RISC-V R-Extension: Advancing Efficiency with Rented-Pipeline for Edge DNN Processing

0

Sign in to get full access
Overview
- Explores a novel RISC-V extension called the "R-Extension" that aims to improve efficiency for edge Deep Neural Network (DNN) processing
- Introduces a "Rented-Pipeline" architecture that allows lightweight edge devices to efficiently accelerate DNN workloads
- Demonstrates significant performance and energy improvements compared to traditional RISC-V and other DNN acceleration approaches
Plain English Explanation
The paper presents a new way to make edge devices, like smart sensors or small computers, better at running machine learning models like neural networks. Current edge devices often struggle to run these models efficiently, which can limit their usefulness.
The researchers developed a special extension to the popular RISC-V processor architecture called the "R-Extension." This extension adds new features that allow the processor to more easily handle the complex math required for neural networks. A key part of this is the "Rented-Pipeline" concept, which lets the processor temporarily "rent out" parts of its internal circuitry to speed up neural network computations.
By using the R-Extension and Rented-Pipeline, the researchers show that edge devices can run neural networks much faster and use less power compared to standard RISC-V processors or other specialized neural network accelerators. This could enable a new generation of smart, energy-efficient edge devices that can run powerful AI models locally without relying on a connection to the cloud.
Technical Explanation
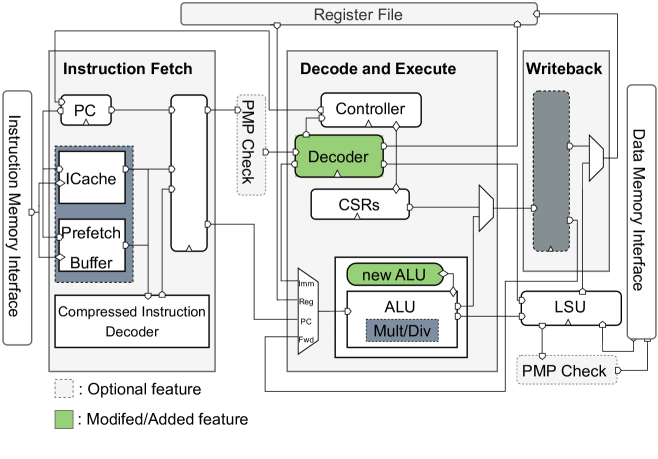
The paper proposes the RISC-V R-Extension, which introduces a custom instruction set architecture (ISA) and architectural pipeline register to enable efficient execution of DNN workloads on lightweight edge devices. At the core of the R-Extension is the "Rented-Pipeline" concept, which allows the processor to temporarily configure parts of its internal pipeline to accelerate DNN computations.
The Rented-Pipeline architecture consists of a set of custom instructions and registers that can be dynamically allocated to different DNN layers as needed. This allows the processor to efficiently utilize its resources for the specific computations required by a given DNN model, rather than having a fixed hardware accelerator. The researchers demonstrate that this approach outperforms traditional RISC-V processors as well as dedicated DNN accelerators in terms of both performance and energy efficiency.
The paper evaluates the R-Extension and Rented-Pipeline using a variety of DNN models and edge device workloads. The results show significant improvements in inference latency, throughput, and energy consumption compared to baseline RISC-V and other DNN acceleration techniques like xTERM, Tiny-DNN, and TensorFlow Lite.
Critical Analysis
The paper provides a compelling approach to improving the efficiency of DNN inference on edge devices by introducing the RISC-V R-Extension and Rented-Pipeline architecture. However, the research is primarily focused on specific DNN workloads and may not generalize as well to other types of machine learning models or applications.
Additionally, the paper does not discuss potential issues around programmability, software development tools, or the overall ecosystem support required to enable widespread adoption of the R-Extension. Integrating the new ISA and pipeline architecture into existing RISC-V toolchains and frameworks may require significant engineering effort.
Further research could explore the R-Extension's performance and energy characteristics on a wider range of edge device hardware, as well as its compatibility with emerging ML architectures like vector-based gradient boosting or foundation models. Evaluating the tradeoffs between programmability, flexibility, and efficiency would also help better understand the R-Extension's practical applicability.
Conclusion
The RISC-V R-Extension and Rented-Pipeline architecture presented in this paper offer a promising approach to improving the efficiency of DNN inference on lightweight edge devices. By introducing a custom ISA and dynamically configurable processor pipeline, the researchers demonstrate significant performance and energy gains compared to traditional RISC-V and other DNN acceleration techniques.
If adopted widely, the R-Extension could enable a new generation of smart, energy-efficient edge devices capable of running powerful AI models locally without relying on cloud connectivity. This could have far-reaching implications for applications ranging from IoT sensors to autonomous systems, where low-latency, on-device processing is crucial.
Overall, the paper presents an intriguing innovation in the field of energy-efficient edge computing and machine learning acceleration, though further research is needed to explore the real-world practicality and broader applicability of the R-Extension.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RISC-V R-Extension: Advancing Efficiency with Rented-Pipeline for Edge DNN Processing
Won Hyeok Kim, Hyeong Jin Kim, Tae Hee Han
The proliferation of edge devices necessitates efficient computational architectures for lightweight tasks, particularly deep neural network (DNN) inference. Traditional NPUs, though effective for such operations, face challenges in power, cost, and area when integrated into lightweight edge devices. The RISC-V architecture, known for its modularity and open-source nature, offers a viable alternative. This paper introduces the RISC-V R-extension, a novel approach to enhancing DNN process efficiency on edge devices. The extension features rented-pipeline stages and architectural pipeline registers (APR), which optimize critical operation execution, thereby reducing latency and memory access frequency. Furthermore, this extension includes new custom instructions to support these architectural improvements. Through comprehensive analysis, this study demonstrates the boost of R-extension in edge device processing, setting the stage for more responsive and intelligent edge applications.
Read more7/4/2024

0
RISC-V RVV efficiency for ANN algorithms
Konstantin Rumyantsev, Pavel Yakovlev, Andrey Gorshkov, Andrey P. Sokolov
Handling vast amounts of data is crucial in today's world. The growth of high-performance computing has created a need for parallelization, particularly in the area of machine learning algorithms such as ANN (Approximate Nearest Neighbors). To improve the speed of these algorithms, it is important to optimize them for specific processor architectures. RISC-V (Reduced Instruction Set Computer Five) is one of the modern processor architectures, which features a vector instruction set called RVV (RISC-V Vector Extension). In machine learning algorithms, vector extensions are widely utilized to improve the processing of voluminous data. This study examines the effectiveness of applying RVV to commonly used ANN algorithms. The algorithms were adapted for RISC-V and optimized using RVV after identifying the primary bottlenecks. Additionally, we developed a theoretical model of a parameterized vector block and identified the best on average configuration that demonstrates the highest theoretical performance of the studied ANN algorithms when the other CPU parameters are fixed.
Read more7/19/2024
0
Mixed-precision Neural Networks on RISC-V Cores: ISA extensions for Multi-Pumped Soft SIMD Operations
Giorgos Armeniakos, Alexis Maras, Sotirios Xydis, Dimitrios Soudris
Recent advancements in quantization and mixed-precision approaches offers substantial opportunities to improve the speed and energy efficiency of Neural Networks (NN). Research has shown that individual parameters with varying low precision, can attain accuracies comparable to full-precision counterparts. However, modern embedded microprocessors provide very limited support for mixed-precision NNs regarding both Instruction Set Architecture (ISA) extensions and their hardware design for efficient execution of mixed-precision operations, i.e., introducing several performance bottlenecks due to numerous instructions for data packing and unpacking, arithmetic unit under-utilizations etc. In this work, we bring together, for the first time, ISA extensions tailored to mixed-precision hardware optimizations, targeting energy-efficient DNN inference on leading RISC-V CPU architectures. To this end, we introduce a hardware-software co-design framework that enables cooperative hardware design, mixed-precision quantization, ISA extensions and inference in cycle-accurate emulations. At hardware level, we firstly expand the ALU unit within our proof-of-concept micro-architecture to support configurable fine grained mixed-precision arithmetic operations. Subsequently, we implement multi-pumping to minimize execution latency, with an additional soft SIMD optimization applied for 2-bit operations. At the ISA level, three distinct MAC instructions are encoded extending the RISC-V ISA, and exposed up to the compiler level, each corresponding to a different mixed-precision operational mode. Our extensive experimental evaluation over widely used DNNs and datasets, such as CIFAR10 and ImageNet, demonstrates that our framework can achieve, on average, 15x energy reduction for less than 1% accuracy loss and outperforms the ISA-agnostic state-of-the-art RISC-V cores.
Read more8/14/2024

0
xTern: Energy-Efficient Ternary Neural Network Inference on RISC-V-Based Edge Systems
Georg Rutishauser, Joan Mihali, Moritz Scherer, Luca Benini
Ternary neural networks (TNNs) offer a superior accuracy-energy trade-off compared to binary neural networks. However, until now, they have required specialized accelerators to realize their efficiency potential, which has hindered widespread adoption. To address this, we present xTern, a lightweight extension of the RISC-V instruction set architecture (ISA) targeted at accelerating TNN inference on general-purpose cores. To complement the ISA extension, we developed a set of optimized kernels leveraging xTern, achieving 67% higher throughput than their 2-bit equivalents. Power consumption is only marginally increased by 5.2%, resulting in an energy efficiency improvement by 57.1%. We demonstrate that the proposed xTern extension, integrated into an octa-core compute cluster, incurs a minimal silicon area overhead of 0.9% with no impact on timing. In end-to-end benchmarks, we demonstrate that xTern enables the deployment of TNNs achieving up to 1.6 percentage points higher CIFAR-10 classification accuracy than 2-bit networks at equal inference latency. Our results show that xTern enables RISC-V-based ultra-low-power edge AI platforms to benefit from the efficiency potential of TNNs.
Read more5/30/2024