Revolutionizing Database Q&A with Large Language Models: Comprehensive Benchmark and Evaluation

0

Sign in to get full access
Overview
- This paper presents a comprehensive benchmark and evaluation for using large language models to answer questions about databases.
- The researchers developed a new dataset called DBQABenchmark to assess the performance of language models on database-related question answering.
- The paper evaluates several state-of-the-art language models on the DBQABenchmark and provides insights into their strengths and weaknesses.
Plain English Explanation
The researchers behind this paper recognized that while language models have become highly capable at answering general questions, they may struggle with more specialized domains like databases. To address this, the team created a new dataset called DBQABenchmark that contains a wide variety of questions related to databases.
By evaluating several leading language models on this benchmark, the researchers were able to get a detailed understanding of how well these models perform when it comes to answering database-related questions. The results provide important insights that can help guide the development of more effective language models for database-focused applications.
For example, the paper found that while some models excelled at basic factual questions, they had more difficulty with questions that required deeper reasoning about database concepts and structures. This suggests that further advancements are needed to make language models truly adept at handling complex database-related queries.
Overall, this research represents an important step forward in understanding the capabilities and limitations of language models in specialized domains. The insights gained can inform the design of future language models and help unlock the full potential of these powerful AI systems for a wide range of applications.
Technical Explanation
The core of this paper is the DBQABenchmark dataset, which the researchers developed to assess the performance of large language models on database-related question answering. The dataset contains over 10,000 questions spanning a diverse range of database topics, including schema understanding, query formulation, and data interpretation.
To evaluate the models, the researchers fine-tuned several state-of-the-art language models, including [object Object], [object Object], and [object Object], on the DBQABenchmark. The models were tested on their ability to correctly answer the various types of database questions, and the results were analyzed in depth.
The findings reveal some key strengths and weaknesses of the language models. While they generally performed well on basic factual questions, the models struggled more with questions that required deeper reasoning about database concepts and structures. The paper also explored the impact of different prompting strategies and found that carefully designed prompts could significantly boost the models' performance.
Overall, this research provides a comprehensive evaluation of how well current language models can handle database-related tasks. The insights gained can inform the development of more effective AI systems for database applications, ultimately unlocking new possibilities for data-driven decision making and problem-solving.
Critical Analysis
The researchers acknowledge several limitations of their study and opportunities for further research. For instance, the DBQABenchmark dataset, while comprehensive, may not capture the full breadth of real-world database questions and use cases. Additionally, the paper focused on a limited set of language models, and evaluating a wider range of models could provide an even more complete picture.
The researchers also note that the performance of the language models could be further improved through additional fine-tuning and prompt engineering. Exploring more advanced techniques for adapting language models to specialized domains like databases could lead to even stronger results.
Another area for further exploration is the potential for language models to go beyond simply answering questions and engage in more interactive, collaborative database tasks. Leveraging the natural language capabilities of these models could enable new ways of interfacing with and manipulating data that go beyond traditional database management tools.
Overall, while this paper represents a significant advance in understanding the capabilities of language models for database-related tasks, there is still much work to be done to fully realize the potential of these powerful AI systems in this domain.
Conclusion
The research presented in this paper marks an important milestone in the pursuit of using large language models for database-focused applications. By developing the comprehensive DBQABenchmark dataset and thoroughly evaluating several state-of-the-art models, the researchers have provided valuable insights into the current strengths and limitations of these AI systems when it comes to answering database-related questions.
The findings suggest that while language models have made impressive strides in general question answering, there is still room for improvement when it comes to specialized domains like databases. Unlocking the full potential of these models for database applications will likely require further advancements in areas like prompt engineering, fine-tuning techniques, and the development of more specialized training data and architectures.
Nonetheless, this research represents a significant step forward and lays the groundwork for future breakthroughs that could revolutionize how we interact with and derive insights from databases. As language models continue to evolve, the possibilities for AI-powered database management and analysis are only expected to grow, with far-reaching implications for fields ranging from business intelligence to scientific research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revolutionizing Database Q&A with Large Language Models: Comprehensive Benchmark and Evaluation
Yihang Zheng, Bo Li, Zhenghao Lin, Yi Luo, Xuanhe Zhou, Chen Lin, Jinsong Su, Guoliang Li, Shifu Li
The development of Large Language Models (LLMs) has revolutionized Q&A across various industries, including the database domain. However, there is still a lack of a comprehensive benchmark to evaluate the capabilities of different LLMs and their modular components in database Q&A. To this end, we introduce DQA, the first comprehensive database Q&A benchmark. DQA features an innovative LLM-based method for automating the generation, cleaning, and rewriting of database Q&A, resulting in over 240,000 Q&A pairs in English and Chinese. These Q&A pairs cover nearly all aspects of database knowledge, including database manuals, database blogs, and database tools. This inclusion allows for additional assessment of LLMs' Retrieval-Augmented Generation (RAG) and Tool Invocation Generation (TIG) capabilities in the database Q&A task. Furthermore, we propose a comprehensive LLM-based database Q&A testbed on DQA. This testbed is highly modular and scalable, with both basic and advanced components like Question Classification Routing (QCR), RAG, TIG, and Prompt Template Engineering (PTE). Besides, DQA provides a complete evaluation pipeline, featuring diverse metrics and a standardized evaluation process to ensure comprehensiveness, accuracy, and fairness. We use DQA to evaluate the database Q&A capabilities under the proposed testbed comprehensively. The evaluation reveals findings like (i) the strengths and limitations of nine different LLM-based Q&A bots and (ii) the performance impact and potential improvements of various service components (e.g., QCR, RAG, TIG). We hope our benchmark and findings will better guide the future development of LLM-based database Q&A research.
Read more9/10/2024

1
TableBench: A Comprehensive and Complex Benchmark for Table Question Answering
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xinrun Du, Di Liang, Daixin Shu, Xianfu Cheng, Tianzhen Sun, Guanglin Niu, Tongliang Li, Zhoujun Li
Recent advancements in Large Language Models (LLMs) have markedly enhanced the interpretation and processing of tabular data, introducing previously unimaginable capabilities. Despite these achievements, LLMs still encounter significant challenges when applied in industrial scenarios, particularly due to the increased complexity of reasoning required with real-world tabular data, underscoring a notable disparity between academic benchmarks and practical applications. To address this discrepancy, we conduct a detailed investigation into the application of tabular data in industrial scenarios and propose a comprehensive and complex benchmark TableBench, including 18 fields within four major categories of table question answering (TableQA) capabilities. Furthermore, we introduce TableLLM, trained on our meticulously constructed training set TableInstruct, achieving comparable performance with GPT-3.5. Massive experiments conducted on TableBench indicate that both open-source and proprietary LLMs still have significant room for improvement to meet real-world demands, where the most advanced model, GPT-4, achieves only a modest score compared to humans.
Read more8/20/2024

0
DebateQA: Evaluating Question Answering on Debatable Knowledge
Rongwu Xu, Xuan Qi, Zehan Qi, Wei Xu, Zhijiang Guo
The rise of large language models (LLMs) has enabled us to seek answers to inherently debatable questions on LLM chatbots, necessitating a reliable way to evaluate their ability. However, traditional QA benchmarks assume fixed answers are inadequate for this purpose. To address this, we introduce DebateQA, a dataset of 2,941 debatable questions, each accompanied by multiple human-annotated partial answers that capture a variety of perspectives. We develop two metrics: Perspective Diversity, which evaluates the comprehensiveness of perspectives, and Dispute Awareness, which assesses if the LLM acknowledges the question's debatable nature. Experiments demonstrate that both metrics align with human preferences and are stable across different underlying models. Using DebateQA with two metrics, we assess 12 popular LLMs and retrieval-augmented generation methods. Our findings reveal that while LLMs generally excel at recognizing debatable issues, their ability to provide comprehensive answers encompassing diverse perspectives varies considerably.
Read more8/6/2024
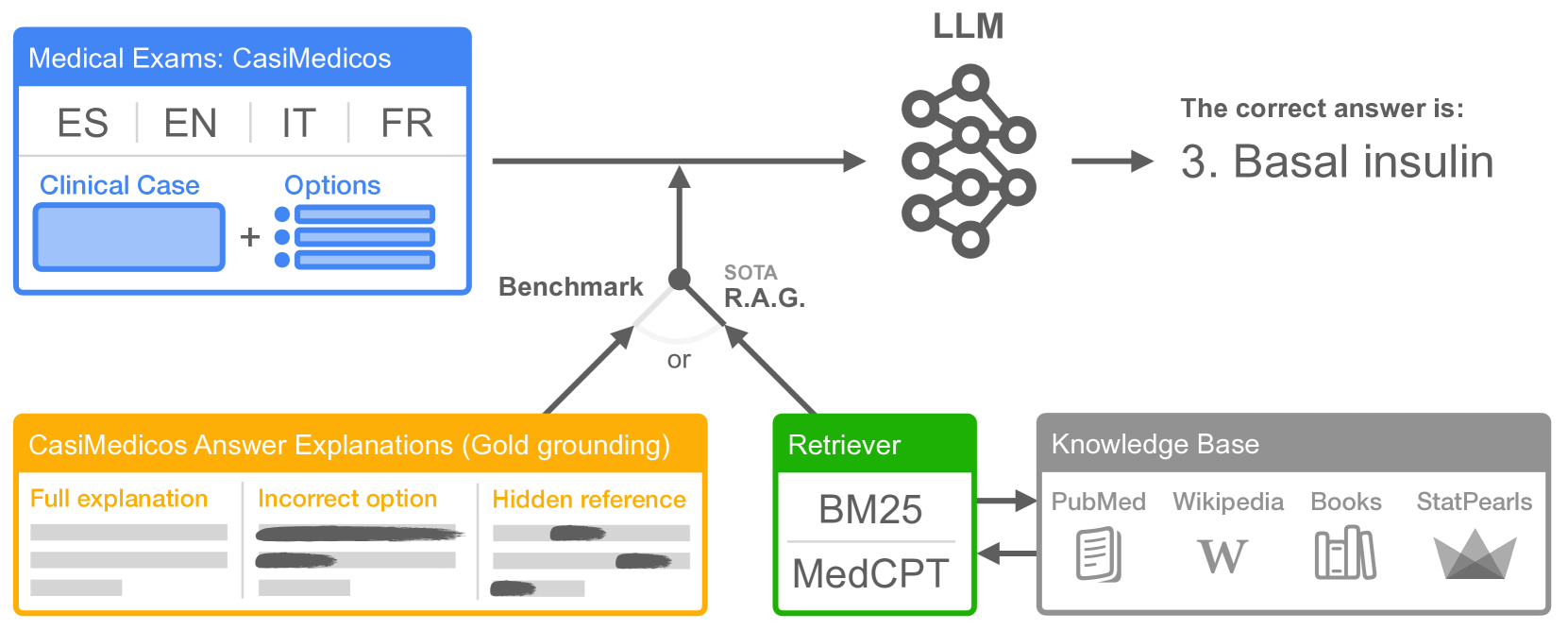
0
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
I~nigo Alonso, Maite Oronoz, Rodrigo Agerri
Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
Read more7/30/2024