Right to be Forgotten in the Era of Large Language Models: Implications, Challenges, and Solutions

0

Sign in to get full access
Overview
- The paper explores the implications, challenges, and potential solutions related to the "right to be forgotten" in the context of large language models.
- It examines the tension between an individual's desire to control their online presence and the widespread use of language models that can perpetuate personal information.
- The paper considers the technical, ethical, and legal aspects of this issue, with a focus on developing practical approaches to address the right to be forgotten.
Plain English Explanation
The paper discusses a important but complex issue in the digital age: the "right to be forgotten." This refers to an individual's ability to request the removal of their personal information from online platforms and search engines.
As large language models become more prevalent, this right becomes increasingly challenging to enforce. These powerful AI systems can "remember" and reproduce information about people, even if that information is later removed from the original source.
The paper explores the implications of this problem, looking at the technical, ethical, and legal considerations. It examines how language models can perpetuate personal data, and the difficulties in getting that information removed or "forgotten."
The authors propose potential solutions, such as developing techniques for "machine unlearning" to remove specific information from language models. They also discuss the need for updated privacy regulations and ethical frameworks to address the right to be forgotten in the era of advanced AI.
Overall, the paper highlights an important issue at the intersection of technology, privacy, and individual rights. As AI systems become more powerful and ubiquitous, finding ways to protect people's ability to control their online presence will be crucial.
Technical Explanation
The paper begins by outlining the challenge of the "right to be forgotten" in the context of large language models. These AI systems are trained on vast amounts of online data, which can include personal information about individuals. Even if that information is later removed from the original sources, the language model may still retain and reproduce it.
The authors discuss various technical approaches to address this issue, including machine unlearning techniques. These methods aim to selectively remove specific information from the language model, without compromising its overall performance.
The paper also explores the ethical and legal considerations surrounding the right to be forgotten. It examines how the proliferation of language models can conflict with privacy rights and an individual's ability to control their online presence. The authors consider the need for updated regulations and frameworks to address these challenges.
Additionally, the paper discusses the potential impact of the right to be forgotten on areas like educational data mining and knowledge distillation, where the retention of personal information may be important for research or other purposes.
The authors propose a set of solutions and methodologies to address the right to be forgotten in the era of large language models. These include developing federated domain unlearning approaches, where language models can be updated to remove specific information while preserving their overall capabilities.
Critical Analysis
The paper raises important and timely concerns about the right to be forgotten in the context of large language models. The authors acknowledge the technical challenges in selectively removing personal information from these powerful AI systems, which can perpetuate data even after it has been removed from the original sources.
While the proposed solutions, such as machine unlearning and federated domain unlearning, offer promising approaches, the authors note that further research and development is needed to make these techniques practical and scalable. Additionally, the legal and ethical implications of the right to be forgotten may require more comprehensive regulatory frameworks to balance individual privacy rights with the potential societal benefits of language models.
The paper also highlights the need to consider the impact of the right to be forgotten on other domains, such as educational data mining and knowledge distillation. In these cases, the retention of certain personal information may be crucial for research or other legitimate purposes, and the authors rightly point out the need to find a balanced solution.
Overall, the paper provides a well-researched and thoughtful exploration of a complex issue that will only become more pressing as large language models continue to advance and become more ubiquitous. The authors' focus on developing practical solutions and frameworks is commendable, and their work serves as an important contribution to the ongoing discussions around privacy, AI ethics, and the rights of individuals in the digital age.
Conclusion
The paper examines the challenges and implications of the "right to be forgotten" in the era of large language models, a pressing issue at the intersection of technology, privacy, and individual rights. The authors explore technical approaches, such as machine unlearning and federated domain unlearning, to selectively remove personal information from language models, while also considering the ethical and legal aspects of this problem.
The proposed solutions and methodologies offer promising paths forward, but the authors acknowledge the need for further research and development to make these techniques scalable and practical. Additionally, the paper highlights the importance of updating regulatory frameworks to address the right to be forgotten in the context of advanced AI systems.
As large language models continue to grow in power and ubiquity, finding ways to protect an individual's ability to control their online presence will become increasingly crucial. The insights and recommendations provided in this paper contribute to the ongoing discourse on privacy, AI ethics, and the rights of individuals in the digital age.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Right to be Forgotten in the Era of Large Language Models: Implications, Challenges, and Solutions
Dawen Zhang, Pamela Finckenberg-Broman, Thong Hoang, Shidong Pan, Zhenchang Xing, Mark Staples, Xiwei Xu
The Right to be Forgotten (RTBF) was first established as the result of the ruling of Google Spain SL, Google Inc. v AEPD, Mario Costeja Gonz'alez, and was later included as the Right to Erasure under the General Data Protection Regulation (GDPR) of European Union to allow individuals the right to request personal data be deleted by organizations. Specifically for search engines, individuals can send requests to organizations to exclude their information from the query results. It was a significant emergent right as the result of the evolution of technology. With the recent development of Large Language Models (LLMs) and their use in chatbots, LLM-enabled software systems have become popular. But they are not excluded from the RTBF. Compared with the indexing approach used by search engines, LLMs store, and process information in a completely different way. This poses new challenges for compliance with the RTBF. In this paper, we explore these challenges and provide our insights on how to implement technical solutions for the RTBF, including the use of differential privacy, machine unlearning, model editing, and guardrails. With the rapid advancement of AI and the increasing need of regulating this powerful technology, learning from the case of RTBF can provide valuable lessons for technical practitioners, legal experts, organizations, and authorities.
Read more6/6/2024

0
RKLD: Reverse KL-Divergence-based Knowledge Distillation for Unlearning Personal Information in Large Language Models
Bichen Wang, Yuzhe Zi, Yixin Sun, Yanyan Zhao, Bing Qin
With the passage of the Right to Be Forgotten (RTBF) regulations and the scaling up of language model training datasets, research on model unlearning in large language models (LLMs) has become more crucial. Before the era of LLMs, machine unlearning research focused mainly on classification tasks in models with small parameters. In these tasks, the content to be forgotten or retained is clear and straightforward. However, as parameter sizes have grown and tasks have become more complex, balancing forget quality and model utility has become more challenging, especially in scenarios involving personal data instead of classification results. Existing methods based on gradient ascent and its variants often struggle with this balance, leading to unintended information loss or partial forgetting. To address this challenge, we propose RKLD, a novel textbf{R}everse textbf{KL}-Divergence-based Knowledge textbf{D}istillation unlearning algorithm for LLMs targeting the unlearning of personal information. Through RKLD, we achieve significant forget quality and effectively maintain the model utility in our experiments.
Read more6/5/2024
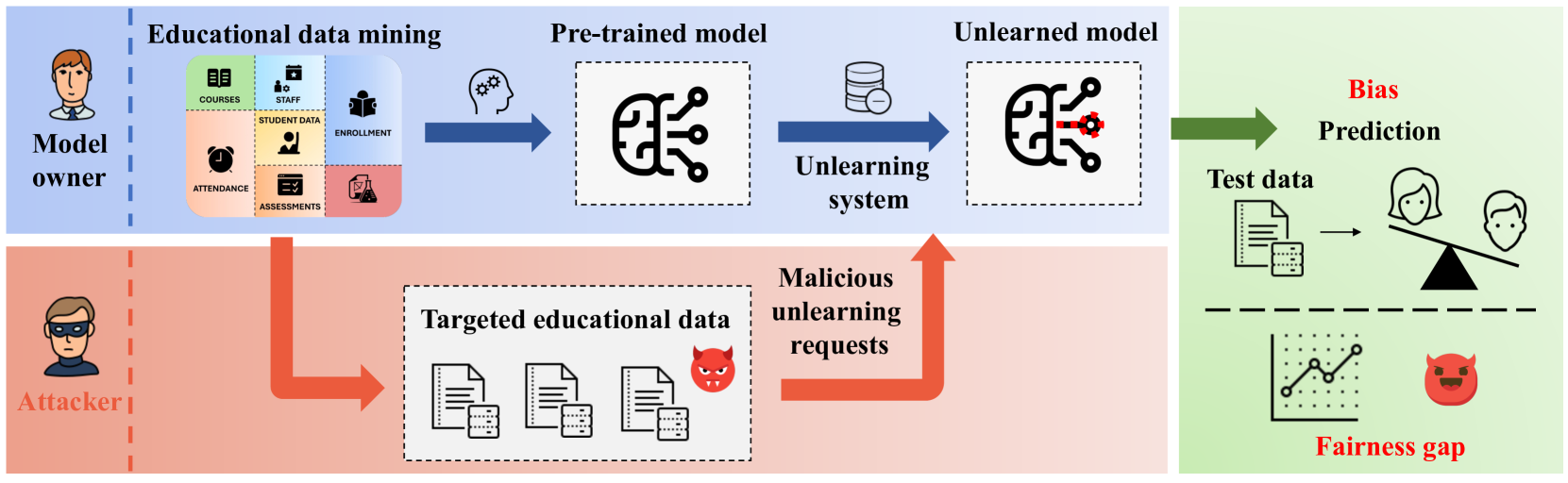
0
Exploring Fairness in Educational Data Mining in the Context of the Right to be Forgotten
Wei Qian, Aobo Chen, Chenxu Zhao, Yangyi Li, Mengdi Huai
In education data mining (EDM) communities, machine learning has achieved remarkable success in discovering patterns and structures to tackle educational challenges. Notably, fairness and algorithmic bias have gained attention in learning analytics of EDM. With the increasing demand for the right to be forgotten, there is a growing need for machine learning models to forget sensitive data and its impact, particularly within the realm of EDM. The paradigm of selective forgetting, also known as machine unlearning, has been extensively studied to address this need by eliminating the influence of specific data from a pre-trained model without complete retraining. However, existing research assumes that interactive data removal operations are conducted in secure and reliable environments, neglecting potential malicious unlearning requests to undermine the fairness of machine learning systems. In this paper, we introduce a novel class of selective forgetting attacks designed to compromise the fairness of learning models while maintaining their predictive accuracy, thereby preventing the model owner from detecting the degradation in model performance. Additionally, we propose an innovative optimization framework for selective forgetting attacks, capable of generating malicious unlearning requests across various attack scenarios. We validate the effectiveness of our proposed selective forgetting attacks on fairness through extensive experiments using diverse EDM datasets.
Read more5/30/2024

0
Machine Unlearning for Document Classification
Lei Kang, Mohamed Ali Souibgui, Fei Yang, Lluis Gomez, Ernest Valveny, Dimosthenis Karatzas
Document understanding models have recently demonstrated remarkable performance by leveraging extensive collections of user documents. However, since documents often contain large amounts of personal data, their usage can pose a threat to user privacy and weaken the bonds of trust between humans and AI services. In response to these concerns, legislation advocating ``the right to be forgotten has recently been proposed, allowing users to request the removal of private information from computer systems and neural network models. A novel approach, known as machine unlearning, has emerged to make AI models forget about a particular class of data. In our research, we explore machine unlearning for document classification problems, representing, to the best of our knowledge, the first investigation into this area. Specifically, we consider a realistic scenario where a remote server houses a well-trained model and possesses only a small portion of training data. This setup is designed for efficient forgetting manipulation. This work represents a pioneering step towards the development of machine unlearning methods aimed at addressing privacy concerns in document analysis applications. Our code is publicly available at url{https://github.com/leitro/MachineUnlearning-DocClassification}.
Read more5/1/2024