DebateQA: Evaluating Question Answering on Debatable Knowledge

0

Sign in to get full access
Overview
- The paper introduces DebateQA, a dataset for evaluating question answering on topics with debatable or controversial knowledge.
- DebateQA contains 4,000 questions paired with pro and con arguments, sourced from online debate forums.
- The dataset is designed to assess a model's ability to handle nuanced, subjective topics beyond just factual knowledge.
Plain English Explanation
The researchers created a new dataset called DebateQA to test how well AI language models can handle questions on controversial or debatable topics. Unlike typical question-answering datasets that focus on objective facts, DebateQA contains questions paired with arguments on both sides of the debate.
For example, a question in DebateQA might be "Should the government provide universal healthcare?". The dataset contains detailed pro and con arguments that a model would need to understand to provide a nuanced response, rather than just a simple yes or no answer.
The goal is to push AI systems beyond just reciting facts, and evaluate their ability to engage with complex, subjective topics where there may not be a single right answer. DebateQA provides a new benchmark to measure how well language models can handle these types of ambiguous, debatable questions.
Technical Explanation
The researchers constructed the DebateQA dataset by extracting questions and corresponding pro and con arguments from online debate forums. The dataset contains 4,000 unique questions, each paired with multiple paragraphs of text laying out the key points on both sides of the debate.
The questions cover a wide range of topics, including ethics, politics, science, and philosophy. The arguments are sourced from high-quality online debate platforms, ensuring the content is substantive and representative of real-world debates.
To evaluate models on DebateQA, the researchers propose several task setups, such as:
- Answering the original question based on the pro and con arguments
- Generating a counterargument to a given stance
- Assessing the overall quality and persuasiveness of the arguments
These tasks are designed to go beyond simple fact retrieval, and instead require models to demonstrate reasoning, nuance, and an understanding of different perspectives on debatable topics.
Critical Analysis
The DebateQA dataset represents an important step forward in benchmarking question answering capabilities, particularly for language models that aspire to engage with complex, ambiguous topics.
One potential limitation is the dataset's reliance on arguments from online debate forums, which may not always represent the full breadth of perspectives on a given issue. The researchers acknowledge this and suggest further work to expand the dataset with arguments from diverse sources.
Additionally, while DebateQA pushes models to handle more subjective questions, there are still open questions about how to best evaluate the quality and persuasiveness of model outputs on these types of tasks. The researchers propose several metrics, but more research is needed to develop robust and reliable evaluation frameworks.
Overall, DebateQA is a valuable new resource for the AI research community, and the tasks it enables could lead to important advancements in building language models that can engage with the nuances of debatable knowledge.
Conclusion
The DebateQA dataset introduces a new benchmark for evaluating question answering systems on topics with debatable or controversial knowledge. By pairing questions with pro and con arguments, the dataset challenges models to move beyond simple fact retrieval and engage with complex, subjective topics.
Successfully tackling the DebateQA tasks could pave the way for language models that are better equipped to handle the ambiguity and diversity of real-world knowledge. As AI systems become more integrated into our daily lives, developing this kind of nuanced reasoning capability will be increasingly important.
The DebateQA dataset represents an exciting step forward in AI evaluation, and the insights gained from this research could have broad implications for the development of more capable and trustworthy language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DebateQA: Evaluating Question Answering on Debatable Knowledge
Rongwu Xu, Xuan Qi, Zehan Qi, Wei Xu, Zhijiang Guo
The rise of large language models (LLMs) has enabled us to seek answers to inherently debatable questions on LLM chatbots, necessitating a reliable way to evaluate their ability. However, traditional QA benchmarks assume fixed answers are inadequate for this purpose. To address this, we introduce DebateQA, a dataset of 2,941 debatable questions, each accompanied by multiple human-annotated partial answers that capture a variety of perspectives. We develop two metrics: Perspective Diversity, which evaluates the comprehensiveness of perspectives, and Dispute Awareness, which assesses if the LLM acknowledges the question's debatable nature. Experiments demonstrate that both metrics align with human preferences and are stable across different underlying models. Using DebateQA with two metrics, we assess 12 popular LLMs and retrieval-augmented generation methods. Our findings reveal that while LLMs generally excel at recognizing debatable issues, their ability to provide comprehensive answers encompassing diverse perspectives varies considerably.
Read more8/6/2024

0
Evaluating the Performance of Large Language Models via Debates
Behrad Moniri, Hamed Hassani, Edgar Dobriban
Large Language Models (LLMs) are rapidly evolving and impacting various fields, necessitating the development of effective methods to evaluate and compare their performance. Most current approaches for performance evaluation are either based on fixed, domain-specific questions that lack the flexibility required in many real-world applications where tasks are not always from a single domain, or rely on human input, making them unscalable. We propose an automated benchmarking framework based on debates between LLMs, judged by another LLM. This method assesses not only domain knowledge, but also skills such as problem definition and inconsistency recognition. We evaluate the performance of various state-of-the-art LLMs using the debate framework and achieve rankings that align closely with popular rankings based on human input, eliminating the need for costly human crowdsourcing.
Read more6/18/2024
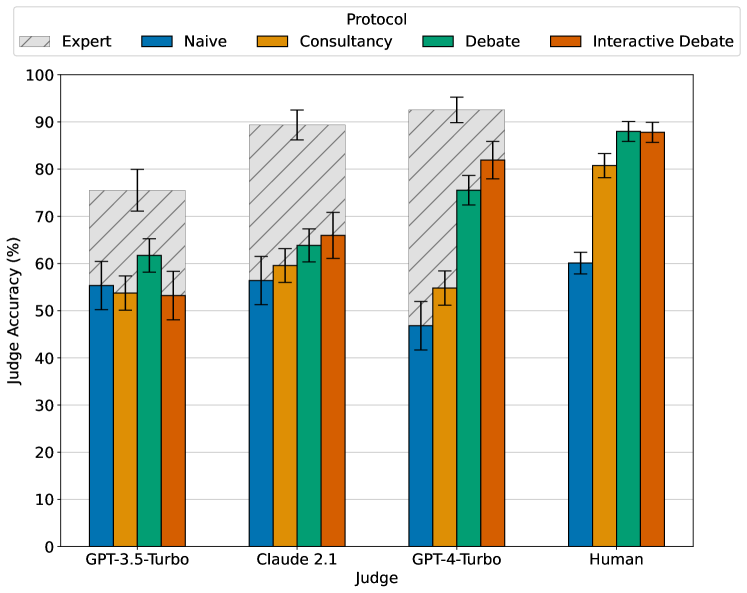
0
Debating with More Persuasive LLMs Leads to More Truthful Answers
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R. Bowman, Tim Rocktaschel, Ethan Perez
Common methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is debate, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76% and 88% accuracy respectively (naive baselines obtain 48% and 60%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth.
Read more7/29/2024

0
Revolutionizing Database Q&A with Large Language Models: Comprehensive Benchmark and Evaluation
Yihang Zheng, Bo Li, Zhenghao Lin, Yi Luo, Xuanhe Zhou, Chen Lin, Jinsong Su, Guoliang Li, Shifu Li
The development of Large Language Models (LLMs) has revolutionized Q&A across various industries, including the database domain. However, there is still a lack of a comprehensive benchmark to evaluate the capabilities of different LLMs and their modular components in database Q&A. To this end, we introduce DQA, the first comprehensive database Q&A benchmark. DQA features an innovative LLM-based method for automating the generation, cleaning, and rewriting of database Q&A, resulting in over 240,000 Q&A pairs in English and Chinese. These Q&A pairs cover nearly all aspects of database knowledge, including database manuals, database blogs, and database tools. This inclusion allows for additional assessment of LLMs' Retrieval-Augmented Generation (RAG) and Tool Invocation Generation (TIG) capabilities in the database Q&A task. Furthermore, we propose a comprehensive LLM-based database Q&A testbed on DQA. This testbed is highly modular and scalable, with both basic and advanced components like Question Classification Routing (QCR), RAG, TIG, and Prompt Template Engineering (PTE). Besides, DQA provides a complete evaluation pipeline, featuring diverse metrics and a standardized evaluation process to ensure comprehensiveness, accuracy, and fairness. We use DQA to evaluate the database Q&A capabilities under the proposed testbed comprehensively. The evaluation reveals findings like (i) the strengths and limitations of nine different LLM-based Q&A bots and (ii) the performance impact and potential improvements of various service components (e.g., QCR, RAG, TIG). We hope our benchmark and findings will better guide the future development of LLM-based database Q&A research.
Read more9/10/2024