RGNet: A Unified Clip Retrieval and Grounding Network for Long Videos

0

Sign in to get full access
Overview
- This paper presents RGNet, a unified model for video retrieval and temporal grounding of text queries in long videos.
- RGNet leverages both global and local video features to effectively retrieve relevant videos and locate the exact temporal segments that match the query.
- The proposed approach outperforms state-of-the-art methods on benchmark video retrieval and temporal grounding tasks.
Plain English Explanation
RGNet is a machine learning model that can help you find the specific parts of long videos that are relevant to your text queries. For example, if you have a long video about making a cake, and you want to find the part where the chef adds the eggs, RGNet could automatically locate that segment for you.
Traditional video search and grounding models often struggle with long videos, as they typically focus on global video features or only consider local temporal information. In contrast, RGNet: A Unified Retrieval and Grounding Network for Long Videos combines both global and local video features to better understand the overall context and the specific details that match the text query.
By using this innovative approach, RGNet can more accurately identify the relevant video segments, making it a powerful tool for applications like video indexing, video-based question answering, and video summarization.
Technical Explanation
RGNet: A Unified Retrieval and Grounding Network for Long Videos proposes a novel deep learning architecture that addresses the challenges of long video temporal grounding and video retrieval.
The key components of RGNet include:
- Global Video Encoder: This module encodes the entire video into a global feature representation, capturing the overall context and semantic information.
- Local Video Encoder: This module encodes the local temporal features of the video, which are crucial for accurately locating the relevant segments.
- Query Encoder: This module encodes the text query into a feature representation that can be effectively matched with the video features.
- Retrieval and Grounding Module: This module uses the encoded video and query features to perform both video retrieval and temporal grounding, leveraging the complementary information from the global and local video representations.
The authors evaluate RGNet on benchmark datasets for video retrieval and temporal grounding, and demonstrate significant improvements over state-of-the-art methods. The model's ability to effectively combine global and local video features is a key factor in its superior performance.
Critical Analysis
The RGNet: A Unified Retrieval and Grounding Network for Long Videos paper provides a compelling approach to addressing the challenges of long video temporal grounding and video retrieval. The authors' decision to jointly model global and local video features is a well-justified and innovative solution.
However, the paper does not delve into potential limitations or areas for future research. For example, it would be interesting to explore how RGNet might handle more complex or ambiguous text queries, or how it could be extended to support multimodal queries (e.g., combining text and images).
Additionally, the paper does not provide much insight into the computational efficiency or real-world deployment considerations of the RGNet model. As these factors can be crucial for practical applications, they could be an important area for further investigation.
Overall, the RGNet: A Unified Retrieval and Grounding Network for Long Videos paper presents a strong technical contribution, but there may be opportunities to expand the analysis and explore additional research directions.
Conclusion
RGNet: A Unified Retrieval and Grounding Network for Long Videos introduces a novel deep learning architecture that effectively combines global and local video features to address the challenges of video retrieval and temporal grounding in long-form videos. By leveraging this complementary information, RGNet outperforms state-of-the-art methods on benchmark tasks, demonstrating its potential to enhance a wide range of video-based applications.
The paper's innovative approach to jointly modeling global and local video features represents an important contribution to the field of video understanding, and the results suggest that this strategy could lead to significant improvements in tasks like video indexing, video-based question answering, and video summarization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RGNet: A Unified Clip Retrieval and Grounding Network for Long Videos
Tanveer Hannan, Md Mohaiminul Islam, Thomas Seidl, Gedas Bertasius
Locating specific moments within long videos (20-120 minutes) presents a significant challenge, akin to finding a needle in a haystack. Adapting existing short video (5-30 seconds) grounding methods to this problem yields poor performance. Since most real life videos, such as those on YouTube and AR/VR, are lengthy, addressing this issue is crucial. Existing methods typically operate in two stages: clip retrieval and grounding. However, this disjoint process limits the retrieval module's fine-grained event understanding, crucial for specific moment detection. We propose RGNet which deeply integrates clip retrieval and grounding into a single network capable of processing long videos into multiple granular levels, e.g., clips and frames. Its core component is a novel transformer encoder, RG-Encoder, that unifies the two stages through shared features and mutual optimization. The encoder incorporates a sparse attention mechanism and an attention loss to model both granularity jointly. Moreover, we introduce a contrastive clip sampling technique to mimic the long video paradigm closely during training. RGNet surpasses prior methods, showcasing state-of-the-art performance on long video temporal grounding (LVTG) datasets MAD and Ego4D.
Read more7/16/2024
0
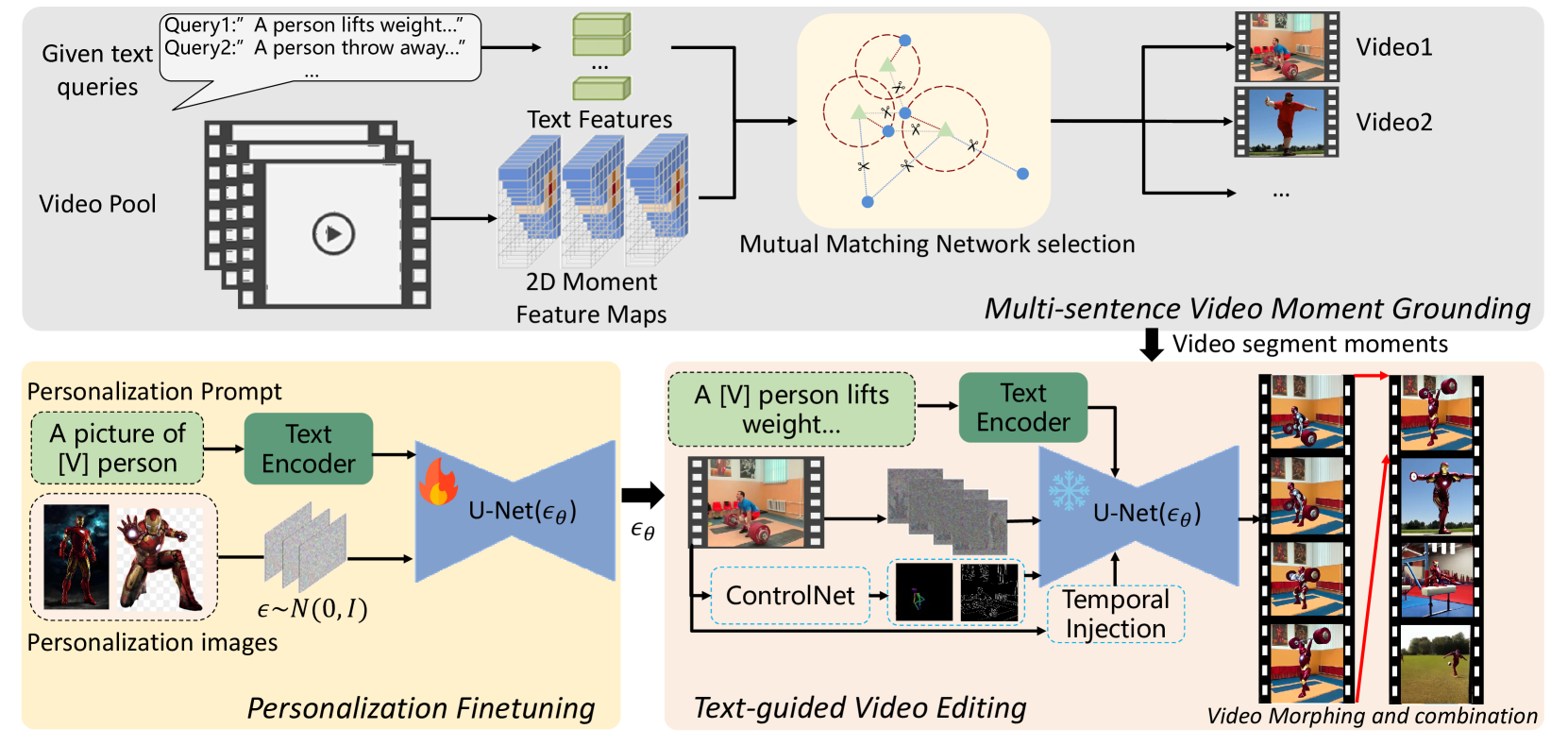
Multi-sentence Video Grounding for Long Video Generation
Wei Feng, Xin Wang, Hong Chen, Zeyang Zhang, Wenwu Zhu
Video generation has witnessed great success recently, but their application in generating long videos still remains challenging due to the difficulty in maintaining the temporal consistency of generated videos and the high memory cost during generation. To tackle the problems, in this paper, we propose a brave and new idea of Multi-sentence Video Grounding for Long Video Generation, connecting the massive video moment retrieval to the video generation task for the first time, providing a new paradigm for long video generation. The method of our work can be summarized as three steps: (i) We design sequential scene text prompts as the queries for video grounding, utilizing the massive video moment retrieval to search for video moment segments that meet the text requirements in the video database. (ii) Based on the source frames of retrieved video moment segments, we adopt video editing methods to create new video content while preserving the temporal consistency of the retrieved video. Since the editing can be conducted segment by segment, and even frame by frame, it largely reduces the memory cost. (iii) We also attempt video morphing and personalized generation methods to improve the subject consistency of long video generation, providing ablation experimental results for the subtasks of long video generation. Our approach seamlessly extends the development in image/video editing, video morphing and personalized generation, and video grounding to the long video generation, offering effective solutions for generating long videos at low memory cost.
Read more7/19/2024
0
$R^2$-Tuning: Efficient Image-to-Video Transfer Learning for Video Temporal Grounding
Ye Liu, Jixuan He, Wanhua Li, Junsik Kim, Donglai Wei, Hanspeter Pfister, Chang Wen Chen
Video temporal grounding (VTG) is a fine-grained video understanding problem that aims to ground relevant clips in untrimmed videos given natural language queries. Most existing VTG models are built upon frame-wise final-layer CLIP features, aided by additional temporal backbones (e.g., SlowFast) with sophisticated temporal reasoning mechanisms. In this work, we claim that CLIP itself already shows great potential for fine-grained spatial-temporal modeling, as each layer offers distinct yet useful information under different granularity levels. Motivated by this, we propose Reversed Recurrent Tuning ($R^2$-Tuning), a parameter- and memory-efficient transfer learning framework for video temporal grounding. Our method learns a lightweight $R^2$ Block containing only 1.5% of the total parameters to perform progressive spatial-temporal modeling. Starting from the last layer of CLIP, $R^2$ Block recurrently aggregates spatial features from earlier layers, then refines temporal correlation conditioning on the given query, resulting in a coarse-to-fine scheme. $R^2$-Tuning achieves state-of-the-art performance across three VTG tasks (i.e., moment retrieval, highlight detection, and video summarization) on six public benchmarks (i.e., QVHighlights, Charades-STA, Ego4D-NLQ, TACoS, YouTube Highlights, and TVSum) even without the additional backbone, demonstrating the significance and effectiveness of the proposed scheme. Our code is available at https://github.com/yeliudev/R2-Tuning.
Read more7/23/2024
↗️
0
Correlation-Guided Query-Dependency Calibration for Video Temporal Grounding
WonJun Moon, Sangeek Hyun, SuBeen Lee, Jae-Pil Heo
Temporal Grounding is to identify specific moments or highlights from a video corresponding to textual descriptions. Typical approaches in temporal grounding treat all video clips equally during the encoding process regardless of their semantic relevance with the text query. Therefore, we propose Correlation-Guided DEtection TRansformer (CG-DETR), exploring to provide clues for query-associated video clips within the cross-modal attention. First, we design an adaptive cross-attention with dummy tokens. Dummy tokens conditioned by text query take portions of the attention weights, preventing irrelevant video clips from being represented by the text query. Yet, not all words equally inherit the text query's correlation to video clips. Thus, we further guide the cross-attention map by inferring the fine-grained correlation between video clips and words. We enable this by learning a joint embedding space for high-level concepts, i.e., moment and sentence level, and inferring the clip-word correlation. Lastly, we exploit the moment-specific characteristics and combine them with the context of each video to form a moment-adaptive saliency detector. By exploiting the degrees of text engagement in each video clip, it precisely measures the highlightness of each clip. CG-DETR achieves state-of-the-art results on various benchmarks for temporal grounding. Codes are available at https://github.com/wjun0830/CGDETR.
Read more7/8/2024