Exploring Fairness in Educational Data Mining in the Context of the Right to be Forgotten

0
Sign in to get full access
Overview
- Explores the concept of fairness in educational data mining, particularly in the context of the "right to be forgotten"
- Examines how selective forgetting can impact the fairness of machine learning models in educational settings
- Discusses the potential tensions between the right to be forgotten and the need for accurate and unbiased educational data
Plain English Explanation
The paper explores the idea of fairness in educational data mining, which is the process of analyzing data collected from educational settings to improve teaching and learning. The researchers are particularly interested in how the "right to be forgotten" - the idea that people should be able to remove their personal information from online records - can impact the fairness of the machine learning models used in educational data mining.
The researchers explain that when students exercise their right to be forgotten and have some of their data removed, it can introduce biases into the machine learning models used to make decisions about things like admissions, grading, and student support. This is because the models are no longer trained on a fully representative dataset, and may end up making unfair or inaccurate decisions as a result.
At the same time, the researchers acknowledge the importance of the right to be forgotten, as it helps protect students' privacy and gives them more control over their personal information. The challenge is finding the right balance between preserving fairness in educational data mining and respecting students' right to be forgotten.
Technical Explanation
The paper explores the tension between the right to be forgotten and the need for fair and accurate educational data mining. The researchers present a framework for understanding the impact of selective forgetting on the fairness of machine learning models in educational settings.
They discuss how the removal of certain data points, as a result of the right to be forgotten, can introduce biases into the models and lead to unfair predictions or decisions. The researchers also explore different techniques for preserving fairness in the face of selective forgetting, such as model unlearning and fairness-aware data preprocessing.
The paper presents a comprehensive review of the existing research in this area and highlights the importance of balancing privacy rights with the need for fair and accurate educational data mining.
Critical Analysis
The paper provides a thoughtful examination of an important issue at the intersection of educational data mining and privacy rights. The researchers acknowledge the valid concerns around the right to be forgotten and the need to protect student privacy, while also highlighting the potential challenges this poses for maintaining fairness in educational algorithms.
One limitation of the paper is that it does not provide specific case studies or empirical data to illustrate the impact of selective forgetting on educational data mining models. While the theoretical framework is well-developed, more concrete examples would help readers better understand the practical implications of this issue.
Additionally, the paper could have delved deeper into the ethical considerations surrounding the trade-offs between privacy and fairness in this context. For example, it could have explored whether certain types of educational decisions (e.g., admissions) should be held to higher standards of fairness than others (e.g., personalized learning recommendations).
Overall, the paper provides a valuable contribution to the ongoing discussion around the responsible development and deployment of educational data mining technologies. By highlighting the nuances of this issue, it encourages readers to think critically about the complex social and ethical implications of these emerging tools.
Conclusion
This paper explores the important and challenging intersection of fairness in educational data mining and the right to be forgotten. It presents a framework for understanding how selective forgetting can introduce biases and unfairness into machine learning models used in educational settings.
The researchers acknowledge the valid privacy concerns that underpin the right to be forgotten, while also emphasizing the need to maintain fair and accurate educational data mining practices. By highlighting this tension, the paper encourages further research and discussion on how to best balance these competing priorities in a way that serves the interests of both students and educational institutions.
As educational data mining continues to evolve, this paper serves as a valuable resource for researchers, policymakers, and practitioners who are grappling with the complex ethical and technical challenges involved in developing fair and responsible technologies for the education sector.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Fairness in Educational Data Mining in the Context of the Right to be Forgotten
Wei Qian, Aobo Chen, Chenxu Zhao, Yangyi Li, Mengdi Huai
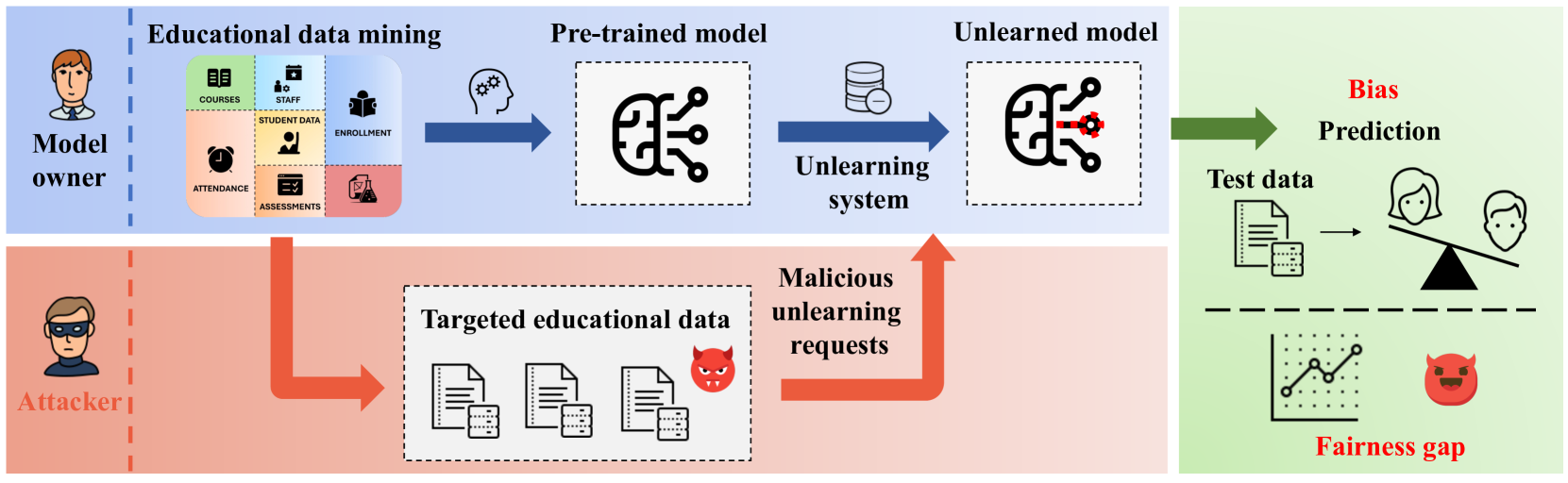
In education data mining (EDM) communities, machine learning has achieved remarkable success in discovering patterns and structures to tackle educational challenges. Notably, fairness and algorithmic bias have gained attention in learning analytics of EDM. With the increasing demand for the right to be forgotten, there is a growing need for machine learning models to forget sensitive data and its impact, particularly within the realm of EDM. The paradigm of selective forgetting, also known as machine unlearning, has been extensively studied to address this need by eliminating the influence of specific data from a pre-trained model without complete retraining. However, existing research assumes that interactive data removal operations are conducted in secure and reliable environments, neglecting potential malicious unlearning requests to undermine the fairness of machine learning systems. In this paper, we introduce a novel class of selective forgetting attacks designed to compromise the fairness of learning models while maintaining their predictive accuracy, thereby preventing the model owner from detecting the degradation in model performance. Additionally, we propose an innovative optimization framework for selective forgetting attacks, capable of generating malicious unlearning requests across various attack scenarios. We validate the effectiveness of our proposed selective forgetting attacks on fairness through extensive experiments using diverse EDM datasets.
Read more5/30/2024

0
Machine Unlearning for Document Classification
Lei Kang, Mohamed Ali Souibgui, Fei Yang, Lluis Gomez, Ernest Valveny, Dimosthenis Karatzas
Document understanding models have recently demonstrated remarkable performance by leveraging extensive collections of user documents. However, since documents often contain large amounts of personal data, their usage can pose a threat to user privacy and weaken the bonds of trust between humans and AI services. In response to these concerns, legislation advocating ``the right to be forgotten has recently been proposed, allowing users to request the removal of private information from computer systems and neural network models. A novel approach, known as machine unlearning, has emerged to make AI models forget about a particular class of data. In our research, we explore machine unlearning for document classification problems, representing, to the best of our knowledge, the first investigation into this area. Specifically, we consider a realistic scenario where a remote server houses a well-trained model and possesses only a small portion of training data. This setup is designed for efficient forgetting manipulation. This work represents a pioneering step towards the development of machine unlearning methods aimed at addressing privacy concerns in document analysis applications. Our code is publicly available at url{https://github.com/leitro/MachineUnlearning-DocClassification}.
Read more5/1/2024
⛏️
0
Machine Unlearning: A Comprehensive Survey
Weiqi Wang, Zhiyi Tian, Chenhan Zhang, Shui Yu
As the right to be forgotten has been legislated worldwide, many studies attempt to design unlearning mechanisms to protect users' privacy when they want to leave machine learning service platforms. Specifically, machine unlearning is to make a trained model to remove the contribution of an erased subset of the training dataset. This survey aims to systematically classify a wide range of machine unlearning and discuss their differences, connections and open problems. We categorize current unlearning methods into four scenarios: centralized unlearning, distributed and irregular data unlearning, unlearning verification, and privacy and security issues in unlearning. Since centralized unlearning is the primary domain, we use two parts to introduce: firstly, we classify centralized unlearning into exact unlearning and approximate unlearning; secondly, we offer a detailed introduction to the techniques of these methods. Besides the centralized unlearning, we notice some studies about distributed and irregular data unlearning and introduce federated unlearning and graph unlearning as the two representative directions. After introducing unlearning methods, we review studies about unlearning verification. Moreover, we consider the privacy and security issues essential in machine unlearning and organize the latest related literature. Finally, we discuss the challenges of various unlearning scenarios and address the potential research directions.
Read more7/26/2024

0
Gone but Not Forgotten: Improved Benchmarks for Machine Unlearning
Keltin Grimes, Collin Abidi, Cole Frank, Shannon Gallagher
Machine learning models are vulnerable to adversarial attacks, including attacks that leak information about the model's training data. There has recently been an increase in interest about how to best address privacy concerns, especially in the presence of data-removal requests. Machine unlearning algorithms aim to efficiently update trained models to comply with data deletion requests while maintaining performance and without having to resort to retraining the model from scratch, a costly endeavor. Several algorithms in the machine unlearning literature demonstrate some level of privacy gains, but they are often evaluated only on rudimentary membership inference attacks, which do not represent realistic threats. In this paper we describe and propose alternative evaluation methods for three key shortcomings in the current evaluation of unlearning algorithms. We show the utility of our alternative evaluations via a series of experiments of state-of-the-art unlearning algorithms on different computer vision datasets, presenting a more detailed picture of the state of the field.
Read more5/30/2024