Efficient and Interpretable Information Retrieval for Product Question Answering with Heterogeneous Data

0
📊
Sign in to get full access
Overview
- This paper explores a hybrid approach to information retrieval (IR) that combines dense semantic representation and sparse lexical representation to improve performance.
- The proposed model consists of dual hybrid encoders that jointly learn a dense semantic representation and an augmented sparse lexical representation for queries and information elements.
- The model aims to maximize lexical and semantic matching while minimizing their individual shortcomings, leading to improved ranking of candidate information.
Plain English Explanation
When you search for information online, the search engine tries to match the words in your query (the lexical representation) with the words on web pages (the lexical representation of the content). However, this can sometimes fail because the words you use may not exactly match the words on the page, even if the content is relevant. This is known as the vocabulary mismatch problem.
To address this, the researchers in this paper developed a new approach that combines the traditional lexical matching with a more advanced "semantic" matching. The semantic matching looks at the meaning of the words, rather than just the words themselves. This allows the search engine to better understand the intent behind the query and find relevant information, even if the wording doesn't match exactly.
The key to this approach is the use of dual hybrid encoders. These are machine learning models that can independently analyze the query and the information elements (like web pages or product descriptions) to learn both the lexical representation and the semantic representation. By combining these two types of representations, the model can perform more accurate and relevant information retrieval.
Technical Explanation
The proposed hybrid IR mechanism consists of two main components:
-
Dual Hybrid Encoders: The model has separate encoders for the query and the information elements (e.g., product descriptions). Each encoder jointly learns a dense semantic representation and a sparse lexical representation that is augmented by a learnable term expansion.
-
Contrastive Learning: The model uses contrastive learning to optimize the representations, ensuring that semantically similar queries and information elements are brought closer together in the representation space, while dissimilar ones are pushed apart.
The sparse lexical representation is designed to minimize vocabulary mismatch problems during lexical matching, while the dense semantic representation captures the underlying meaning of the text. By combining these two representations, the model can effectively utilize both lexical and semantic information for ranking candidate information.
The researchers evaluate their model on a benchmark product question-answering dataset, which contains the heterogeneous information typically found on online product pages. The results show that the hybrid approach outperforms independently trained retrievers by a significant margin in terms of ranking performance (MRR@5 score). Additionally, the model offers better interpretability and comparable performance to state-of-the-art cross-encoders, while reducing response time and computational load.
Critical Analysis
The paper presents a compelling approach to improving information retrieval by leveraging both lexical and semantic information. The use of dual hybrid encoders and contrastive learning is a well-designed solution to the vocabulary mismatch problem that often plagues traditional IR systems.
However, the paper does not address the potential challenges of scaling this approach to large-scale, real-world IR scenarios. The evaluation is limited to a single dataset, and it would be valuable to see how the model performs on a more diverse range of information retrieval tasks and datasets, including enterprise knowledge bases.
Additionally, the paper could have provided more details on the specific mechanisms and architectural choices that enable the model to achieve its performance advantages, such as the details of the learnable term expansion and the trade-offs between lexical and semantic matching. This would help readers better understand the nuances of the approach and its potential limitations.
Overall, the paper presents a promising hybrid IR mechanism that demonstrates the potential benefits of combining lexical and semantic representations. Further research and evaluation on larger and more diverse datasets could help validate the generalizability and practical applicability of this approach.
Conclusion
This paper explores a novel hybrid information retrieval mechanism that combines dense semantic representation and sparse lexical representation to improve ranking performance. The key innovation is the use of dual hybrid encoders that jointly learn both types of representations, leveraging contrastive learning to optimize the representations for effective retrieval.
The results show that this hybrid approach outperforms independently trained retrievers and offers better interpretability, while also reducing response time and computational load compared to state-of-the-art cross-encoders. This work highlights the potential benefits of integrating lexical and semantic information for more effective and efficient information retrieval, which could have significant implications for a wide range of applications, from online search to enterprise knowledge management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Efficient and Interpretable Information Retrieval for Product Question Answering with Heterogeneous Data
Biplob Biswas, Rajiv Ramnath
Expansion-enhanced sparse lexical representation improves information retrieval (IR) by minimizing vocabulary mismatch problems during lexical matching. In this paper, we explore the potential of jointly learning dense semantic representation and combining it with the lexical one for ranking candidate information. We present a hybrid information retrieval mechanism that maximizes lexical and semantic matching while minimizing their shortcomings. Our architecture consists of dual hybrid encoders that independently encode queries and information elements. Each encoder jointly learns a dense semantic representation and a sparse lexical representation augmented by a learnable term expansion of the corresponding text through contrastive learning. We demonstrate the efficacy of our model in single-stage ranking of a benchmark product question-answering dataset containing the typical heterogeneous information available on online product pages. Our evaluation demonstrates that our hybrid approach outperforms independently trained retrievers by 10.95% (sparse) and 2.7% (dense) in MRR@5 score. Moreover, our model offers better interpretability and performs comparably to state-of-the-art cross encoders while reducing response time by 30% (latency) and cutting computational load by approximately 38% (FLOPs).
Read more5/24/2024

0
Rethinking Sparse Lexical Representations for Image Retrieval in the Age of Rising Multi-Modal Large Language Models
Kengo Nakata, Daisuke Miyashita, Youyang Ng, Yasuto Hoshi, Jun Deguchi
In this paper, we rethink sparse lexical representations for image retrieval. By utilizing multi-modal large language models (M-LLMs) that support visual prompting, we can extract image features and convert them into textual data, enabling us to utilize efficient sparse retrieval algorithms employed in natural language processing for image retrieval tasks. To assist the LLM in extracting image features, we apply data augmentation techniques for key expansion and analyze the impact with a metric for relevance between images and textual data. We empirically show the superior precision and recall performance of our image retrieval method compared to conventional vision-language model-based methods on the MS-COCO, PASCAL VOC, and NUS-WIDE datasets in a keyword-based image retrieval scenario, where keywords serve as search queries. We also demonstrate that the retrieval performance can be improved by iteratively incorporating keywords into search queries.
Read more8/30/2024
1
Information Retrieval with Entity Linking
Dahlia Shehata
Despite the advantages of their low-resource settings, traditional sparse retrievers depend on exact matching approaches between high-dimensional bag-of-words (BoW) representations of both the queries and the collection. As a result, retrieval performance is restricted by semantic discrepancies and vocabulary gaps. On the other hand, transformer-based dense retrievers introduce significant improvements in information retrieval tasks by exploiting low-dimensional contextualized representations of the corpus. While dense retrievers are known for their relative effectiveness, they suffer from lower efficiency and lack of generalization issues, when compared to sparse retrievers. For a lightweight retrieval task, high computational resources and time consumption are major barriers encouraging the renunciation of dense models despite potential gains. In this work, I propose boosting the performance of sparse retrievers by expanding both the queries and the documents with linked entities in two formats for the entity names: 1) explicit and 2) hashed. A zero-shot end-to-end dense entity linking system is employed for entity recognition and disambiguation to augment the corpus. By leveraging the advanced entity linking methods, I believe that the effectiveness gap between sparse and dense retrievers can be narrowed. Experiments are conducted on the MS MARCO passage dataset using the original qrel set, the re-ranked qrels favoured by MonoT5 and the latter set further re-ranked by DuoT5. Since I am concerned with the early stage retrieval in cascaded ranking architectures of large information retrieval systems, the results are evaluated using recall@1000. The suggested approach is also capable of retrieving documents for query subsets judged to be particularly difficult in prior work.
Read more4/16/2024
0
Multi-word Term Embeddings Improve Lexical Product Retrieval
Viktor Shcherbakov, Fedor Krasnov
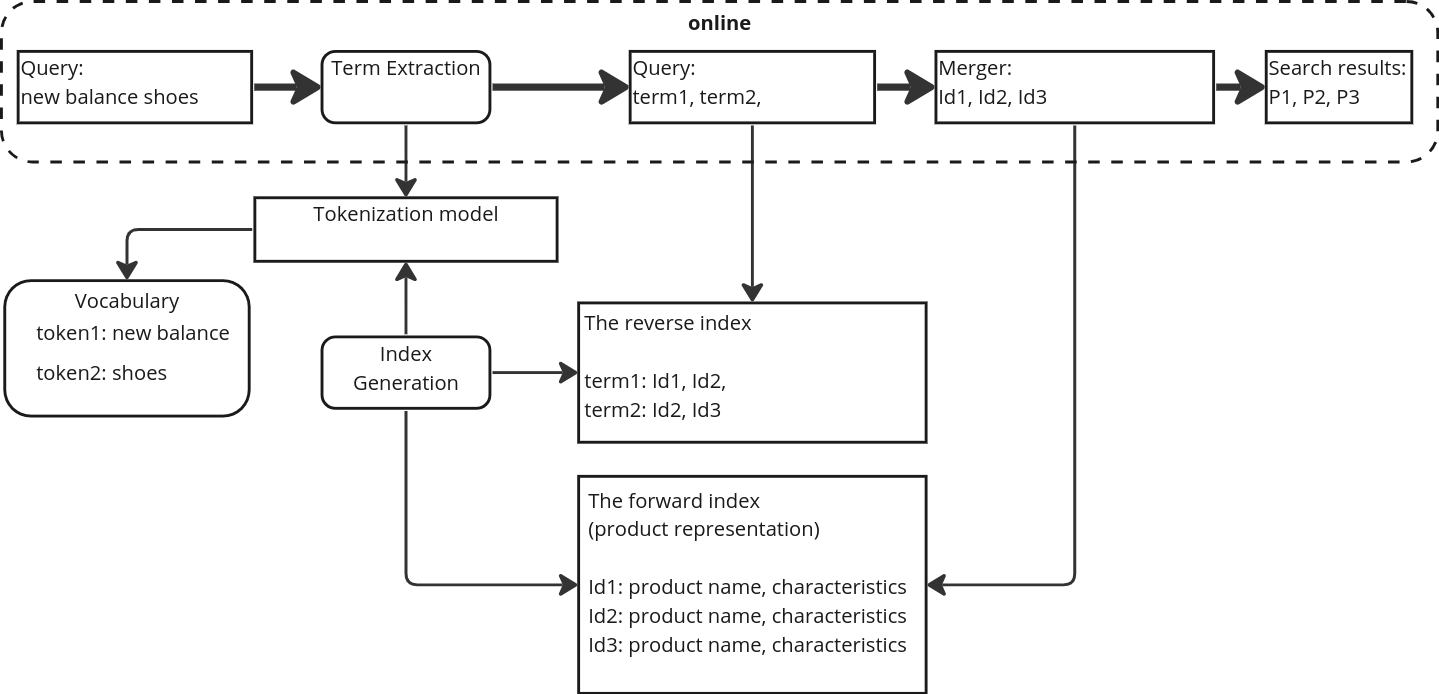
Product search is uniquely different from search for documents, Internet resources or vacancies, therefore it requires the development of specialized search systems. The present work describes the H1 embdedding model, designed for an offline term indexing of product descriptions at e-commerce platforms. The model is compared to other state-of-the-art (SoTA) embedding models within a framework of hybrid product search system that incorporates the advantages of lexical methods for product retrieval and semantic embedding-based methods. We propose an approach to building semantically rich term vocabularies for search indexes. Compared to other production semantic models, H1 paired with the proposed approach stands out due to its ability to process multi-word product terms as one token. As an example, for search queries new balance shoes, gloria jeans kids wear brand entity will be represented as one token - new balance, gloria jeans. This results in an increased precision of the system without affecting the recall. The hybrid search system with proposed model scores mAP@12 = 56.1% and R@1k = 86.6% on the WANDS public dataset, beating other SoTA analogues.
Read more6/4/2024