Revisiting the Phenomenon of Syntactic Complexity Convergence on German Dialogue Data

0

Sign in to get full access
Overview
- Explores the phenomenon of syntactic complexity convergence in German dialogue data
- Examines how speakers' syntactic complexity aligns over the course of a conversation
- Provides insights into the cognitive processes underlying language production and interaction
Plain English Explanation
The paper investigates how the complexity of the language used by speakers in a conversation tends to become more aligned over time. Syntactic complexity refers to the grammatical structure and organization of sentences. The researchers looked at German dialogue data to see if speakers' syntactic complexity converges, or becomes more similar, as they interact.
This is an interesting phenomenon because it suggests that there are underlying cognitive mechanisms that drive speakers to modify their language use to better match their conversational partner. By aligning their syntactic complexity, speakers may be facilitating mutual understanding and promoting more efficient communication.
The findings from this study provide insights into the dynamic, interactive nature of language production. They reveal how speakers actively adjust their language in response to their partner, rather than simply producing language in isolation.
Technical Explanation
The researchers analyzed a corpus of German dialogue data to investigate syntactic complexity convergence. They calculated several measures of syntactic complexity, such as sentence length and clause density, for each speaker's utterances.
Over the course of the conversations, the researchers found that the differences in syntactic complexity between speakers decreased. This indicates that the speakers' language became more aligned as the dialogue progressed.
Further analysis revealed that this convergence effect was stronger for certain types of syntactic features, suggesting that speakers may prioritize aligning specific aspects of their language use. The researchers propose that this convergence arises from the need to facilitate mutual understanding and coordination during the interaction.
Critical Analysis
The paper provides a robust empirical investigation of syntactic complexity convergence, with a large corpus of German dialogue data and rigorous statistical analysis. However, the study is limited to a single language and cultural context, so the generalizability of the findings to other languages and conversational settings remains an open question.
Additionally, the paper does not delve deeply into the potential cognitive mechanisms underlying the observed convergence effect. While the authors speculate about the role of mutual understanding and coordination, more research is needed to elucidate the specific psychological processes involved.
It would also be valuable to explore how individual differences, such as personality traits or cognitive abilities, may influence the degree of syntactic complexity convergence. This could shed light on the factors that shape language alignment in dialogue.
Conclusion
This study offers compelling evidence for the phenomenon of syntactic complexity convergence in German dialogue. By demonstrating how speakers' language use becomes more aligned over the course of a conversation, the findings contribute to our understanding of the dynamic, interactive nature of language production and the cognitive processes that support effective communication.
The insights from this research have implications for the development of more natural and adaptive language technologies, as well as for our broader understanding of the social and cognitive foundations of human language use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revisiting the Phenomenon of Syntactic Complexity Convergence on German Dialogue Data
Yu Wang, Hendrik Buschmeier
We revisit the phenomenon of syntactic complexity convergence in conversational interaction, originally found for English dialogue, which has theoretical implication for dialogical concepts such as mutual understanding. We use a modified metric to quantify syntactic complexity based on dependency parsing. The results show that syntactic complexity convergence can be statistically confirmed in one of three selected German datasets that were analysed. Given that the dataset which shows such convergence is much larger than the other two selected datasets, the empirical results indicate a certain degree of linguistic generality of syntactic complexity convergence in conversational interaction. We also found a different type of syntactic complexity convergence in one of the datasets while further investigation is still necessary.
Read more8/23/2024

0
Analysing Cross-Speaker Convergence in Face-to-Face Dialogue through the Lens of Automatically Detected Shared Linguistic Constructions
Esam Ghaleb, Marlou Rasenberg, Wim Pouw, Ivan Toni, Judith Holler, Asl{i} Ozyurek, Raquel Fern'andez
Conversation requires a substantial amount of coordination between dialogue participants, from managing turn taking to negotiating mutual understanding. Part of this coordination effort surfaces as the reuse of linguistic behaviour across speakers, a process often referred to as alignment. While the presence of linguistic alignment is well documented in the literature, several questions remain open, including the extent to which patterns of reuse across speakers have an impact on the emergence of labelling conventions for novel referents. In this study, we put forward a methodology for automatically detecting shared lemmatised constructions -- expressions with a common lexical core used by both speakers within a dialogue -- and apply it to a referential communication corpus where participants aim to identify novel objects for which no established labels exist. Our analyses uncover the usage patterns of shared constructions in interaction and reveal that features such as their frequency and the amount of different constructions used for a referent are associated with the degree of object labelling convergence the participants exhibit after social interaction. More generally, the present study shows that automatically detected shared constructions offer a useful level of analysis to investigate the dynamics of reference negotiation in dialogue.
Read more5/15/2024
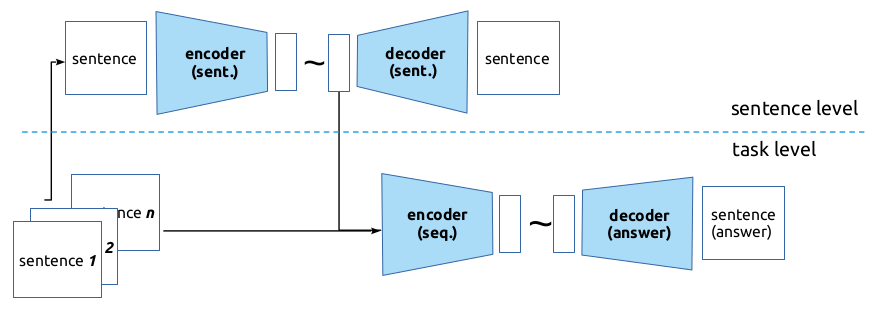
0
Exploring syntactic information in sentence embeddings through multilingual subject-verb agreement
Vivi Nastase, Chunyang Jiang, Giuseppe Samo, Paola Merlo
In this paper, our goal is to investigate to what degree multilingual pretrained language models capture cross-linguistically valid abstract linguistic representations. We take the approach of developing curated synthetic data on a large scale, with specific properties, and using them to study sentence representations built using pretrained language models. We use a new multiple-choice task and datasets, Blackbird Language Matrices (BLMs), to focus on a specific grammatical structural phenomenon -- subject-verb agreement across a variety of sentence structures -- in several languages. Finding a solution to this task requires a system detecting complex linguistic patterns and paradigms in text representations. Using a two-level architecture that solves the problem in two steps -- detect syntactic objects and their properties in individual sentences, and find patterns across an input sequence of sentences -- we show that despite having been trained on multilingual texts in a consistent manner, multilingual pretrained language models have language-specific differences, and syntactic structure is not shared, even across closely related languages.
Read more9/11/2024
↗️
0
Morphosyntactic Analysis for CHILDES
Houjun Liu, Brian MacWhinney
Language development researchers are interested in comparing the process of language learning across languages. Unfortunately, it has been difficult to construct a consistent quantitative framework for such comparisons. However, recent advances in AI (Artificial Intelligence) and ML (Machine Learning) are providing new methods for ASR (automatic speech recognition) and NLP (natural language processing) that can be brought to bear on this problem. Using the Batchalign2 program (Liu et al., 2023), we have been transcribing and linking data for the CHILDES database and have applied the UD (Universal Dependencies) framework to provide a consistent and comparable morphosyntactic analysis for 27 languages. These new resources open possibilities for deeper crosslinguistic study of language learning.
Read more7/18/2024