-Chieh Cho
0
0
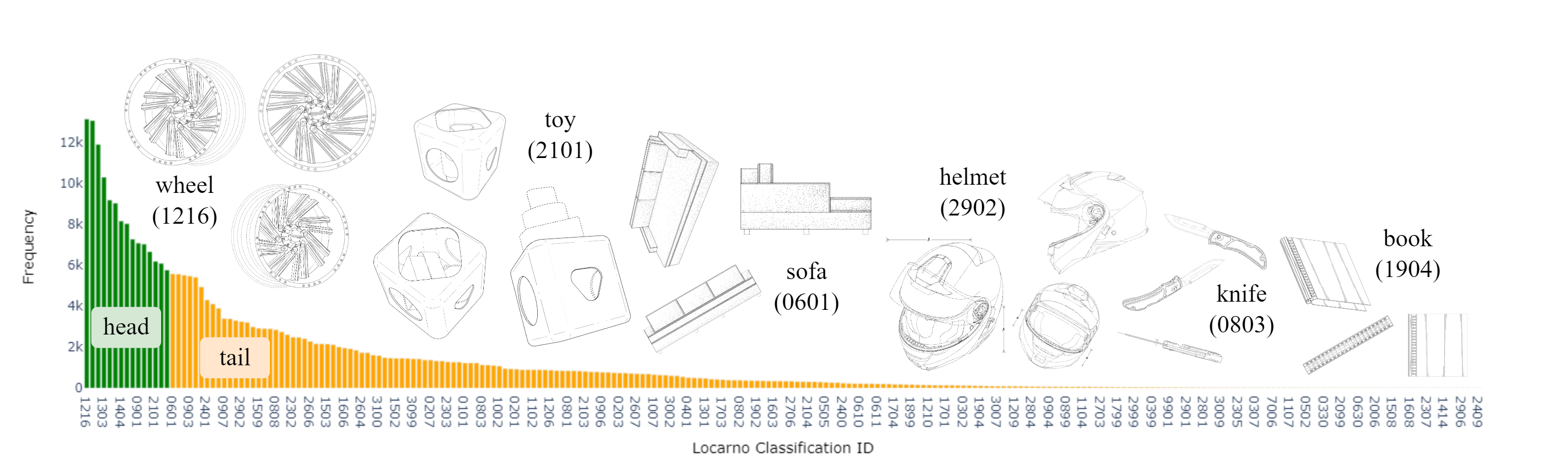
In patent prosecution, image-based retrieval systems for identifying similarities between current patent images and prior art are pivotal to ensure the novelty and non-obviousness of patent applications. Despite their growing popularity in recent years, existing attempts, while effective at recognizing images within the same patent, fail to deliver practical value due to their limited generalizability in retrieving relevant prior art. Moreover, this task inherently involves the challenges posed by the abstract visual features of patent images, the skewed distribution of image classifications, and the semantic information of image descriptions. Therefore, we propose a language-informed, distribution-aware multimodal approach to patent image feature learning, which enriches the semantic understanding of patent image by integrating Large Language Models and improves the performance of underrepresented classes with our proposed distribution-aware contrastive losses. Extensive experiments on DeepPatent2 dataset show that our proposed method achieves state-of-the-art or comparable performance in image-based patent retrieval with mAP +53.3%, Recall@10 +41.8%, and MRR@10 +51.9%. Furthermore, through an in-depth user analysis, we explore our model in aiding patent professionals in their image retrieval efforts, highlighting the model's real-world applicability and effectiveness.
5/1/2024