Imputation of missing values in multi-view data
2210.14484
0
0
📊
Abstract
Data for which a set of objects is described by multiple distinct feature sets (called views) is known as multi-view data. When missing values occur in multi-view data, all features in a view are likely to be missing simultaneously. This may lead to very large quantities of missing data which, especially when combined with high-dimensionality, can make the application of conditional imputation methods computationally infeasible. However, the multi-view structure could be leveraged to reduce the complexity and computational load of imputation. We introduce a new imputation method based on the existing stacked penalized logistic regression (StaPLR) algorithm for multi-view learning. It performs imputation in a dimension-reduced space to address computational challenges inherent to the multi-view context. We compare the performance of the new imputation method with several existing imputation algorithms in simulated data sets and a real data application. The results show that the new imputation method leads to competitive results at a much lower computational cost, and makes the use of advanced imputation algorithms such as missForest and predictive mean matching possible in settings where they would otherwise be computationally infeasible.
Create account to get full access
Overview
- Multi-view data refers to datasets where each object is described by multiple distinct feature sets or "views"
- When there are missing values in multi-view data, entire views are often missing simultaneously, leading to large amounts of missing data
- This can make advanced imputation methods computationally infeasible, especially when combined with high-dimensionality
- The authors introduce a new imputation method that leverages the multi-view structure to reduce the complexity and computational load of imputation
Plain English Explanation
Imagine you have a dataset about people, where each person is described by multiple sets of information or "views" - for example, their demographic details, medical history, and financial records. When there are missing values in this dataset, it's common for all the information in a particular view to be missing at the same time. This can result in a huge amount of missing data, which becomes especially challenging when the dataset has a large number of features.
The authors of this paper recognized that the multi-view structure of the data could be used to make the imputation process more efficient. They developed a new imputation method that performs the imputation in a lower-dimensional space, reducing the computational burden. This allows them to use more advanced imputation algorithms, like missForest and predictive mean matching, that would otherwise be too computationally intensive for this type of dataset.
Technical Explanation
The authors introduce a new imputation method based on the existing stacked penalized logistic regression (StaPLR) algorithm for multi-view learning. Their approach performs the imputation in a dimension-reduced space to address the computational challenges inherent to the multi-view setting, where entire views can be missing simultaneously, leading to large amounts of missing data.
The authors compare the performance of their new imputation method to several existing imputation algorithms using both simulated data and a real-world dataset. The results show that their new method achieves competitive imputation accuracy at a much lower computational cost, making it possible to use advanced imputation techniques like missForest and predictive mean matching in settings where they would otherwise be computationally infeasible.
Critical Analysis
The authors acknowledge that their method, like any imputation approach, has certain limitations. For example, the performance of the imputation may be sensitive to the specific characteristics of the multi-view data, such as the degree of correlation between views. The authors also note that their method relies on the assumption that the missing data are missing at random, which may not always be the case in real-world scenarios.
Additionally, the authors do not explore the potential for their method to introduce bias or distort the underlying data distribution, which is an important consideration when using any imputation technique. Further research would be needed to fully understand the robustness and reliability of the method in different types of multi-view data.
Conclusion
The authors have developed a new imputation method that leverages the multi-view structure of data to reduce the computational complexity of the imputation process. This allows for the use of more advanced imputation algorithms, which can lead to improved imputation accuracy, particularly in high-dimensional, multi-view datasets with large amounts of missing data.
The authors' work highlights the importance of considering the underlying data structure when designing imputation methods, and demonstrates the potential benefits of exploiting specific data characteristics to improve the efficiency and effectiveness of missing data handling. As the volume and complexity of data continue to grow, innovative approaches like this will be increasingly valuable for enabling robust and scalable data analysis in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Multilevel Stochastic Optimization for Imputation in Massive Medical Data Records
Wenrui Li, Xiaoyu Wang, Yuetian Sun, Snezana Milanovic, Mark Kon, Julio Enrique Castrillon-Candas
0
0
It has long been a recognized problem that many datasets contain significant levels of missing numerical data. A potentially critical predicate for application of machine learning methods to datasets involves addressing this problem. However, this is a challenging task. In this paper, we apply a recently developed multi-level stochastic optimization approach to the problem of imputation in massive medical records. The approach is based on computational applied mathematics techniques and is highly accurate. In particular, for the Best Linear Unbiased Predictor (BLUP) this multi-level formulation is exact, and is significantly faster and more numerically stable. This permits practical application of Kriging methods to data imputation problems for massive datasets. We test this approach on data from the National Inpatient Sample (NIS) data records, Healthcare Cost and Utilization Project (HCUP), Agency for Healthcare Research and Quality. Numerical results show that the multi-level method significantly outperforms current approaches and is numerically robust. It has superior accuracy as compared with methods recommended in the recent report from HCUP. Benchmark tests show up to 75% reductions in error. Furthermore, the results are also superior to recent state of the art methods such as discriminative deep learning.
4/4/2024
Imputation using training labels and classification via label imputation
Thu Nguyen, Tuan L. Vo, P{aa}l Halvorsen, Michael A. Riegler
0
0
Missing data is a common problem in practical settings. Various imputation methods have been developed to deal with missing data. However, even though the label is usually available in the training data, the common practice of imputation usually only relies on the input and ignores the label. In this work, we illustrate how stacking the label into the input can significantly improve the imputation of the input. In addition, we propose a classification strategy that initializes the predicted test label with missing values and stacks the label with the input for imputation. This allows imputing the label and the input at the same time. Also, the technique is capable of handling data training with missing labels without any prior imputation and is applicable to continuous, categorical, or mixed-type data. Experiments show promising results in terms of accuracy.
4/24/2024
🤯
View selection in multi-view stacking: Choosing the meta-learner
Wouter van Loon, Marjolein Fokkema, Botond Szabo, Mark de Rooij
0
0
Multi-view stacking is a framework for combining information from different views (i.e. different feature sets) describing the same set of objects. In this framework, a base-learner algorithm is trained on each view separately, and their predictions are then combined by a meta-learner algorithm. In a previous study, stacked penalized logistic regression, a special case of multi-view stacking, has been shown to be useful in identifying which views are most important for prediction. In this article we expand this research by considering seven different algorithms to use as the meta-learner, and evaluating their view selection and classification performance in simulations and two applications on real gene-expression data sets. Our results suggest that if both view selection and classification accuracy are important to the research at hand, then the nonnegative lasso, nonnegative adaptive lasso and nonnegative elastic net are suitable meta-learners. Exactly which among these three is to be preferred depends on the research context. The remaining four meta-learners, namely nonnegative ridge regression, nonnegative forward selection, stability selection and the interpolating predictor, show little advantages in order to be preferred over the other three.
4/16/2024
Privacy Preserving Data Imputation via Multi-party Computation for Medical Applications
Julia Jentsch, Ali Burak Unal, c{S}eyma Selcan Mau{g}ara, Mete Akgun
0
0
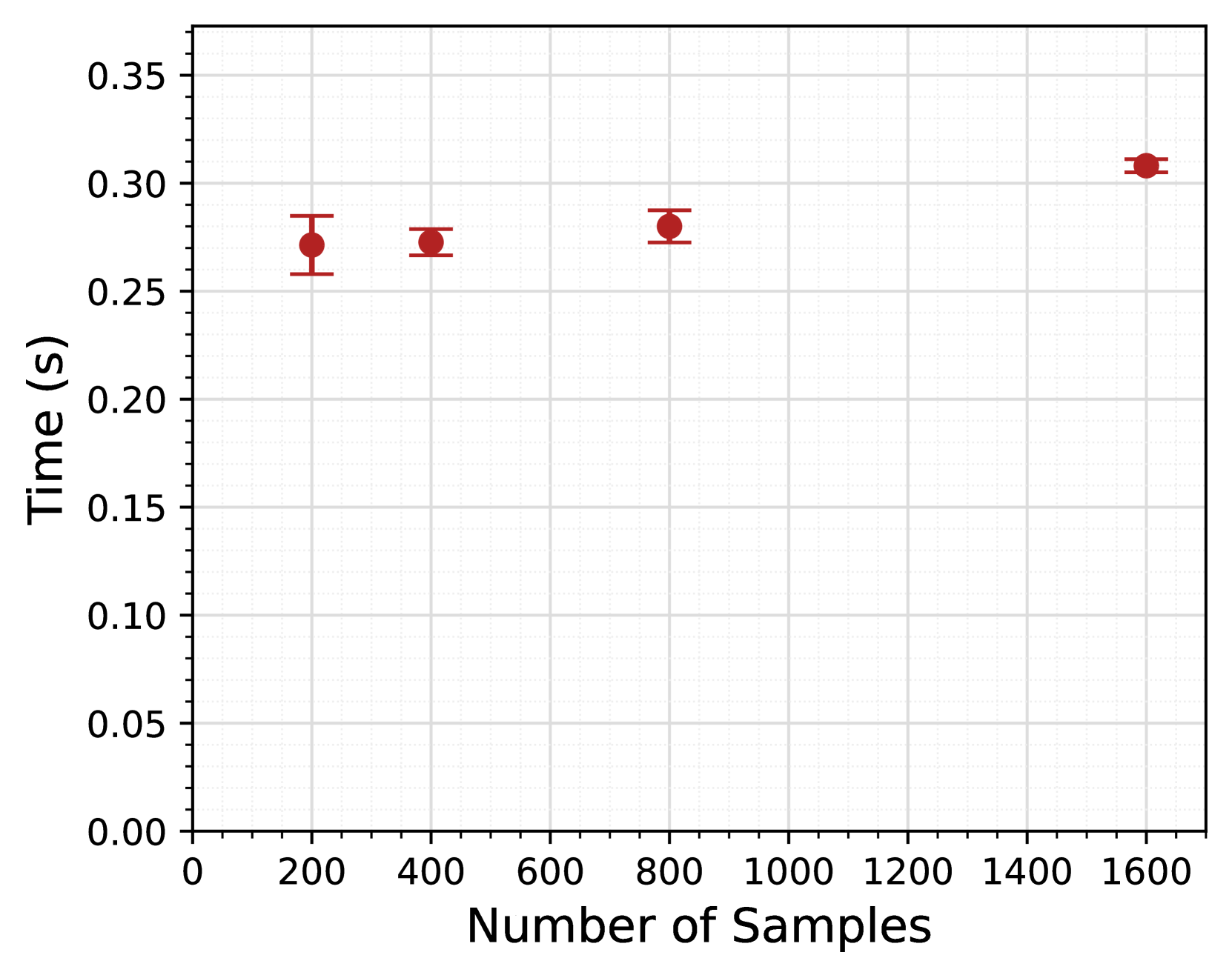
Handling missing data is crucial in machine learning, but many datasets contain gaps due to errors or non-response. Unlike traditional methods such as listwise deletion, which are simple but inadequate, the literature offers more sophisticated and effective methods, thereby improving sample size and accuracy. However, these methods require accessing the whole dataset, which contradicts the privacy regulations when the data is distributed among multiple sources. Especially in the medical and healthcare domain, such access reveals sensitive information about patients. This study addresses privacy-preserving imputation methods for sensitive data using secure multi-party computation, enabling secure computations without revealing any party's sensitive information. In this study, we realized the mean, median, regression, and kNN imputation methods in a privacy-preserving way. We specifically target the medical and healthcare domains considering the significance of protection of the patient data, showcasing our methods on a diabetes dataset. Experiments on the diabetes dataset validated the correctness of our privacy-preserving imputation methods, yielding the largest error around $3 times 10^{-3}$, closely matching plaintext methods. We also analyzed the scalability of our methods to varying numbers of samples, showing their applicability to real-world healthcare problems. Our analysis demonstrated that all our methods scale linearly with the number of samples. Except for kNN, the runtime of all our methods indicates that they can be utilized for large datasets.
5/30/2024