xTern: Energy-Efficient Ternary Neural Network Inference on RISC-V-Based Edge Systems

0

Sign in to get full access
Overview
- This paper presents xTern, an energy-efficient ternary neural network inference system designed for RISC-V-based edge devices.
- Ternary neural networks use only three possible values for weights and activations, which can significantly reduce memory and computation requirements compared to full-precision networks.
- The xTern system leverages hardware-software co-design techniques to optimize ternary inference on RISC-V processors, leading to improved energy efficiency and performance.
Plain English Explanation
The paper discusses a new system called xTern that is designed to run AI models more efficiently on low-power edge devices like smartphones or smart home sensors. These devices often have limited computing power and battery life, so it's important to find ways to run AI models in a more energy-efficient way.
One key idea in xTern is the use of ternary neural networks. Ternary neural networks are a type of AI model that only use three possible values for the weights and activations, instead of the full range of floating-point numbers. This can significantly reduce the amount of memory and computation required to run the model, which saves energy.
The researchers have developed hardware and software techniques to take advantage of ternary neural networks on RISC-V processors, which are a type of energy-efficient CPU commonly used in edge devices. By carefully optimizing the ternary inference process, they are able to achieve better performance and energy efficiency compared to existing approaches.
This work is important because it shows how specialized AI hardware and software can be designed to run complex models on resource-constrained edge devices. As AI becomes more ubiquitous in our everyday devices, techniques like those used in xTern will be crucial for enabling energy-efficient, low-latency AI inference at the edge.
Technical Explanation
The xTern system presented in this paper leverages ternary neural networks to enable energy-efficient inference on RISC-V-based edge systems. Ternary neural networks restrict the weights and activations of a neural network to just three possible values, typically -1, 0, and 1. This reduces the memory footprint and computation requirements compared to standard full-precision networks.
The key technical contributions of xTern include:
-
Hardware-Software Co-Design: The researchers have developed a custom RISC-V processor core and accompanying software stack to efficiently execute ternary neural network inference. This includes optimizations to the RISC-V instruction set, memory subsystem, and data formats to maximize performance and energy efficiency.
-
Ternary Quantization and Approximation: xTern employs novel ternary quantization and approximation techniques to convert pre-trained full-precision neural networks into ternary versions with minimal accuracy degradation. This allows leveraging existing neural network models while benefiting from the efficiency of ternary computations.
-
Accelerated Ternary Inference: The xTern hardware and software work together to accelerate the key operations in ternary neural network inference, such as ternary matrix-vector multiplication. This includes techniques like custom RISC-V instructions and efficient memory access patterns.
The researchers evaluate xTern on a variety of edge computing benchmarks and show significant improvements in energy efficiency and performance compared to baseline RISC-V systems running full-precision neural networks. For example, xTern achieves up to 5.6x better energy efficiency and 4.8x higher throughput on image classification tasks.
Critical Analysis
The xTern system presented in this paper makes valuable contributions towards enabling energy-efficient AI inference on resource-constrained edge devices. The use of ternary neural networks is a promising approach, as it can significantly reduce the computational and memory requirements of AI models without excessive accuracy degradation.
However, the paper also acknowledges some limitations of the current xTern implementation. For example, the ternary quantization and approximation techniques may not work equally well for all types of neural network architectures and tasks. Further research is needed to understand the generalizability of these techniques.
Additionally, the evaluation of xTern is primarily focused on image classification workloads. It would be valuable to see how the system performs on a wider range of edge computing tasks, such as language processing or sensor fusion, to better understand its broader applicability.
Overall, the xTern system represents an important step forward in the design of energy-efficient AI hardware and software for edge computing. The research team has demonstrated the potential of ternary neural networks and hardware-software co-design techniques to improve the efficiency of AI inference on resource-constrained platforms. Further development and testing of the xTern approach could lead to significant advancements in the field of edge AI.
Conclusion
The xTern system presented in this paper explores a novel approach to enabling energy-efficient AI inference on RISC-V-based edge devices. By leveraging ternary neural networks and hardware-software co-design techniques, the researchers have demonstrated significant improvements in energy efficiency and performance compared to baseline systems running full-precision neural networks.
This work is an important contribution to the ongoing efforts to bring powerful AI capabilities to resource-constrained edge devices, which are becoming increasingly ubiquitous in our daily lives. As AI continues to permeate more of our everyday technology, techniques like those used in xTern will be crucial for ensuring that AI can be deployed in an energy-efficient and cost-effective manner, while still maintaining high levels of accuracy and performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
xTern: Energy-Efficient Ternary Neural Network Inference on RISC-V-Based Edge Systems
Georg Rutishauser, Joan Mihali, Moritz Scherer, Luca Benini
Ternary neural networks (TNNs) offer a superior accuracy-energy trade-off compared to binary neural networks. However, until now, they have required specialized accelerators to realize their efficiency potential, which has hindered widespread adoption. To address this, we present xTern, a lightweight extension of the RISC-V instruction set architecture (ISA) targeted at accelerating TNN inference on general-purpose cores. To complement the ISA extension, we developed a set of optimized kernels leveraging xTern, achieving 67% higher throughput than their 2-bit equivalents. Power consumption is only marginally increased by 5.2%, resulting in an energy efficiency improvement by 57.1%. We demonstrate that the proposed xTern extension, integrated into an octa-core compute cluster, incurs a minimal silicon area overhead of 0.9% with no impact on timing. In end-to-end benchmarks, we demonstrate that xTern enables the deployment of TNNs achieving up to 1.6 percentage points higher CIFAR-10 classification accuracy than 2-bit networks at equal inference latency. Our results show that xTern enables RISC-V-based ultra-low-power edge AI platforms to benefit from the efficiency potential of TNNs.
Read more5/30/2024
0
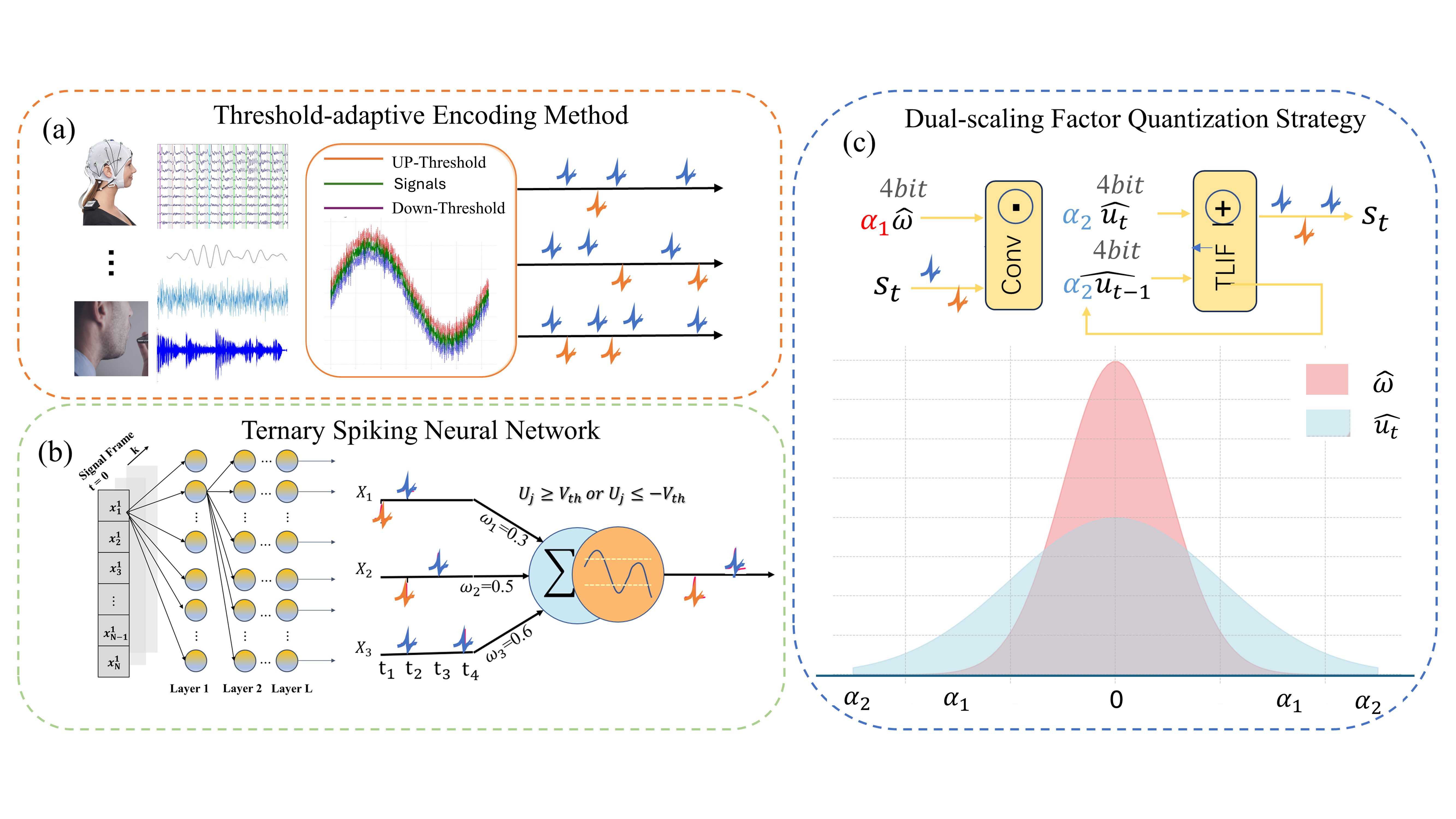
Ternary Spike-based Neuromorphic Signal Processing System
Shuai Wang, Dehao Zhang, Ammar Belatreche, Yichen Xiao, Hongyu Qing, Wenjie We, Malu Zhang, Yang Yang
Deep Neural Networks (DNNs) have been successfully implemented across various signal processing fields, resulting in significant enhancements in performance. However, DNNs generally require substantial computational resources, leading to significant economic costs and posing challenges for their deployment on resource-constrained edge devices. In this study, we take advantage of spiking neural networks (SNNs) and quantization technologies to develop an energy-efficient and lightweight neuromorphic signal processing system. Our system is characterized by two principal innovations: a threshold-adaptive encoding (TAE) method and a quantized ternary SNN (QT-SNN). The TAE method can efficiently encode time-varying analog signals into sparse ternary spike trains, thereby reducing energy and memory demands for signal processing. QT-SNN, compatible with ternary spike trains from the TAE method, quantifies both membrane potentials and synaptic weights to reduce memory requirements while maintaining performance. Extensive experiments are conducted on two typical signal-processing tasks: speech and electroencephalogram recognition. The results demonstrate that our neuromorphic signal processing system achieves state-of-the-art (SOTA) performance with a 94% reduced memory requirement. Furthermore, through theoretical energy consumption analysis, our system shows 7.5x energy saving compared to other SNN works. The efficiency and efficacy of the proposed system highlight its potential as a promising avenue for energy-efficient signal processing.
Read more7/9/2024

0
Annealing-inspired training of an optical neural network with ternary weights
Anas Skalli, Mirko Goldmann, Nasibeh Haghighi, Stephan Reitzenstein, James A. Lott, Daniel Brunner
Artificial neural networks (ANNs) represent a fundamentally connectionnist and distributed approach to computing, and as such they differ from classical computers that utilize the von Neumann architecture. This has revived research interest in new unconventional hardware to enable more efficient implementations of ANNs rather than emulating them on traditional machines. In order to fully leverage the capabilities of this new generation of ANNs, optimization algorithms that take into account hardware limitations and imperfections are necessary. Photonics represents a particularly promising platform, offering scalability, high speed, energy efficiency, and the capability for parallel information processing. Yet, fully fledged implementations of autonomous optical neural networks (ONNs) with in-situ learning remain scarce. In this work, we propose a ternary weight architecture high-dimensional semiconductor laser-based ONN. We introduce a simple method for achieving ternary weights with Boolean hardware, significantly increasing the ONN's information processing capabilities. Furthermore, we design a novel in-situ optimization algorithm that is compatible with, both, Boolean and ternary weights, and provide a detailed hyperparameter study of said algorithm for two different tasks. Our novel algorithm results in benefits, both in terms of convergence speed and performance. Finally, we experimentally characterize the long-term inference stability of our ONN and find that it is extremely stable with a consistency above 99% over a period of more than 10 hours, addressing one of the main concerns in the field. Our work is of particular relevance in the context of in-situ learning under restricted hardware resources, especially since minimizing the power consumption of auxiliary hardware is crucial to preserving efficiency gains achieved by non-von Neumann ANN implementations.
Read more9/4/2024
0
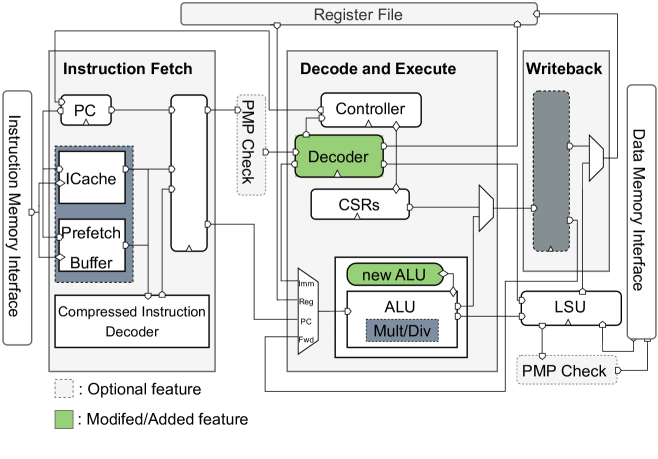
Mixed-precision Neural Networks on RISC-V Cores: ISA extensions for Multi-Pumped Soft SIMD Operations
Giorgos Armeniakos, Alexis Maras, Sotirios Xydis, Dimitrios Soudris
Recent advancements in quantization and mixed-precision approaches offers substantial opportunities to improve the speed and energy efficiency of Neural Networks (NN). Research has shown that individual parameters with varying low precision, can attain accuracies comparable to full-precision counterparts. However, modern embedded microprocessors provide very limited support for mixed-precision NNs regarding both Instruction Set Architecture (ISA) extensions and their hardware design for efficient execution of mixed-precision operations, i.e., introducing several performance bottlenecks due to numerous instructions for data packing and unpacking, arithmetic unit under-utilizations etc. In this work, we bring together, for the first time, ISA extensions tailored to mixed-precision hardware optimizations, targeting energy-efficient DNN inference on leading RISC-V CPU architectures. To this end, we introduce a hardware-software co-design framework that enables cooperative hardware design, mixed-precision quantization, ISA extensions and inference in cycle-accurate emulations. At hardware level, we firstly expand the ALU unit within our proof-of-concept micro-architecture to support configurable fine grained mixed-precision arithmetic operations. Subsequently, we implement multi-pumping to minimize execution latency, with an additional soft SIMD optimization applied for 2-bit operations. At the ISA level, three distinct MAC instructions are encoded extending the RISC-V ISA, and exposed up to the compiler level, each corresponding to a different mixed-precision operational mode. Our extensive experimental evaluation over widely used DNNs and datasets, such as CIFAR10 and ImageNet, demonstrates that our framework can achieve, on average, 15x energy reduction for less than 1% accuracy loss and outperforms the ISA-agnostic state-of-the-art RISC-V cores.
Read more8/14/2024