Multi-Attribute Vision Transformers are Efficient and Robust Learners

0

Sign in to get full access
Overview
- This paper introduces Multi-Attribute Vision Transformers (MAVTs), a novel architecture that combines the strengths of Vision Transformers and multi-task learning.
- MAVTs are shown to be efficient and robust learners, outperforming previous state-of-the-art models on a range of vision tasks.
- The key innovations include a flexible multi-head attention mechanism and a multi-task learning approach that allows the model to learn multiple attributes simultaneously.
Plain English Explanation
The paper describes a new type of machine learning model called Multi-Attribute Vision Transformers (MAVTs). These models are designed to be good at learning and understanding various aspects or "attributes" of images, rather than just focusing on a single task.
The core idea is that by training the model to recognize multiple attributes at the same time (like object detection, segmentation, and classification), it can become more efficient and robust than models that only learn a single task. The paper shows that MAVTs outperform previous state-of-the-art models on a variety of vision-related benchmarks.
The key technical innovations include a flexible attention mechanism that allows the model to focus on the most relevant parts of an image for each attribute, as well as a training approach that encourages the model to learn the attributes in parallel rather than one at a time.
Overall, the MAVTs seem to be a promising new approach that could lead to more powerful and versatile computer vision models in the future.
Technical Explanation
The paper introduces a novel neural network architecture called Multi-Attribute Vision Transformers (MAVTs). MAVTs combine the strengths of Vision Transformers and multi-task learning to create efficient and robust models for a variety of visual recognition tasks.
The key innovations in the MAVT architecture include:
-
Flexible Multi-Head Attention: The standard Vision Transformer uses a single attention mechanism to capture global dependencies in the input image. In contrast, MAVTs have multiple attention heads, each of which can focus on different attributes of the image.
-
Multi-Task Learning: MAVTs are trained to predict multiple attributes of the input image simultaneously, such as object classification, segmentation, and detection. This multi-task approach allows the model to learn more generalizable features compared to single-task models.
-
Attribute-Specific Heads: Each attribute prediction has its own output head in the MAVT, allowing the model to specialize its representations for each task.
The paper evaluates MAVTs on a range of vision benchmarks, including object detection, segmentation, and classification. Compared to previous state-of-the-art models, MAVTs demonstrate superior performance while being more parameter-efficient and robust to distribution shifts.
Critical Analysis
The paper provides a thorough evaluation of the MAVT architecture, exploring its performance across a diverse set of vision tasks and datasets. The multi-task learning approach seems to be a key strength, allowing the model to learn more general and transferable features.
However, the paper does not delve deeply into the limitations or potential drawbacks of the MAVT approach. For example, it would be interesting to understand how the model behaves when the number of attributes or task complexity increases, and whether there are any challenges in effectively training such a multi-headed architecture.
Additionally, the paper could have provided more insights into the interpretability of the MAVT model - for example, how the different attention heads specialize and contribute to the overall predictions. This could help shed light on the inner workings of the model and inspire future improvements.
Overall, the MAVT architecture appears to be a promising step forward in building more efficient and robust computer vision models. Further research exploring its scalability, generalization, and interpretability could help solidify its potential impact on the field.
Conclusion
This paper introduces Multi-Attribute Vision Transformers (MAVTs), a novel neural network architecture that combines the strengths of Vision Transformers and multi-task learning. MAVTs demonstrate superior performance on a range of vision tasks while being more parameter-efficient and robust than previous state-of-the-art models.
The key innovations in the MAVT design include a flexible multi-head attention mechanism and a multi-task learning approach that encourages the model to learn multiple attributes of the input image simultaneously. This allows MAVTs to learn more generalizable features and adapt better to different visual recognition challenges.
The paper's thorough experimental evaluation suggests that MAVTs could be a significant step forward in building more powerful and versatile computer vision models. Further research exploring the scalability, interpretability, and broader implications of this approach could help unlock its full potential and drive progress in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Attribute Vision Transformers are Efficient and Robust Learners
Hanan Gani, Nada Saadi, Noor Hussein, Karthik Nandakumar
Since their inception, Vision Transformers (ViTs) have emerged as a compelling alternative to Convolutional Neural Networks (CNNs) across a wide spectrum of tasks. ViTs exhibit notable characteristics, including global attention, resilience against occlusions, and adaptability to distribution shifts. One underexplored aspect of ViTs is their potential for multi-attribute learning, referring to their ability to simultaneously grasp multiple attribute-related tasks. In this paper, we delve into the multi-attribute learning capability of ViTs, presenting a straightforward yet effective strategy for training various attributes through a single ViT network as distinct tasks. We assess the resilience of multi-attribute ViTs against adversarial attacks and compare their performance against ViTs designed for single attributes. Moreover, we further evaluate the robustness of multi-attribute ViTs against a recent transformer based attack called Patch-Fool. Our empirical findings on the CelebA dataset provide validation for our assertion. Our code is available at https://github.com/hananshafi/MTL-ViT
Read more7/22/2024

0
Query-Efficient Hard-Label Black-Box Attack against Vision Transformers
Chao Zhou, Xiaowen Shi, Yuan-Gen Wang
Recent studies have revealed that vision transformers (ViTs) face similar security risks from adversarial attacks as deep convolutional neural networks (CNNs). However, directly applying attack methodology on CNNs to ViTs has been demonstrated to be ineffective since the ViTs typically work on patch-wise encoding. This article explores the vulnerability of ViTs against adversarial attacks under a black-box scenario, and proposes a novel query-efficient hard-label adversarial attack method called AdvViT. Specifically, considering that ViTs are highly sensitive to patch modification, we propose to optimize the adversarial perturbation on the individual patches. To reduce the dimension of perturbation search space, we modify only a handful of low-frequency components of each patch. Moreover, we design a weight mask matrix for all patches to further optimize the perturbation on different regions of a whole image. We test six mainstream ViT backbones on the ImageNet-1k dataset. Experimental results show that compared with the state-of-the-art attacks on CNNs, our AdvViT achieves much lower $L_2$-norm distortion under the same query budget, sufficiently validating the vulnerability of ViTs against adversarial attacks.
Read more7/2/2024

0
Convolutional Neural Networks and Vision Transformers for Fashion MNIST Classification: A Literature Review
Sonia Bbouzidi, Ghazala Hcini, Imen Jdey, Fadoua Drira
Our review explores the comparative analysis between Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) in the domain of image classification, with a particular focus on clothing classification within the e-commerce sector. Utilizing the Fashion MNIST dataset, we delve into the unique attributes of CNNs and ViTs. While CNNs have long been the cornerstone of image classification, ViTs introduce an innovative self-attention mechanism enabling nuanced weighting of different input data components. Historically, transformers have primarily been associated with Natural Language Processing (NLP) tasks. Through a comprehensive examination of existing literature, our aim is to unveil the distinctions between ViTs and CNNs in the context of image classification. Our analysis meticulously scrutinizes state-of-the-art methodologies employing both architectures, striving to identify the factors influencing their performance. These factors encompass dataset characteristics, image dimensions, the number of target classes, hardware infrastructure, and the specific architectures along with their respective top results. Our key goal is to determine the most appropriate architecture between ViT and CNN for classifying images in the Fashion MNIST dataset within the e-commerce industry, while taking into account specific conditions and needs. We highlight the importance of combining these two architectures with different forms to enhance overall performance. By uniting these architectures, we can take advantage of their unique strengths, which may lead to more precise and reliable models for e-commerce applications. CNNs are skilled at recognizing local patterns, while ViTs are effective at grasping overall context, making their combination a promising strategy for boosting image classification performance.
Read more6/6/2024
0
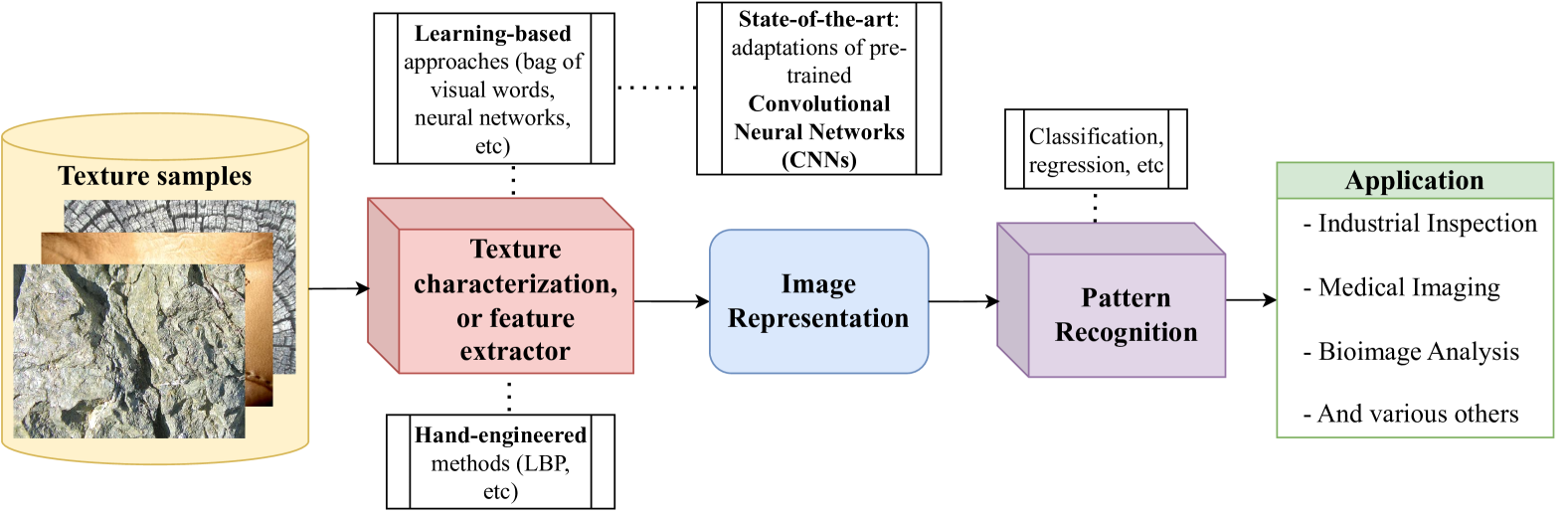
A Comparative Survey of Vision Transformers for Feature Extraction in Texture Analysis
Leonardo Scabini, Andre Sacilotti, Kallil M. Zielinski, Lucas C. Ribas, Bernard De Baets, Odemir M. Bruno
Texture, a significant visual attribute in images, has been extensively investigated across various image recognition applications. Convolutional Neural Networks (CNNs), which have been successful in many computer vision tasks, are currently among the best texture analysis approaches. On the other hand, Vision Transformers (ViTs) have been surpassing the performance of CNNs on tasks such as object recognition, causing a paradigm shift in the field. However, ViTs have so far not been scrutinized for texture recognition, hindering a proper appreciation of their potential in this specific setting. For this reason, this work explores various pre-trained ViT architectures when transferred to tasks that rely on textures. We review 21 different ViT variants and perform an extensive evaluation and comparison with CNNs and hand-engineered models on several tasks, such as assessing robustness to changes in texture rotation, scale, and illumination, and distinguishing color textures, material textures, and texture attributes. The goal is to understand the potential and differences among these models when directly applied to texture recognition, using pre-trained ViTs primarily for feature extraction and employing linear classifiers for evaluation. We also evaluate their efficiency, which is one of the main drawbacks in contrast to other methods. Our results show that ViTs generally outperform both CNNs and hand-engineered models, especially when using stronger pre-training and tasks involving in-the-wild textures (images from the internet). We highlight the following promising models: ViT-B with DINO pre-training, BeiTv2, and the Swin architecture, as well as the EfficientFormer as a low-cost alternative. In terms of efficiency, although having a higher number of GFLOPs and parameters, ViT-B and BeiT(v2) can achieve a lower feature extraction time on GPUs compared to ResNet50.
Read more6/11/2024