Revisit Human-Scene Interaction via Space Occupancy

0
🏷️
Sign in to get full access
Overview
- This paper addresses the challenge of generating realistic human-scene interactions (HSI) in 3D environments, which is crucial for various downstream tasks.
- The key obstacle is the limited availability of high-quality datasets with simultaneously captured human motions and 3D scenes.
- The researchers propose a novel unified view of "Human-Occupancy Interaction" to address this challenge.
Plain English Explanation
The paper focuses on the problem of creating realistic human interactions with 3D environments, which is important for various applications. One of the main difficulties is that there is not enough data available that shows both human movements and detailed 3D scenes at the same time. This makes it hard to train AI systems to generate realistic human-scene interactions.
The researchers come up with a new way of thinking about this problem. They realize that when a person interacts with a scene, they are really interacting with the "occupancy" of the scene - the space that is taken up by the objects and structures. By treating human motion data as records of people interacting with this invisible scene occupancy, the researchers can build a large database of human-occupancy interactions.
This unified view of human-occupancy interaction allows them to train a single motion controller that can generate realistic human movements in diverse 3D environments, without needing detailed 3D scene data for training. The controller learns to navigate around the occupancy of the scene, which makes it work well even in cramped or complex spaces.
Technical Explanation
The key insight of the paper is that human-scene interaction can be viewed as interaction with the "occupancy" of the 3D scene, rather than the specific geometry and layout. By treating human motion data as records of people interacting with invisible scene occupancy, the researchers are able to build a large-scale "Motion Occupancy Base" (MOB) dataset of human-occupancy interactions.
Training a motion controller on this MOB dataset allows the system to generate realistic human movements that navigate around the scene occupancy, without needing access to detailed 3D scene data during training. The controller learns to reach target poses while considering the surrounding occupancy constraints, which enables it to handle challenging, cramped environments as well as more open spaces.
The researchers demonstrate that their occupancy-based approach can produce stable and diverse human-scene interactions in a variety of static and dynamic 3D environments, without requiring ground truth 3D scene data for training. This is a significant advancement over prior methods that rely on paired motion-scene datasets, which are expensive and difficult to acquire at scale.
Critical Analysis
The researchers provide a novel and compelling perspective on the human-scene interaction problem by focusing on the underlying occupancy constraints rather than specific scene geometry. This unified view is an elegant solution to the data acquisition challenges faced in this domain.
However, the paper does not fully address the potential limitations of this approach. For example, it is unclear how well the system would generalize to highly complex or dynamic scenes, where the occupancy constraints may be more nuanced and difficult to capture in the motion data alone. Integrating additional scene understanding cues could further improve the system's ability to handle diverse environments.
Additionally, the evaluation of the generated human-scene interactions is primarily qualitative, and more rigorous quantitative metrics could help assess the realism and effectiveness of the approach. Exploring applications of this technology in areas like virtual environments or robotics would also be valuable.
Conclusion
This paper presents a significant advancement in the field of human-scene interaction generation by proposing a novel "Human-Occupancy Interaction" perspective. The ability to leverage large-scale motion data to create realistic human movements in diverse 3D environments, without requiring detailed scene scans, is a compelling contribution.
The occupancy-based approach has the potential to enable more widespread use of human-scene interaction technology in a variety of applications, from virtual reality to robotics. While the paper leaves room for further refinement and exploration, it represents an important step forward in making high-quality human-scene interaction generation more accessible and scalable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Revisit Human-Scene Interaction via Space Occupancy
Xinpeng Liu, Haowen Hou, Yanchao Yang, Yong-Lu Li, Cewu Lu
Human-scene Interaction (HSI) generation is a challenging task and crucial for various downstream tasks. However, one of the major obstacles is its limited data scale. High-quality data with simultaneously captured human and 3D environments is hard to acquire, resulting in limited data diversity and complexity. In this work, we argue that interaction with a scene is essentially interacting with the space occupancy of the scene from an abstract physical perspective, leading us to a unified novel view of Human-Occupancy Interaction. By treating pure motion sequences as records of humans interacting with invisible scene occupancy, we can aggregate motion-only data into a large-scale paired human-occupancy interaction database: Motion Occupancy Base (MOB). Thus, the need for costly paired motion-scene datasets with high-quality scene scans can be substantially alleviated. With this new unified view of Human-Occupancy interaction, a single motion controller is proposed to reach the target state given the surrounding occupancy. Once trained on MOB with complex occupancy layout, which is stringent to human movements, the controller could handle cramped scenes and generalize well to general scenes with limited complexity like regular living rooms. With no GT 3D scenes for training, our method can generate realistic and stable HSI motions in diverse scenarios, including both static and dynamic scenes. The project is available at https://foruck.github.io/occu-page/.
Read more7/16/2024
📈
0
Unified Human-Scene Interaction via Prompted Chain-of-Contacts
Zeqi Xiao, Tai Wang, Jingbo Wang, Jinkun Cao, Wenwei Zhang, Bo Dai, Dahua Lin, Jiangmiao Pang
Human-Scene Interaction (HSI) is a vital component of fields like embodied AI and virtual reality. Despite advancements in motion quality and physical plausibility, two pivotal factors, versatile interaction control and the development of a user-friendly interface, require further exploration before the practical application of HSI. This paper presents a unified HSI framework, UniHSI, which supports unified control of diverse interactions through language commands. This framework is built upon the definition of interaction as Chain of Contacts (CoC): steps of human joint-object part pairs, which is inspired by the strong correlation between interaction types and human-object contact regions. Based on the definition, UniHSI constitutes a Large Language Model (LLM) Planner to translate language prompts into task plans in the form of CoC, and a Unified Controller that turns CoC into uniform task execution. To facilitate training and evaluation, we collect a new dataset named ScenePlan that encompasses thousands of task plans generated by LLMs based on diverse scenarios. Comprehensive experiments demonstrate the effectiveness of our framework in versatile task execution and generalizability to real scanned scenes. The project page is at https://github.com/OpenRobotLab/UniHSI .
Read more9/4/2024

0
HiSC4D: Human-centered interaction and 4D Scene Capture in Large-scale Space Using Wearable IMUs and LiDAR
Yudi Dai, Zhiyong Wang, Xiping Lin, Chenglu Wen, Lan Xu, Siqi Shen, Yuexin Ma, Cheng Wang
We introduce HiSC4D, a novel Human-centered interaction and 4D Scene Capture method, aimed at accurately and efficiently creating a dynamic digital world, containing large-scale indoor-outdoor scenes, diverse human motions, rich human-human interactions, and human-environment interactions. By utilizing body-mounted IMUs and a head-mounted LiDAR, HiSC4D can capture egocentric human motions in unconstrained space without the need for external devices and pre-built maps. This affords great flexibility and accessibility for human-centered interaction and 4D scene capturing in various environments. Taking into account that IMUs can capture human spatially unrestricted poses but are prone to drifting for long-period using, and while LiDAR is stable for global localization but rough for local positions and orientations, HiSC4D employs a joint optimization method, harmonizing all sensors and utilizing environment cues, yielding promising results for long-term capture in large scenes. To promote research of egocentric human interaction in large scenes and facilitate downstream tasks, we also present a dataset, containing 8 sequences in 4 large scenes (200 to 5,000 $m^2$), providing 36k frames of accurate 4D human motions with SMPL annotations and dynamic scenes, 31k frames of cropped human point clouds, and scene mesh of the environment. A variety of scenarios, such as the basketball gym and commercial street, alongside challenging human motions, such as daily greeting, one-on-one basketball playing, and tour guiding, demonstrate the effectiveness and the generalization ability of HiSC4D. The dataset and code will be publicated on www.lidarhumanmotion.net/hisc4d available for research purposes.
Read more9/17/2024
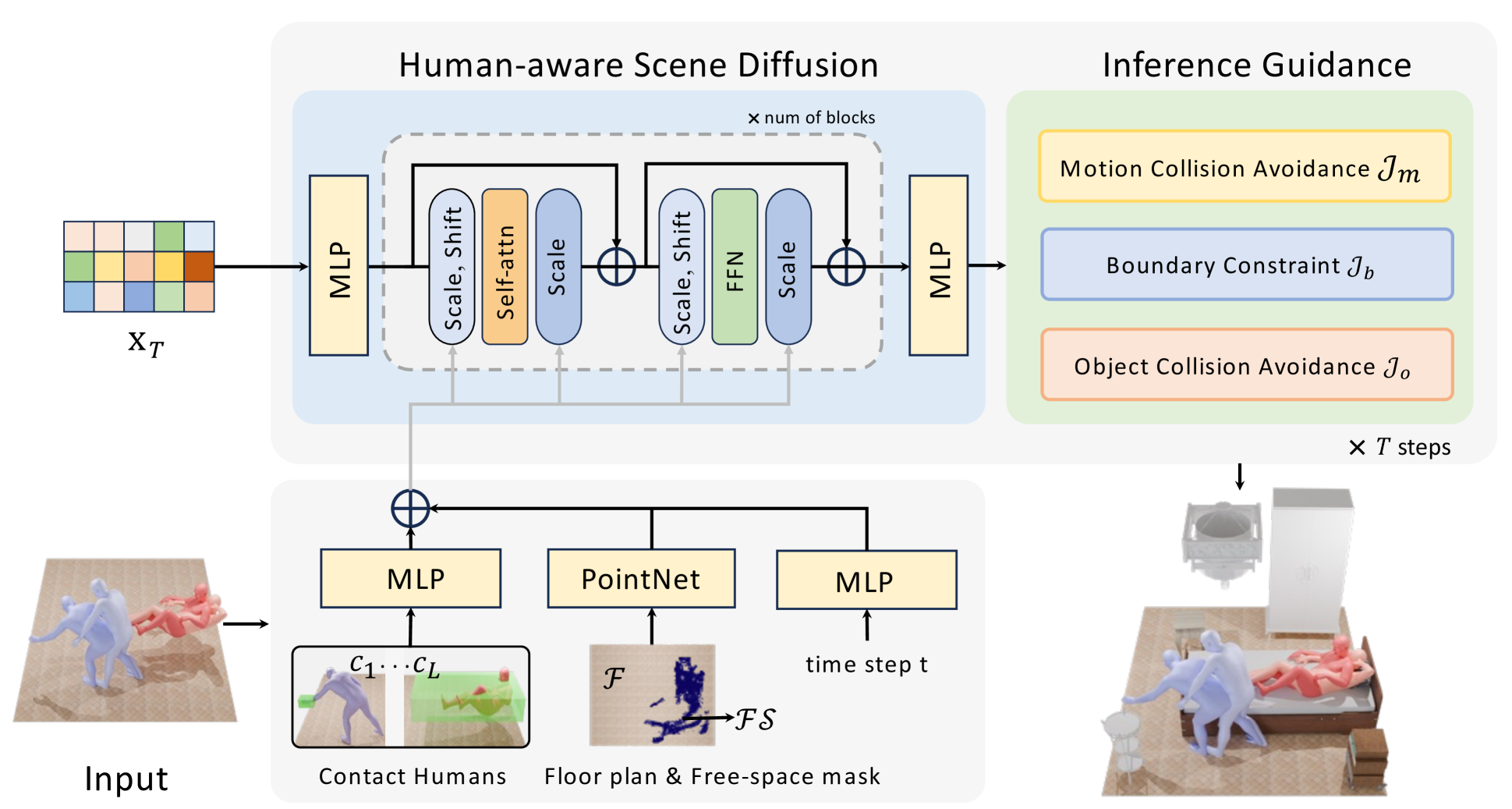
0
Human-Aware 3D Scene Generation with Spatially-constrained Diffusion Models
Xiaolin Hong, Hongwei Yi, Fazhi He, Qiong Cao
Generating 3D scenes from human motion sequences supports numerous applications, including virtual reality and architectural design. However, previous auto-regression-based human-aware 3D scene generation methods have struggled to accurately capture the joint distribution of multiple objects and input humans, often resulting in overlapping object generation in the same space. To address this limitation, we explore the potential of diffusion models that simultaneously consider all input humans and the floor plan to generate plausible 3D scenes. Our approach not only satisfies all input human interactions but also adheres to spatial constraints with the floor plan. Furthermore, we introduce two spatial collision guidance mechanisms: human-object collision avoidance and object-room boundary constraints. These mechanisms help avoid generating scenes that conflict with human motions while respecting layout constraints. To enhance the diversity and accuracy of human-guided scene generation, we have developed an automated pipeline that improves the variety and plausibility of human-object interactions in the existing 3D FRONT HUMAN dataset. Extensive experiments on both synthetic and real-world datasets demonstrate that our framework can generate more natural and plausible 3D scenes with precise human-scene interactions, while significantly reducing human-object collisions compared to previous state-of-the-art methods. Our code and data will be made publicly available upon publication of this work.
Read more8/21/2024