Review for Handling Missing Data with special missing mechanism
2404.04905
0
0

Abstract
Missing data poses a significant challenge in data science, affecting decision-making processes and outcomes. Understanding what missing data is, how it occurs, and why it is crucial to handle it appropriately is paramount when working with real-world data, especially in tabular data, one of the most commonly used data types in the real world. Three missing mechanisms are defined in the literature: Missing Completely At Random (MCAR), Missing At Random (MAR), and Missing Not At Random (MNAR), each presenting unique challenges in imputation. Most existing work are focused on MCAR that is relatively easy to handle. The special missing mechanisms of MNAR and MAR are less explored and understood. This article reviews existing literature on handling missing values. It compares and contrasts existing methods in terms of their ability to handle different missing mechanisms and data types. It identifies research gap in the existing literature and lays out potential directions for future research in the field. The information in this review will help data analysts and researchers to adopt and promote good practices for handling missing data in real-world problems.
Create account to get full access
Background and Preliminary
Missing Data Mechanisms
Missing data can occur for various reasons, and understanding the underlying mechanisms is crucial for selecting appropriate handling techniques. The paper discusses three main missing data mechanisms:
- Missing Completely at Random (MCAR): The probability of a value being missing does not depend on the observed or unobserved data.
- Missing at Random (MAR): The probability of a value being missing depends on the observed data, but not the unobserved data.
- Missing Not at Random (MNAR): The probability of a value being missing depends on the unobserved data.
Correctly identifying the missing data mechanism is essential for applying the right missing data handling methods.
Importance of Handling Missing Data
Missing data can lead to biased estimates and reduced statistical power if not properly addressed. The paper emphasizes the importance of handling missing data, as it can significantly impact the reliability and validity of research findings.
Plain English Explanation
The paper provides a comprehensive review of techniques for handling missing data in research and data analysis. Missing data can occur for various reasons, and the underlying mechanism behind the missing data is crucial for determining the appropriate handling method.
The paper discusses three main types of missing data mechanisms:
-
Missing Completely at Random (MCAR): This means the reason for the missing data is completely unrelated to the data itself. For example, the data was lost due to a technical issue, and the missing values are not influenced by any other variables in the dataset.
-
Missing at Random (MAR): In this case, the reason for the missing data is related to other observed variables in the dataset, but not the unobserved or missing data itself. For instance, older participants may be more likely to have missing income data, but the reason for the missing income is based on their age, not the actual income value.
-
Missing Not at Random (MNAR): This occurs when the reason for the missing data is related to the unobserved or missing data itself. For example, people with higher incomes may be less likely to report their true income, leading to a systematic bias in the missing data.
Correctly identifying the missing data mechanism is essential because it determines the best approach for handling the missing values. Improper handling of missing data can lead to biased results and unreliable conclusions, so addressing this issue is crucial for the reliability and validity of research findings.
Technical Explanation
The paper provides a comprehensive review of techniques for handling missing data, focusing on the special mechanisms that can lead to missing data.
The authors discuss the three main missing data mechanisms:
-
Missing Completely at Random (MCAR): In this case, the probability of a value being missing does not depend on the observed or unobserved data. This is the simplest missing data mechanism, and techniques like complete case analysis or mean imputation can be used to handle MCAR data.
-
Missing at Random (MAR): Here, the probability of a value being missing depends on the observed data, but not the unobserved data. This is a more complex scenario, and techniques like multiple imputation or maximum likelihood estimation are often used to address MAR data.
-
Missing Not at Random (MNAR): This occurs when the probability of a value being missing depends on the unobserved data. MNAR data is the most challenging to handle, and techniques like selection models or pattern-mixture models may be required.
The paper emphasizes the importance of correctly identifying the missing data mechanism, as this determines the appropriate handling methods and can have a significant impact on the reliability and validity of research findings.
Critical Analysis
The paper provides a thorough and well-structured review of missing data handling techniques, highlighting the importance of understanding the underlying missing data mechanisms. The authors have covered the key aspects of the topic, including the definitions of the different missing data mechanisms and the associated handling methods.
One potential limitation of the paper is that it does not delve deeply into the practical implementation and performance of the various missing data handling techniques. The paper could have benefited from a more comprehensive discussion of the strengths, weaknesses, and appropriate use cases of the different methods, as well as guidance on how to select the most suitable approach based on the specific research context.
Additionally, the paper could have explored the potential biases and assumptions inherent in some of the missing data handling techniques, particularly in the case of MNAR data, where the underlying mechanisms are the most challenging to identify and address.
Despite these minor limitations, the paper serves as a valuable resource for researchers and data analysts interested in understanding the complexities of missing data and the importance of selecting the appropriate handling techniques.
Conclusion
The paper provides a comprehensive review of techniques for handling missing data, with a focus on the different missing data mechanisms that can occur. The authors emphasize the importance of correctly identifying the missing data mechanism, as this determines the most appropriate handling method and can have a significant impact on the reliability and validity of research findings.
By understanding the nuances of missing data and the associated handling techniques, researchers and data analysts can make more informed decisions and produce more robust and trustworthy results. This knowledge is particularly crucial in fields where missing data is common, such as in medical research, social sciences, and various other data-driven disciplines.
The insights and recommendations provided in this paper can serve as a valuable guide for researchers and practitioners looking to improve their approaches to missing data and enhance the overall quality and impact of their work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
Algorithmic Recourse with Missing Values
Kentaro Kanamori, Takuya Takagi, Ken Kobayashi, Yuichi Ike
0
0
This paper proposes a new framework of algorithmic recourse (AR) that works even in the presence of missing values. AR aims to provide a recourse action for altering the undesired prediction result given by a classifier. Existing AR methods assume that we can access complete information on the features of an input instance. However, we often encounter missing values in a given instance (e.g., due to privacy concerns), and previous studies have not discussed such a practical situation. In this paper, we first empirically and theoretically show the risk that a naive approach with a single imputation technique fails to obtain good actions regarding their validity, cost, and features to be changed. To alleviate this risk, we formulate the task of obtaining a valid and low-cost action for a given incomplete instance by incorporating the idea of multiple imputation. Then, we provide some theoretical analyses of our task and propose a practical solution based on mixed-integer linear optimization. Experimental results demonstrated the efficacy of our method in the presence of missing values compared to the baselines.
5/24/2024
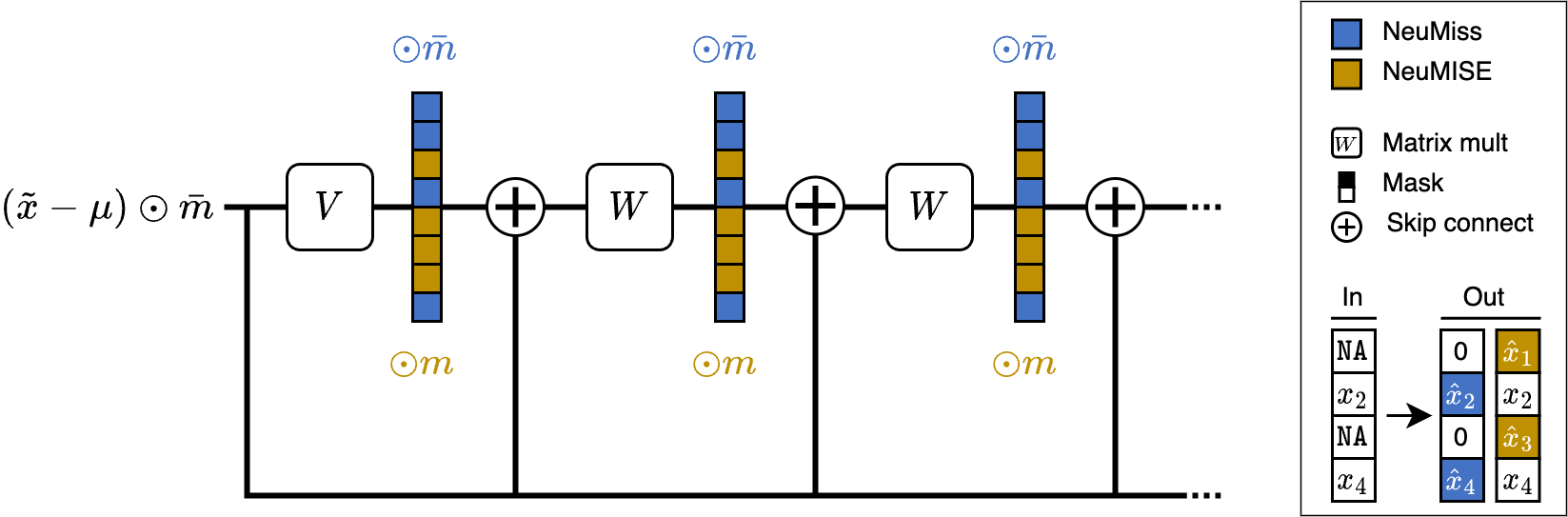
Robust prediction under missingness shifts
Patrick Rockenschaub, Zhicong Xian, Alireza Zamanian, Marta Piperno, Octavia-Andreea Ciora, Elisabeth Pachl, Narges Ahmidi
0
0
Prediction becomes more challenging with missing covariates. What method is chosen to handle missingness can greatly affect how models perform. In many real-world problems, the best prediction performance is achieved by models that can leverage the informative nature of a value being missing. Yet, the reasons why a covariate goes missing can change once a model is deployed in practice. If such a missingness shift occurs, the conditional probability of a value being missing differs in the target data. Prediction performance in the source data may no longer be a good selection criterion, and approaches that do not rely on informative missingness may be preferable. However, we show that the Bayes predictor remains unchanged by ignorable shifts for which the probability of missingness only depends on observed data. Any consistent estimator of the Bayes predictor may therefore result in robust prediction under those conditions, although we show empirically that different methods appear robust to different types of shifts. If the missingness shift is non-ignorable, the Bayes predictor may change due to the shift. While neither approach recovers the Bayes predictor in this case, we found empirically that disregarding missingness was most beneficial when it was highly informative.
6/26/2024
📊
Imputation of missing values in multi-view data
Wouter van Loon, Marjolein Fokkema, Frank de Vos, Marisa Koini, Reinhold Schmidt, Mark de Rooij
0
0
Data for which a set of objects is described by multiple distinct feature sets (called views) is known as multi-view data. When missing values occur in multi-view data, all features in a view are likely to be missing simultaneously. This may lead to very large quantities of missing data which, especially when combined with high-dimensionality, can make the application of conditional imputation methods computationally infeasible. However, the multi-view structure could be leveraged to reduce the complexity and computational load of imputation. We introduce a new imputation method based on the existing stacked penalized logistic regression (StaPLR) algorithm for multi-view learning. It performs imputation in a dimension-reduced space to address computational challenges inherent to the multi-view context. We compare the performance of the new imputation method with several existing imputation algorithms in simulated data sets and a real data application. The results show that the new imputation method leads to competitive results at a much lower computational cost, and makes the use of advanced imputation algorithms such as missForest and predictive mean matching possible in settings where they would otherwise be computationally infeasible.
6/21/2024
Imputation using training labels and classification via label imputation
Thu Nguyen, Tuan L. Vo, P{aa}l Halvorsen, Michael A. Riegler
0
0
Missing data is a common problem in practical settings. Various imputation methods have been developed to deal with missing data. However, even though the label is usually available in the training data, the common practice of imputation usually only relies on the input and ignores the label. In this work, we illustrate how stacking the label into the input can significantly improve the imputation of the input. In addition, we propose a classification strategy that initializes the predicted test label with missing values and stacks the label with the input for imputation. This allows imputing the label and the input at the same time. Also, the technique is capable of handling data training with missing labels without any prior imputation and is applicable to continuous, categorical, or mixed-type data. Experiments show promising results in terms of accuracy.
4/24/2024