Riemann-based Multi-scale Attention Reasoning Network for Text-3D Retrieval

0

Sign in to get full access
Overview
- This paper presents a novel Riemann-based Multi-scale Attention Reasoning Network (RM-ARN) for text-to-3D retrieval.
- The proposed model leverages Riemann geometry to capture the multi-scale hierarchical structure of 3D data and attention mechanisms to reason about the semantic relationship between text and 3D shapes.
- The authors demonstrate the effectiveness of RM-ARN on several text-to-3D retrieval benchmarks, outperforming state-of-the-art methods.
Plain English Explanation
The paper introduces a new way to match text descriptions with 3D shapes. The key idea is to use Riemann geometry, which is a way of measuring distances and angles on curved surfaces, to capture the complex structure of 3D shapes. This allows the model to better understand the relationships between different parts of a 3D object.
The model also uses attention mechanisms, which focus on the most relevant parts of the text and 3D shape when making the match. This helps the model reason about the semantic connections between the text and the 3D shape, rather than just looking for simple visual similarities.
The authors show that this Riemann-based Multi-scale Attention Reasoning Network (RM-ARN) outperforms other state-of-the-art methods on standard text-to-3D retrieval benchmarks. This means it is better able to find the 3D shape that matches a given text description.
Technical Explanation
The RM-ARN model consists of three key components:
-
Riemann-based Multi-scale Encoder: This encodes the 3D shape into a hierarchical representation using Riemann geometry. It captures the multi-scale structure of the 3D data by computing geodesic distances between points on the shape's surface.
-
Attention-based Text Encoder: This encodes the text description using an attention mechanism that focuses on the most relevant parts of the text when matching to the 3D shape.
-
Retrieval Head: This module computes the similarity between the encoded text and 3D shape representations, allowing the model to retrieve the best matching 3D shape for a given text query.
The authors evaluate RM-ARN on several standard text-to-3D retrieval benchmarks, including ShapeNet and Scan2CAD. They show that RM-ARN outperforms previous state-of-the-art methods, demonstrating the effectiveness of their Riemann-based multi-scale reasoning approach.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated model for text-to-3D retrieval. The use of Riemann geometry to capture the multi-scale structure of 3D shapes is a novel and promising approach, as 3D data often has a complex hierarchical nature that is difficult to model effectively.
However, the paper does not explore the limitations of the RM-ARN model in depth. For example, it is unclear how the model would perform on more diverse or noisy 3D shape and text data, or how scalable the approach would be to large-scale retrieval tasks. Additionally, the paper does not discuss potential biases or ethical considerations that may arise from such text-to-3D retrieval systems.
Further research could investigate ways to make the RM-ARN model more robust and generalize better to a wider range of 3D shape and text data. Exploring the model's failure cases and limitations in more detail would also help to better understand its strengths and weaknesses.
Conclusion
The Riemann-based Multi-scale Attention Reasoning Network (RM-ARN) presented in this paper is a significant advancement in the field of text-to-3D retrieval. By leveraging Riemann geometry and attention mechanisms, the model is able to better capture the semantic relationships between text descriptions and 3D shapes, leading to improved retrieval performance on benchmark datasets.
This work highlights the potential of incorporating geometric reasoning and multi-scale representations into deep learning models for tasks involving complex 3D data. The insights from this research could inspire future work on bridging the gap between language and 3D understanding, with applications in areas like 3D-assisted design, augmented reality, and robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Riemann-based Multi-scale Attention Reasoning Network for Text-3D Retrieval
Wenrui Li, Wei Han, Yandu Chen, Yeyu Chai, Yidan Lu, Xingtao Wang, Xiaopeng Fan
Due to the challenges in acquiring paired Text-3D data and the inherent irregularity of 3D data structures, combined representation learning of 3D point clouds and text remains unexplored. In this paper, we propose a novel Riemann-based Multi-scale Attention Reasoning Network (RMARN) for text-3D retrieval. Specifically, the extracted text and point cloud features are refined by their respective Adaptive Feature Refiner (AFR). Furthermore, we introduce the innovative Riemann Local Similarity (RLS) module and the Global Pooling Similarity (GPS) module. However, as 3D point cloud data and text data often possess complex geometric structures in high-dimensional space, the proposed RLS employs a novel Riemann Attention Mechanism to reflect the intrinsic geometric relationships of the data. Without explicitly defining the manifold, RMARN learns the manifold parameters to better represent the distances between text-point cloud samples. To address the challenges of lacking paired text-3D data, we have created the large-scale Text-3D Retrieval dataset T3DR-HIT, which comprises over 3,380 pairs of text and point cloud data. T3DR-HIT contains coarse-grained indoor 3D scenes and fine-grained Chinese artifact scenes, consisting of 1,380 and over 2,000 text-3D pairs, respectively. Experiments on our custom datasets demonstrate the superior performance of the proposed method. Our code and proposed datasets are available at url{https://github.com/liwrui/RMARN}.
Read more8/27/2024

0
Reason3D: Searching and Reasoning 3D Segmentation via Large Language Model
Kuan-Chih Huang, Xiangtai Li, Lu Qi, Shuicheng Yan, Ming-Hsuan Yang
Recent advancements in multimodal large language models (LLMs) have shown their potential in various domains, especially concept reasoning. Despite these developments, applications in understanding 3D environments remain limited. This paper introduces Reason3D, a novel LLM designed for comprehensive 3D understanding. Reason3D takes point cloud data and text prompts as input to produce textual responses and segmentation masks, facilitating advanced tasks like 3D reasoning segmentation, hierarchical searching, express referring, and question answering with detailed mask outputs. Specifically, we propose a hierarchical mask decoder to locate small objects within expansive scenes. This decoder initially generates a coarse location estimate covering the object's general area. This foundational estimation facilitates a detailed, coarse-to-fine segmentation strategy that significantly enhances the precision of object identification and segmentation. Experiments validate that Reason3D achieves remarkable results on large-scale ScanNet and Matterport3D datasets for 3D express referring, 3D question answering, and 3D reasoning segmentation tasks. Code and models are available at: https://github.com/KuanchihHuang/Reason3D.
Read more5/28/2024
0
PointCloud-Text Matching: Benchmark Datasets and a Baseline
Yanglin Feng, Yang Qin, Dezhong Peng, Hongyuan Zhu, Xi Peng, Peng Hu
In this paper, we present and study a new instance-level retrieval task: PointCloud-Text Matching~(PTM), which aims to find the exact cross-modal instance that matches a given point-cloud query or text query. PTM could be applied to various scenarios, such as indoor/urban-canyon localization and scene retrieval. However, there exists no suitable and targeted dataset for PTM in practice. Therefore, we construct three new PTM benchmark datasets, namely 3D2T-SR, 3D2T-NR, and 3D2T-QA. We observe that the data is challenging and with noisy correspondence due to the sparsity, noise, or disorder of point clouds and the ambiguity, vagueness, or incompleteness of texts, which make existing cross-modal matching methods ineffective for PTM. To tackle these challenges, we propose a PTM baseline, named Robust PointCloud-Text Matching method (RoMa). RoMa consists of two modules: a Dual Attention Perception module (DAP) and a Robust Negative Contrastive Learning module (RNCL). Specifically, DAP leverages token-level and feature-level attention to adaptively focus on useful local and global features, and aggregate them into common representations, thereby reducing the adverse impact of noise and ambiguity. To handle noisy correspondence, RNCL divides negative pairs, which are much less error-prone than positive pairs, into clean and noisy subsets, and assigns them forward and reverse optimization directions respectively, thus enhancing robustness against noisy correspondence. We conduct extensive experiments on our benchmarks and demonstrate the superiority of our RoMa.
Read more9/6/2024
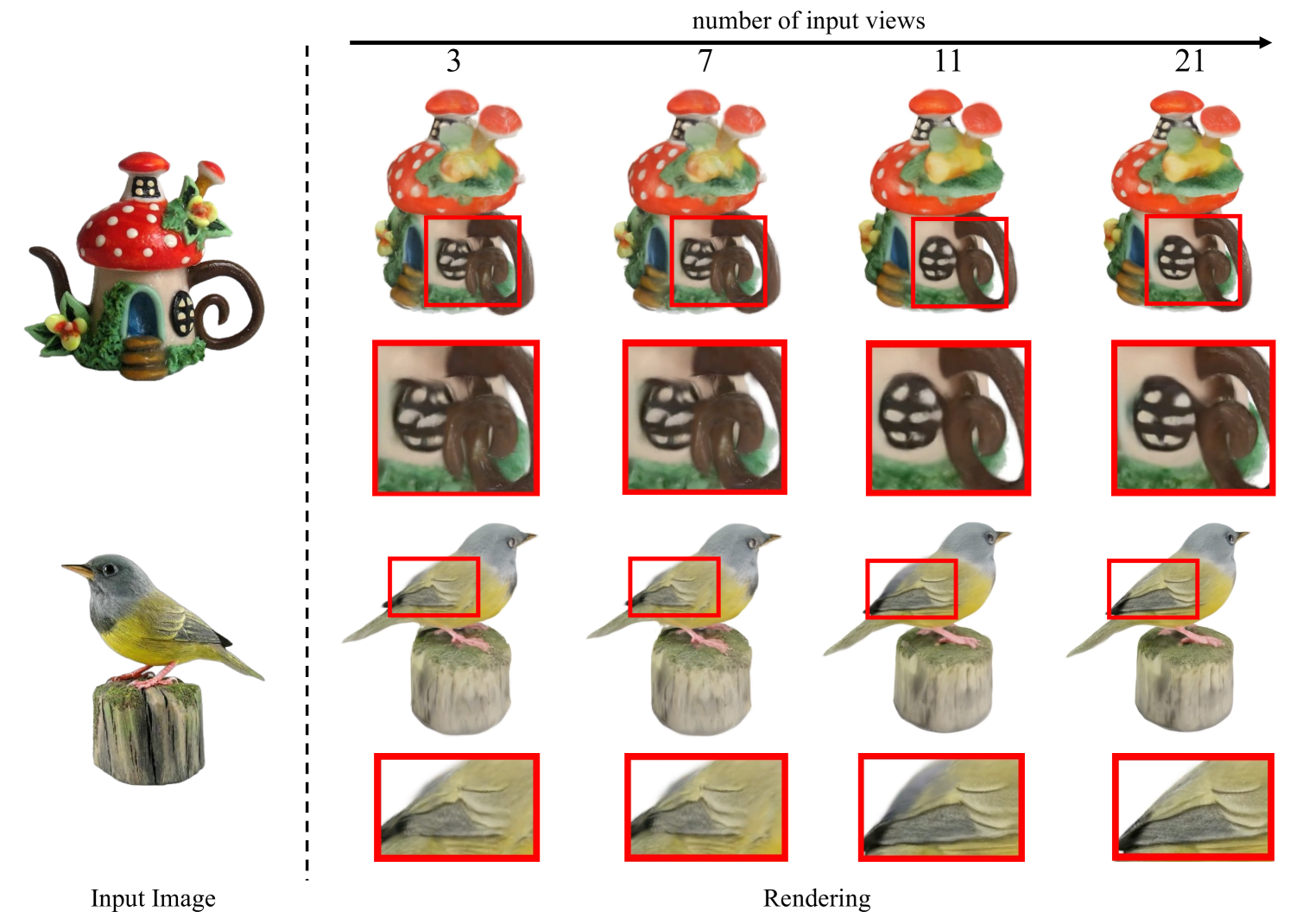
0
GeoLRM: Geometry-Aware Large Reconstruction Model for High-Quality 3D Gaussian Generation
Chubin Zhang, Hongliang Song, Yi Wei, Yu Chen, Jiwen Lu, Yansong Tang
In this work, we introduce the Geometry-Aware Large Reconstruction Model (GeoLRM), an approach which can predict high-quality assets with 512k Gaussians and 21 input images in only 11 GB GPU memory. Previous works neglect the inherent sparsity of 3D structure and do not utilize explicit geometric relationships between 3D and 2D images. This limits these methods to a low-resolution representation and makes it difficult to scale up to the dense views for better quality. GeoLRM tackles these issues by incorporating a novel 3D-aware transformer structure that directly processes 3D points and uses deformable cross-attention mechanisms to effectively integrate image features into 3D representations. We implement this solution through a two-stage pipeline: initially, a lightweight proposal network generates a sparse set of 3D anchor points from the posed image inputs; subsequently, a specialized reconstruction transformer refines the geometry and retrieves textural details. Extensive experimental results demonstrate that GeoLRM significantly outperforms existing models, especially for dense view inputs. We also demonstrate the practical applicability of our model with 3D generation tasks, showcasing its versatility and potential for broader adoption in real-world applications.
Read more6/24/2024