Imputation using training labels and classification via label imputation
2311.16877
0
0
Abstract
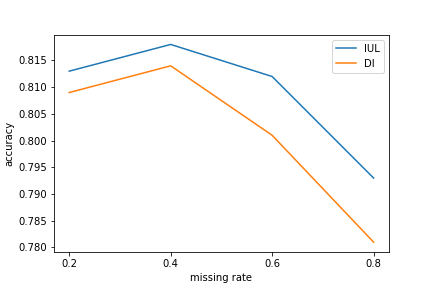
Missing data is a common problem in practical settings. Various imputation methods have been developed to deal with missing data. However, even though the label is usually available in the training data, the common practice of imputation usually only relies on the input and ignores the label. In this work, we illustrate how stacking the label into the input can significantly improve the imputation of the input. In addition, we propose a classification strategy that initializes the predicted test label with missing values and stacks the label with the input for imputation. This allows imputing the label and the input at the same time. Also, the technique is capable of handling data training with missing labels without any prior imputation and is applicable to continuous, categorical, or mixed-type data. Experiments show promising results in terms of accuracy.
Create account to get full access
Introduction
This paper presents a novel approach for imputing missing data using training labels and classification via label imputation. The key idea is to leverage the available labeled data to improve the imputation of missing values, which can be particularly useful in scenarios with high rates of missing data.
Related Works
The paper situates its work within the broader context of missing data imputation techniques. It discusses how traditional imputation methods, such as mean imputation and multiple imputation, may not be adequate when dealing with complex, high-dimensional datasets. The authors also highlight the potential limitations of iterative graph-based imputation and the need for approaches that can handle different missing data mechanisms.
Preliminary: missForest algorithm
The paper builds upon the missForest algorithm, which is a random forest-based method for imputing missing values in mixed-type datasets. The authors explain how missForest works and how it can be extended to leverage available training labels for improved imputation.
Imputation using training labels and classification via label imputation
The core of the paper's contribution is the proposed approach, which combines the missForest algorithm with a classification step to leverage training labels. The key idea is to use the available labeled data to train a classifier, which is then used to impute missing labels. This imputed label information is then fed back into the missForest algorithm to improve the imputation of other missing values in the dataset.
The authors provide a detailed technical explanation of the proposed method, including the algorithm steps and the underlying intuition. They also discuss the potential advantages of this approach, such as its ability to handle complex, high-dimensional datasets with different missing data mechanisms.
Evaluation and Experiments
The paper presents an extensive evaluation of the proposed method using both synthetic and real-world datasets. The authors compare the performance of their approach to other state-of-the-art imputation techniques, demonstrating its effectiveness in terms of various evaluation metrics.
Conclusion
In conclusion, this paper introduces a novel approach for imputing missing data by leveraging available training labels and classification. The proposed method shows promising results in improving imputation accuracy, particularly in scenarios with high rates of missing data. The authors suggest that this approach could have significant practical applications in fields such as healthcare, finance, and social sciences, where missing data is a common challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Data Imputation by Pursuing Better Classification: A Supervised Kernel-Based Method
Ruikai Yang, Fan He, Mingzhen He, Kaijie Wang, Xiaolin Huang
0
0
Data imputation, the process of filling in missing feature elements for incomplete data sets, plays a crucial role in data-driven learning. A fundamental belief is that data imputation is helpful for learning performance, and it follows that the pursuit of better classification can guide the data imputation process. While some works consider using label information to assist in this task, their simplistic utilization of labels lacks flexibility and may rely on strict assumptions. In this paper, we propose a new framework that effectively leverages supervision information to complete missing data in a manner conducive to classification. Specifically, this framework operates in two stages. Firstly, it leverages labels to supervise the optimization of similarity relationships among data, represented by the kernel matrix, with the goal of enhancing classification accuracy. To mitigate overfitting that may occur during this process, a perturbation variable is introduced to improve the robustness of the framework. Secondly, the learned kernel matrix serves as additional supervision information to guide data imputation through regression, utilizing the block coordinate descent method. The superiority of the proposed method is evaluated on four real-world data sets by comparing it with state-of-the-art imputation methods. Remarkably, our algorithm significantly outperforms other methods when the data is missing more than 60% of the features
5/14/2024
📊
Imputation of missing values in multi-view data
Wouter van Loon, Marjolein Fokkema, Frank de Vos, Marisa Koini, Reinhold Schmidt, Mark de Rooij
0
0
Data for which a set of objects is described by multiple distinct feature sets (called views) is known as multi-view data. When missing values occur in multi-view data, all features in a view are likely to be missing simultaneously. This may lead to very large quantities of missing data which, especially when combined with high-dimensionality, can make the application of conditional imputation methods computationally infeasible. However, the multi-view structure could be leveraged to reduce the complexity and computational load of imputation. We introduce a new imputation method based on the existing stacked penalized logistic regression (StaPLR) algorithm for multi-view learning. It performs imputation in a dimension-reduced space to address computational challenges inherent to the multi-view context. We compare the performance of the new imputation method with several existing imputation algorithms in simulated data sets and a real data application. The results show that the new imputation method leads to competitive results at a much lower computational cost, and makes the use of advanced imputation algorithms such as missForest and predictive mean matching possible in settings where they would otherwise be computationally infeasible.
6/21/2024
Knockout: A simple way to handle missing inputs
Minh Nguyen, Batuhan K. Karaman, Heejong Kim, Alan Q. Wang, Fengbei Liu, Mert R. Sabuncu
0
0
Deep learning models can extract predictive and actionable information from complex inputs. The richer the inputs, the better these models usually perform. However, models that leverage rich inputs (e.g., multi-modality) can be difficult to deploy widely, because some inputs may be missing at inference. Current popular solutions to this problem include marginalization, imputation, and training multiple models. Marginalization can obtain calibrated predictions but it is computationally costly and therefore only feasible for low dimensional inputs. Imputation may result in inaccurate predictions because it employs point estimates for missing variables and does not work well for high dimensional inputs (e.g., images). Training multiple models whereby each model takes different subsets of inputs can work well but requires knowing missing input patterns in advance. Furthermore, training and retaining multiple models can be costly. We propose an efficient way to learn both the conditional distribution using full inputs and the marginal distributions. Our method, Knockout, randomly replaces input features with appropriate placeholder values during training. We provide a theoretical justification of Knockout and show that it can be viewed as an implicit marginalization strategy. We evaluate Knockout in a wide range of simulations and real-world datasets and show that it can offer strong empirical performance.
6/4/2024
🛠️
Multilevel Stochastic Optimization for Imputation in Massive Medical Data Records
Wenrui Li, Xiaoyu Wang, Yuetian Sun, Snezana Milanovic, Mark Kon, Julio Enrique Castrillon-Candas
0
0
It has long been a recognized problem that many datasets contain significant levels of missing numerical data. A potentially critical predicate for application of machine learning methods to datasets involves addressing this problem. However, this is a challenging task. In this paper, we apply a recently developed multi-level stochastic optimization approach to the problem of imputation in massive medical records. The approach is based on computational applied mathematics techniques and is highly accurate. In particular, for the Best Linear Unbiased Predictor (BLUP) this multi-level formulation is exact, and is significantly faster and more numerically stable. This permits practical application of Kriging methods to data imputation problems for massive datasets. We test this approach on data from the National Inpatient Sample (NIS) data records, Healthcare Cost and Utilization Project (HCUP), Agency for Healthcare Research and Quality. Numerical results show that the multi-level method significantly outperforms current approaches and is numerically robust. It has superior accuracy as compared with methods recommended in the recent report from HCUP. Benchmark tests show up to 75% reductions in error. Furthermore, the results are also superior to recent state of the art methods such as discriminative deep learning.
4/4/2024