Revealing the Dark Secrets of Extremely Large Kernel ConvNets on Robustness

0
Sign in to get full access
Overview
- This paper explores the robustness of extremely large kernel Convolutional Neural Networks (ConvNets) and reveals some of their "dark secrets" that impact their performance.
- The research examines the influence of kernel size on model robustness, as well as the tradeoffs between robustness and accuracy.
- The authors propose a new network architecture, Extremely Large Kernel ConvNet (XLKC), which uses very large kernel sizes to improve robustness without sacrificing accuracy.
Plain English Explanation
Convolutional Neural Networks (ConvNets) are a type of machine learning model commonly used for image recognition tasks. These models use a series of convolutional layers to extract features from images. The size of the "kernels" (or filters) used in these convolutional layers can have a significant impact on the model's performance.
This paper investigates the use of extremely large kernel sizes in ConvNets and how they affect the model's robustness, which is the ability to perform well even when the input data is slightly changed or corrupted. The researchers found that using very large kernel sizes can indeed improve the robustness of these models, but it can also come at the cost of overall accuracy.
To address this tradeoff, the researchers developed a new network architecture called the Extremely Large Kernel ConvNet (XLKC). This model uses very large kernels to boost robustness, but it also incorporates other techniques to maintain high accuracy without sacrificing too much performance.
Technical Explanation
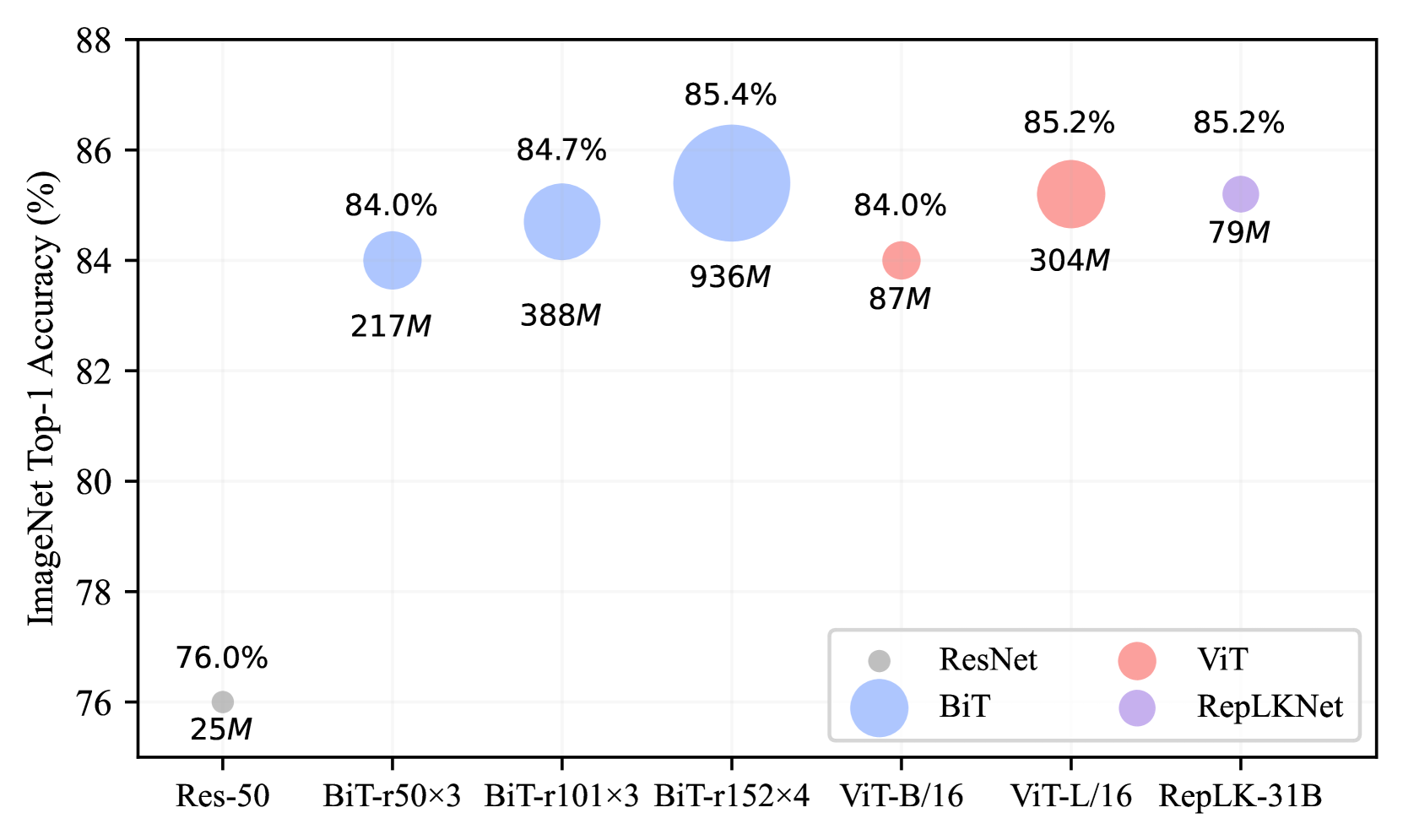
The paper presents a detailed analysis of the impact of kernel size on the robustness of ConvNets. The researchers conducted experiments using a range of kernel sizes, from 3x3 up to 101x101, and evaluated the models' performance on various benchmark datasets and adversarial attack scenarios.
The results show that as the kernel size increases, the model's robustness to different types of image corruption and adversarial attacks also improves. However, this increase in robustness comes with a corresponding decrease in the model's overall accuracy on clean (non-corrupted) images.
To address this tradeoff, the authors propose the Extremely Large Kernel ConvNet (XLKC) architecture. XLKC uses very large kernels (up to 101x101) in the early convolutional layers to capture a wider range of spatial features, which enhances robustness. In the later layers, the model uses smaller kernels to maintain high accuracy on clean images.
The researchers evaluate the XLKC model on several standard benchmarks and demonstrate that it can achieve state-of-the-art robustness without sacrificing too much clean-image accuracy compared to other large-kernel ConvNet models.
Critical Analysis
The paper provides a comprehensive analysis of the impact of kernel size on the robustness of ConvNets, which is an important and timely topic in the field of machine learning. The authors' exploration of the tradeoffs between robustness and accuracy, and their proposed XLKC architecture, offer valuable insights for researchers and practitioners working on building more robust and reliable deep learning models.
However, the paper does not fully address the computational and memory requirements of using extremely large kernels, which could be a significant limitation in practice, especially for real-time applications or resource-constrained environments. The authors mention this as a potential area for further research, but more detailed analysis and discussion of the practical implications would be helpful.
Additionally, the paper focuses primarily on image classification tasks and does not explore the impact of kernel size on other computer vision problems, such as object detection or semantic segmentation. Expanding the research to a wider range of tasks and domains could provide a more comprehensive understanding of the generalizability of the findings.
Conclusion
This paper makes an important contribution to the understanding of the relationship between kernel size, robustness, and accuracy in ConvNets. The authors' in-depth analysis and the proposed XLKC architecture demonstrate the potential for using extremely large kernels to enhance model robustness without sacrificing too much clean-image performance.
The insights from this research could inform the design of more robust and reliable deep learning models, which is crucial for the deployment of these technologies in real-world applications, especially in safety-critical domains. Further research is needed to address the practical limitations and explore the broader applications of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revealing the Dark Secrets of Extremely Large Kernel ConvNets on Robustness
Honghao Chen, Yurong Zhang, Xiaokun Feng, Xiangxiang Chu, Kaiqi Huang
Robustness is a vital aspect to consider when deploying deep learning models into the wild. Numerous studies have been dedicated to the study of the robustness of vision transformers (ViTs), which have dominated as the mainstream backbone choice for vision tasks since the dawn of 2020s. Recently, some large kernel convnets make a comeback with impressive performance and efficiency. However, it still remains unclear whether large kernel networks are robust and the attribution of their robustness. In this paper, we first conduct a comprehensive evaluation of large kernel convnets' robustness and their differences from typical small kernel counterparts and ViTs on six diverse robustness benchmark datasets. Then to analyze the underlying factors behind their strong robustness, we design experiments from both quantitative and qualitative perspectives to reveal large kernel convnets' intriguing properties that are completely different from typical convnets. Our experiments demonstrate for the first time that pure CNNs can achieve exceptional robustness comparable or even superior to that of ViTs. Our analysis on occlusion invariance, kernel attention patterns and frequency characteristics provide novel insights into the source of robustness.
Read more7/15/2024

0
Query-Efficient Hard-Label Black-Box Attack against Vision Transformers
Chao Zhou, Xiaowen Shi, Yuan-Gen Wang
Recent studies have revealed that vision transformers (ViTs) face similar security risks from adversarial attacks as deep convolutional neural networks (CNNs). However, directly applying attack methodology on CNNs to ViTs has been demonstrated to be ineffective since the ViTs typically work on patch-wise encoding. This article explores the vulnerability of ViTs against adversarial attacks under a black-box scenario, and proposes a novel query-efficient hard-label adversarial attack method called AdvViT. Specifically, considering that ViTs are highly sensitive to patch modification, we propose to optimize the adversarial perturbation on the individual patches. To reduce the dimension of perturbation search space, we modify only a handful of low-frequency components of each patch. Moreover, we design a weight mask matrix for all patches to further optimize the perturbation on different regions of a whole image. We test six mainstream ViT backbones on the ImageNet-1k dataset. Experimental results show that compared with the state-of-the-art attacks on CNNs, our AdvViT achieves much lower $L_2$-norm distortion under the same query budget, sufficiently validating the vulnerability of ViTs against adversarial attacks.
Read more7/2/2024

0
GenFormer -- Generated Images are All You Need to Improve Robustness of Transformers on Small Datasets
Sven Oehri, Nikolas Ebert, Ahmed Abdullah, Didier Stricker, Oliver Wasenmuller
Recent studies showcase the competitive accuracy of Vision Transformers (ViTs) in relation to Convolutional Neural Networks (CNNs), along with their remarkable robustness. However, ViTs demand a large amount of data to achieve adequate performance, which makes their application to small datasets challenging, falling behind CNNs. To overcome this, we propose GenFormer, a data augmentation strategy utilizing generated images, thereby improving transformer accuracy and robustness on small-scale image classification tasks. In our comprehensive evaluation we propose Tiny ImageNetV2, -R, and -A as new test set variants of Tiny ImageNet by transferring established ImageNet generalization and robustness benchmarks to the small-scale data domain. Similarly, we introduce MedMNIST-C and EuroSAT-C as corrupted test set variants of established fine-grained datasets in the medical and aerial domain. Through a series of experiments conducted on small datasets of various domains, including Tiny ImageNet, CIFAR, EuroSAT and MedMNIST datasets, we demonstrate the synergistic power of our method, in particular when combined with common train and test time augmentations, knowledge distillation, and architectural design choices. Additionally, we prove the effectiveness of our approach under challenging conditions with limited training data, demonstrating significant improvements in both accuracy and robustness, bridging the gap between CNNs and ViTs in the small-scale dataset domain.
Read more8/28/2024

0
Multi-Attribute Vision Transformers are Efficient and Robust Learners
Hanan Gani, Nada Saadi, Noor Hussein, Karthik Nandakumar
Since their inception, Vision Transformers (ViTs) have emerged as a compelling alternative to Convolutional Neural Networks (CNNs) across a wide spectrum of tasks. ViTs exhibit notable characteristics, including global attention, resilience against occlusions, and adaptability to distribution shifts. One underexplored aspect of ViTs is their potential for multi-attribute learning, referring to their ability to simultaneously grasp multiple attribute-related tasks. In this paper, we delve into the multi-attribute learning capability of ViTs, presenting a straightforward yet effective strategy for training various attributes through a single ViT network as distinct tasks. We assess the resilience of multi-attribute ViTs against adversarial attacks and compare their performance against ViTs designed for single attributes. Moreover, we further evaluate the robustness of multi-attribute ViTs against a recent transformer based attack called Patch-Fool. Our empirical findings on the CelebA dataset provide validation for our assertion. Our code is available at https://github.com/hananshafi/MTL-ViT
Read more7/22/2024