Retraining with Predicted Hard Labels Provably Increases Model Accuracy

0

Sign in to get full access
Overview
- This paper proposes a novel method for improving model accuracy by retraining the model with predicted hard labels.
- The authors provide theoretical guarantees showing that this approach can provably increase model accuracy under certain conditions.
- The key idea is to use the model's own predictions as "hard" labels to retrain the model, rather than relying on the original noisy or uncertain labels.
Plain English Explanation
The paper describes a new way to improve the accuracy of machine learning models by retraining the model with its own predicted labels. The authors show that this approach can actually increase the model's accuracy, as long as certain conditions are met.
The main issue the paper is trying to address is that the original training data may have noisy or uncertain labels, which can limit a model's performance. To get around this, the idea is to let the model make its own "best guess" predictions on the training data, and then use those predicted labels to retrain the model.
This may sound counterintuitive - why would the model's own imperfect predictions be better than the original labels? The key insight is that even if the model's individual predictions have some errors, the overall patterns it learns from its own predictions can be more accurate than the noisy original labels.
The paper provides mathematical proofs to show that under certain assumptions, this "self-supervised" retraining approach can provably increase the model's accuracy compared to the original training. This could be a useful technique for improving models with noisy or subjective labels, or for developing more robust and fair machine learning systems.
Technical Explanation
The core idea of the paper is to retrain a model using its own predictions as "hard" labels, rather than the original noisy or uncertain training labels. Specifically, the authors propose the following steps:
- Train an initial model on the original training data.
- Use the trained model to make predictions on the training data, obtaining a set of "predicted hard labels".
- Retrain the model from scratch using the training data paired with the predicted hard labels.
The key technical insight is that even if the model's individual predictions have some errors, the overall patterns it learns from its own predictions can be more accurate than the noisy original labels. The authors provide theoretical guarantees showing that under certain conditions, this approach can provably increase the model's accuracy compared to training on the original labels.
The paper analyzes this approach both theoretically and empirically. Theoretically, they show that as long as the model is sufficiently expressive and the original labels are sufficiently noisy, retraining with the predicted hard labels will outperform training on the original labels. Empirically, they demonstrate the effectiveness of this approach on several benchmark datasets.
This technique could be particularly useful for improving models trained on high-dimensional or noisy data, or for developing more robust and fair machine learning systems that can handle dataset biases and imperfect labels.
Critical Analysis
The paper presents a compelling approach for improving model accuracy by retraining with predicted hard labels. The theoretical guarantees and empirical results provide a strong case for the effectiveness of this technique.
However, the paper does make some assumptions that could limit the generalizability of the approach. For example, it assumes the model is sufficiently expressive to capture the underlying patterns in the data, and that the original labels are sufficiently noisy. In practice, these conditions may not always hold, and the model's own predictions could be biased or inaccurate in ways that negatively impact the retraining process.
Additionally, the paper does not explore the effects of this approach on model robustness or generalization to out-of-distribution data. It's possible that retraining with predicted hard labels could lead to overfitting or reduce the model's ability to handle distributional shift.
Further research would be valuable to understand the broader implications and limitations of this technique, such as its interaction with data augmentation and last-layer retraining approaches, and how it performs in the presence of more complex label noise or dataset biases.
Conclusion
This paper presents a novel and promising approach for improving machine learning model accuracy by retraining with predicted hard labels. The authors provide strong theoretical and empirical support for the effectiveness of this technique, which could be particularly useful for dealing with noisy or uncertain training data and developing more robust and fair machine learning systems.
While the approach has some limitations and assumptions that warrant further investigation, the core idea of leveraging a model's own predictions to improve its performance is a clever and promising direction for machine learning research. As the field continues to grapple with the challenges of dataset biases, label noise, and model robustness, techniques like the one proposed in this paper could play an important role in advancing the state of the art.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Retraining with Predicted Hard Labels Provably Increases Model Accuracy
Rudrajit Das, Inderjit S. Dhillon, Alessandro Epasto, Adel Javanmard, Jieming Mao, Vahab Mirrokni, Sujay Sanghavi, Peilin Zhong
The performance of a model trained with textit{noisy labels} is often improved by simply textit{retraining} the model with its own predicted textit{hard} labels (i.e., $1$/$0$ labels). Yet, a detailed theoretical characterization of this phenomenon is lacking. In this paper, we theoretically analyze retraining in a linearly separable setting with randomly corrupted labels given to us and prove that retraining can improve the population accuracy obtained by initially training with the given (noisy) labels. To the best of our knowledge, this is the first such theoretical result. Retraining finds application in improving training with label differential privacy (DP) which involves training with noisy labels. We empirically show that retraining selectively on the samples for which the predicted label matches the given label significantly improves label DP training at textit{no extra privacy cost}; we call this textit{consensus-based retraining}. For e.g., when training ResNet-18 on CIFAR-100 with $epsilon=3$ label DP, we obtain $6.4%$ improvement in accuracy with consensus-based retraining.
Read more6/18/2024
🤯
0
High-dimensional Learning with Noisy Labels
Aymane El Firdoussi, Mohamed El Amine Seddik
This paper provides theoretical insights into high-dimensional binary classification with class-conditional noisy labels. Specifically, we study the behavior of a linear classifier with a label noisiness aware loss function, when both the dimension of data $p$ and the sample size $n$ are large and comparable. Relying on random matrix theory by supposing a Gaussian mixture data model, the performance of the linear classifier when $p,nto infty$ is shown to converge towards a limit, involving scalar statistics of the data. Importantly, our findings show that the low-dimensional intuitions to handle label noise do not hold in high-dimension, in the sense that the optimal classifier in low-dimension dramatically fails in high-dimension. Based on our derivations, we design an optimized method that is shown to be provably more efficient in handling noisy labels in high dimensions. Our theoretical conclusions are further confirmed by experiments on real datasets, where we show that our optimized approach outperforms the considered baselines.
Read more5/24/2024
🌀
0
Noise Correction on Subjective Datasets
Uthman Jinadu, Yi Ding
Incorporating every annotator's perspective is crucial for unbiased data modeling. Annotator fatigue and changing opinions over time can distort dataset annotations. To combat this, we propose to learn a more accurate representation of diverse opinions by utilizing multitask learning in conjunction with loss-based label correction. We show that using our novel formulation, we can cleanly separate agreeing and disagreeing annotations. Furthermore, this method provides a controllable way to encourage or discourage disagreement. We demonstrate that this modification can improve prediction performance in a single or multi-annotator setting. Lastly, we show that this method remains robust to additional label noise that is applied to subjective data.
Read more6/5/2024
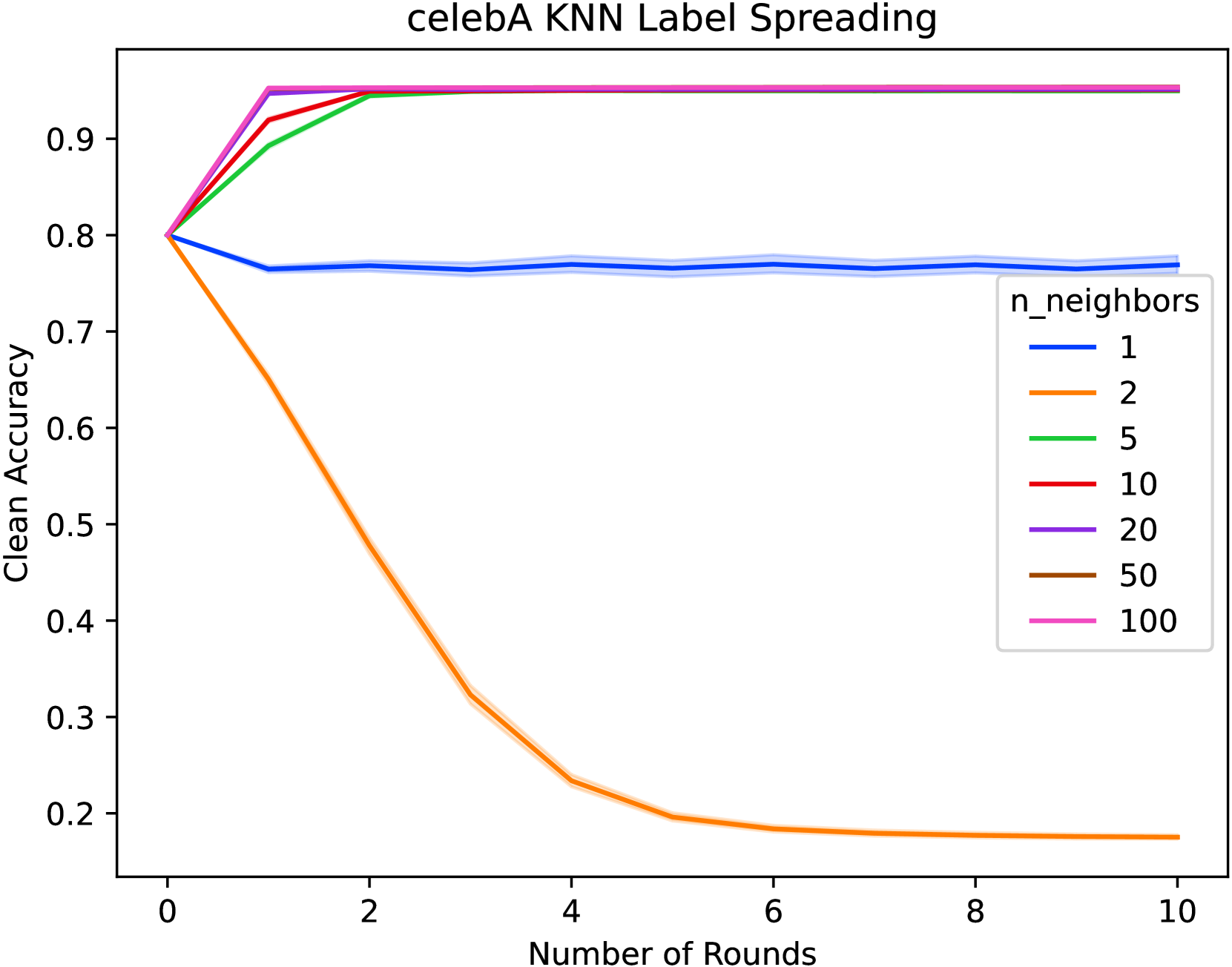
0
Label Noise Robustness for Domain-Agnostic Fair Corrections via Nearest Neighbors Label Spreading
Nathan Stromberg, Rohan Ayyagari, Sanmi Koyejo, Richard Nock, Lalitha Sankar
Last-layer retraining methods have emerged as an efficient framework for correcting existing base models. Within this framework, several methods have been proposed to deal with correcting models for subgroup fairness with and without group membership information. Importantly, prior work has demonstrated that many methods are susceptible to noisy labels. To this end, we propose a drop-in correction for label noise in last-layer retraining, and demonstrate that it achieves state-of-the-art worst-group accuracy for a broad range of symmetric label noise and across a wide variety of datasets exhibiting spurious correlations. Our proposed approach uses label spreading on a latent nearest neighbors graph and has minimal computational overhead compared to existing methods.
Read more6/17/2024