Multi-sentence Video Grounding for Long Video Generation

0
Sign in to get full access
Overview
- The paper focuses on the task of multi-sentence video grounding, which aims to generate long videos based on multiple sentences of text.
- The authors propose a novel approach called VideoDirectorGPT that leverages temporally global textual knowledge to generate consistent multi-scene videos.
- The paper also introduces the RGNet model, a unified CLIP-based retrieval and grounding network for long video understanding.
- Additionally, the authors introduce the ViMi dataset, a large-scale multi-sentence video grounding dataset, and the DrVideo dataset for long video understanding.
Plain English Explanation
The paper focuses on the challenge of generating long videos from multiple sentences of text. This task, called multi-sentence video grounding, is important for applications like movie production, where a script needs to be translated into a coherent video.
The authors propose a new approach called VideoDirectorGPT that aims to generate consistent multi-scene videos by leveraging temporally global textual knowledge. This means the model considers the overall context of the text, not just individual sentences, to produce videos that flow naturally from one scene to the next.
The paper also introduces a new model called RGNet, which is a unified system for both retrieving relevant video clips and grounding them to the input text. This allows the system to understand long videos and match them to the text descriptions.
To support this research, the authors created two new datasets: ViMi, a large-scale multi-sentence video grounding dataset, and DrVideo, a dataset for long video understanding. These resources will help advance research in this area.
Technical Explanation
The paper proposes a novel approach called VideoDirectorGPT for the task of multi-sentence video grounding. VideoDirectorGPT leverages temporally global textual knowledge to generate consistent multi-scene videos from text descriptions.
The authors also introduce the RGNet model, a unified CLIP-based retrieval and grounding network for long video understanding. RGNet can both retrieve relevant video clips and ground them to the input text, enabling a more comprehensive understanding of long videos.
To support this research, the authors created two new datasets: ViMi, a large-scale multi-sentence video grounding dataset, and DrVideo, a dataset for long video understanding. These resources will help advance research in this area.
Critical Analysis
The paper addresses an important challenge in video generation by focusing on the task of multi-sentence video grounding. The authors' proposed approaches, including VideoDirectorGPT and RGNet, offer novel solutions to generating consistent multi-scene videos and understanding long video content.
One potential limitation of the research is the reliance on large-scale datasets, which may be difficult to obtain or replicate in other domains. The authors acknowledge this challenge and emphasize the need for further work to improve the generalization of these models.
Additionally, the paper does not provide a detailed analysis of the computational complexity or inference time of the proposed models. This information would be useful for evaluating the practical applicability of the methods, especially for real-time or resource-constrained applications.
Overall, the paper presents promising advances in the field of video generation and understanding, and the new datasets introduced will likely spur further research in this area. However, additional work is needed to address the potential limitations and improve the robustness and efficiency of the techniques.
Conclusion
This paper tackles the challenge of multi-sentence video grounding, which is crucial for applications like movie production where scripts need to be translated into coherent videos. The authors propose novel approaches, including VideoDirectorGPT and RGNet, that leverage temporally global textual knowledge and a unified retrieval and grounding network to generate consistent multi-scene videos and understand long video content.
The introduction of the ViMi and DrVideo datasets will further advance research in this area, enabling more comprehensive evaluation and development of video generation and understanding models. While the paper presents promising results, there are still opportunities for improving the generalization and efficiency of these techniques, which could lead to more practical and widely applicable solutions in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-sentence Video Grounding for Long Video Generation
Wei Feng, Xin Wang, Hong Chen, Zeyang Zhang, Wenwu Zhu
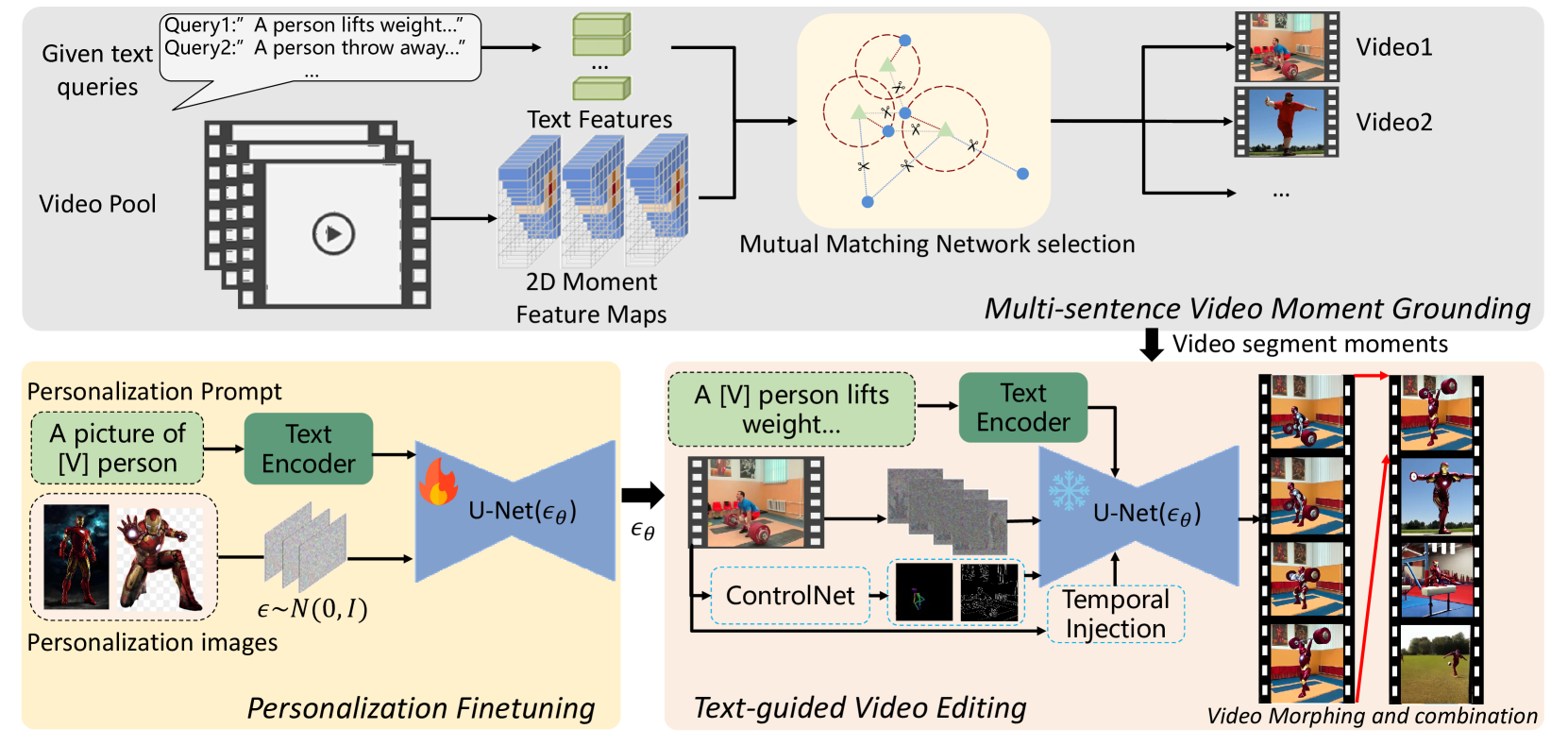
Video generation has witnessed great success recently, but their application in generating long videos still remains challenging due to the difficulty in maintaining the temporal consistency of generated videos and the high memory cost during generation. To tackle the problems, in this paper, we propose a brave and new idea of Multi-sentence Video Grounding for Long Video Generation, connecting the massive video moment retrieval to the video generation task for the first time, providing a new paradigm for long video generation. The method of our work can be summarized as three steps: (i) We design sequential scene text prompts as the queries for video grounding, utilizing the massive video moment retrieval to search for video moment segments that meet the text requirements in the video database. (ii) Based on the source frames of retrieved video moment segments, we adopt video editing methods to create new video content while preserving the temporal consistency of the retrieved video. Since the editing can be conducted segment by segment, and even frame by frame, it largely reduces the memory cost. (iii) We also attempt video morphing and personalized generation methods to improve the subject consistency of long video generation, providing ablation experimental results for the subtasks of long video generation. Our approach seamlessly extends the development in image/video editing, video morphing and personalized generation, and video grounding to the long video generation, offering effective solutions for generating long videos at low memory cost.
Read more7/19/2024
0
Multi-Sentence Grounding for Long-term Instructional Video
Zeqian Li, Qirui Chen, Tengda Han, Ya Zhang, Yanfeng Wang, Weidi Xie
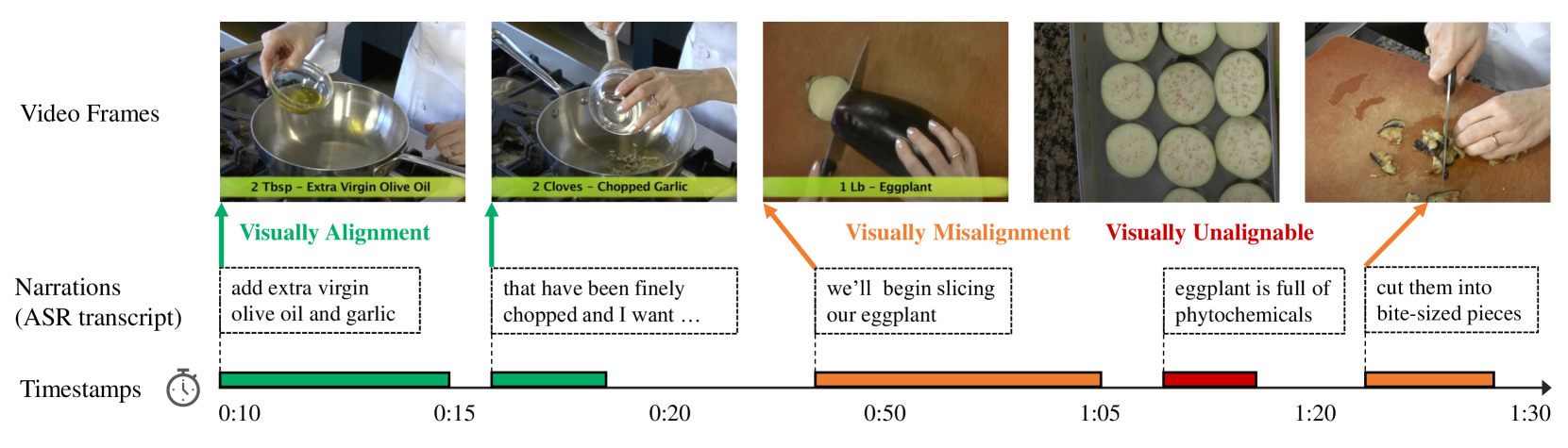
In this paper, we aim to establish an automatic, scalable pipeline for denoising the large-scale instructional dataset and construct a high-quality video-text dataset with multiple descriptive steps supervision, named HowToStep. We make the following contributions: (i) improving the quality of sentences in dataset by upgrading ASR systems to reduce errors from speech recognition and prompting a large language model to transform noisy ASR transcripts into descriptive steps; (ii) proposing a Transformer-based architecture with all texts as queries, iteratively attending to the visual features, to temporally align the generated steps to corresponding video segments. To measure the quality of our curated datasets, we train models for the task of multi-sentence grounding on it, i.e., given a long-form video, and associated multiple sentences, to determine their corresponding timestamps in the video simultaneously, as a result, the model shows superior performance on a series of multi-sentence grounding tasks, surpassing existing state-of-the-art methods by a significant margin on three public benchmarks, namely, 9.0% on HT-Step, 5.1% on HTM-Align and 1.9% on CrossTask. All codes, models, and the resulting dataset have been publicly released.
Read more7/23/2024
0
Video sentence grounding with temporally global textual knowledge
Cai Chen, Runzhong Zhang, Jianjun Gao, Kejun Wu, Kim-Hui Yap, Yi Wang
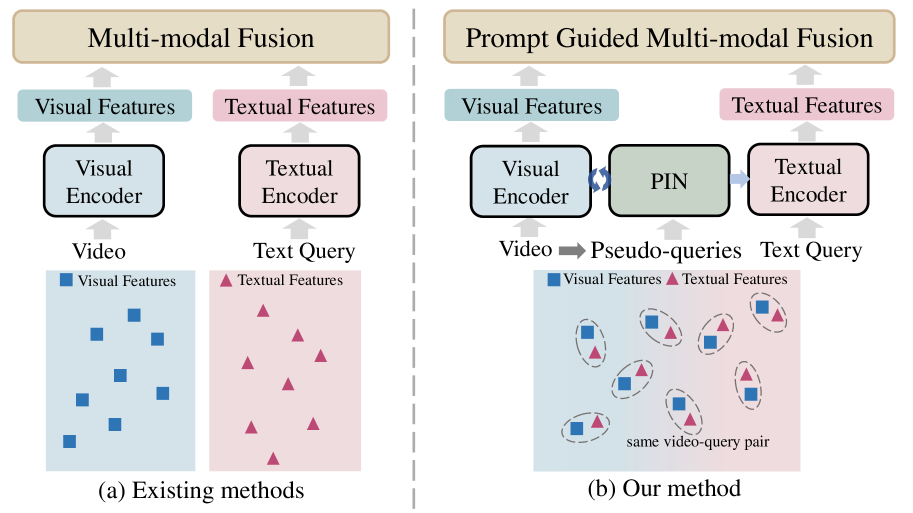
Temporal sentence grounding involves the retrieval of a video moment with a natural language query. Many existing works directly incorporate the given video and temporally localized query for temporal grounding, overlooking the inherent domain gap between different modalities. In this paper, we utilize pseudo-query features containing extensive temporally global textual knowledge sourced from the same video-query pair, to enhance the bridging of domain gaps and attain a heightened level of similarity between multi-modal features. Specifically, we propose a Pseudo-query Intermediary Network (PIN) to achieve an improved alignment of visual and comprehensive pseudo-query features within the feature space through contrastive learning. Subsequently, we utilize learnable prompts to encapsulate the knowledge of pseudo-queries, propagating them into the textual encoder and multi-modal fusion module, further enhancing the feature alignment between visual and language for better temporal grounding. Extensive experiments conducted on the Charades-STA and ActivityNet-Captions datasets demonstrate the effectiveness of our method.
Read more6/4/2024
🛸
0
VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning
Han Lin, Abhay Zala, Jaemin Cho, Mohit Bansal
Recent text-to-video (T2V) generation methods have seen significant advancements. However, the majority of these works focus on producing short video clips of a single event (i.e., single-scene videos). Meanwhile, recent large language models (LLMs) have demonstrated their capability in generating layouts and programs to control downstream visual modules. This prompts an important question: can we leverage the knowledge embedded in these LLMs for temporally consistent long video generation? In this paper, we propose VideoDirectorGPT, a novel framework for consistent multi-scene video generation that uses the knowledge of LLMs for video content planning and grounded video generation. Specifically, given a single text prompt, we first ask our video planner LLM (GPT-4) to expand it into a 'video plan', which includes the scene descriptions, the entities with their respective layouts, the background for each scene, and consistency groupings of the entities. Next, guided by this video plan, our video generator, named Layout2Vid, has explicit control over spatial layouts and can maintain temporal consistency of entities across multiple scenes, while being trained only with image-level annotations. Our experiments demonstrate that our proposed VideoDirectorGPT framework substantially improves layout and movement control in both single- and multi-scene video generation and can generate multi-scene videos with consistency, while achieving competitive performance with SOTAs in open-domain single-scene T2V generation. Detailed ablation studies, including dynamic adjustment of layout control strength with an LLM and video generation with user-provided images, confirm the effectiveness of each component of our framework and its future potential.
Read more7/16/2024