Risk-based Calibration for Probabilistic Classifiers

0
Sign in to get full access
Overview
- Introduces a risk-based approach to calibrating probabilistic classifiers
- Proposes an iterative learning algorithm to optimize the calibration of the classifier
- Evaluates the method on several real-world datasets and compares it to existing techniques
Plain English Explanation
This research paper presents a new way to calibrate probabilistic classifiers, which are machine learning models that output probability estimates for their predictions. The key idea is to use a risk-based approach to optimize the calibration of the classifier, rather than just focusing on the overall accuracy.
The iterative learning algorithm works by gradually adjusting the classifier's outputs to better match the desired risk levels. This allows the model to provide well-calibrated probability estimates, which can be important in applications where the confidence in predictions is critical, such as medical diagnosis or autonomous driving.
The researchers evaluate their method on several real-world datasets and compare it to existing calibration techniques. They find that their risk-based approach can significantly improve the calibration of the classifiers, while maintaining good overall performance.
Technical Explanation
The paper introduces a risk-based calibration (RBC) method for supervised classification tasks. The key idea is to formulate the calibration problem as an empirical risk minimization task, where the goal is to find a calibrated probabilistic classifier that minimizes a risk-based objective function.
The authors propose an iterative learning algorithm based on gradient descent to optimize the calibration parameters. This allows the classifier to be iteratively adjusted to better match the desired risk levels, resulting in well-calibrated probability estimates.
The method is evaluated on several real-world datasets, and the results show that RBC can significantly improve the calibration of the classifiers compared to existing techniques, while maintaining good overall performance.
Critical Analysis
The paper provides a novel and well-designed approach to calibrating probabilistic classifiers, addressing an important problem in machine learning. The risk-based formulation and iterative learning algorithm are theoretically sound and demonstrate promising empirical results.
However, the paper does not discuss the computational complexity of the proposed algorithm, which could be a concern for large-scale real-world applications. Additionally, the authors do not explore the limitations of their method, such as how it might perform under different data distributions or in the presence of adversarial attacks.
Further research could also investigate the trade-offs between calibration accuracy and other performance metrics, as well as the application of this approach to other types of machine learning models beyond just classifiers.
Conclusion
This paper presents a novel risk-based approach to calibrating probabilistic classifiers, which can be particularly useful in applications where the confidence in predictions is critical. The iterative learning algorithm provides a principled way to optimize the calibration, and the empirical results demonstrate the benefits of this approach compared to existing techniques.
While the paper does not address all potential limitations, it represents a significant contribution to the field of machine learning and can inspire further research on improving the reliability and interpretability of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Risk-based Calibration for Probabilistic Classifiers
Aritz P'erez, Carlos Echegoyen, Guzm'an Santaf'e
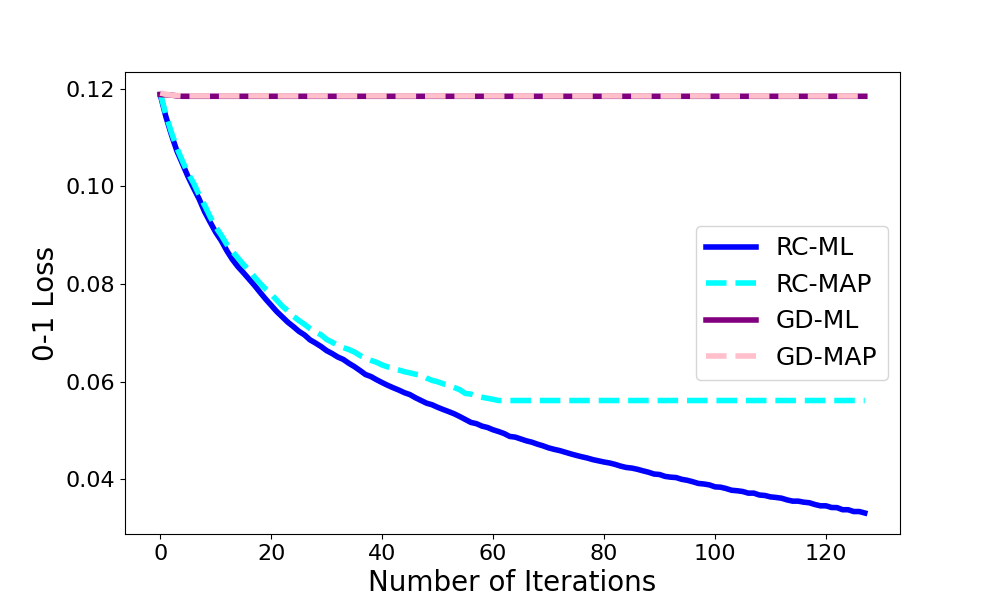
We introduce a general iterative procedure called risk-based calibration (RC) designed to minimize the empirical risk under the 0-1 loss (empirical error) for probabilistic classifiers. These classifiers are based on modeling probability distributions, including those constructed from the joint distribution (generative) and those based on the class conditional distribution (conditional). RC can be particularized to any probabilistic classifier provided a specific learning algorithm that computes the classifier's parameters in closed form using data statistics. RC reinforces the statistics aligned with the true class while penalizing those associated with other classes, guided by the 0-1 loss. The proposed method has been empirically tested on 30 datasets using naive Bayes, quadratic discriminant analysis, and logistic regression classifiers. RC improves the empirical error of the original closed-form learning algorithms and, more notably, consistently outperforms the gradient descent approach with the three classifiers.
Read more9/6/2024

0
Probabilistic Scores of Classifiers, Calibration is not Enough
Agathe Fernandes Machado, Arthur Charpentier, Emmanuel Flachaire, Ewen Gallic, Franc{c}ois Hu
In binary classification tasks, accurate representation of probabilistic predictions is essential for various real-world applications such as predicting payment defaults or assessing medical risks. The model must then be well-calibrated to ensure alignment between predicted probabilities and actual outcomes. However, when score heterogeneity deviates from the underlying data probability distribution, traditional calibration metrics lose reliability, failing to align score distribution with actual probabilities. In this study, we highlight approaches that prioritize optimizing the alignment between predicted scores and true probability distributions over minimizing traditional performance or calibration metrics. When employing tree-based models such as Random Forest and XGBoost, our analysis emphasizes the flexibility these models offer in tuning hyperparameters to minimize the Kullback-Leibler (KL) divergence between predicted and true distributions. Through extensive empirical analysis across 10 UCI datasets and simulations, we demonstrate that optimizing tree-based models based on KL divergence yields superior alignment between predicted scores and actual probabilities without significant performance loss. In real-world scenarios, the reference probability is determined a priori as a Beta distribution estimated through maximum likelihood. Conversely, minimizing traditional calibration metrics may lead to suboptimal results, characterized by notable performance declines and inferior KL values. Our findings reveal limitations in traditional calibration metrics, which could undermine the reliability of predictive models for critical decision-making.
Read more8/9/2024

0
Cautious Calibration in Binary Classification
Mari-Liis Allikivi, Joonas Jarve, Meelis Kull
Being cautious is crucial for enhancing the trustworthiness of machine learning systems integrated into decision-making pipelines. Although calibrated probabilities help in optimal decision-making, perfect calibration remains unattainable, leading to estimates that fluctuate between under- and overconfidence. This becomes a critical issue in high-risk scenarios, where even occasional overestimation can lead to extreme expected costs. In these scenarios, it is important for each predicted probability to lean towards underconfidence, rather than just achieving an average balance. In this study, we introduce the novel concept of cautious calibration in binary classification. This approach aims to produce probability estimates that are intentionally underconfident for each predicted probability. We highlight the importance of this approach in a high-risk scenario and propose a theoretically grounded method for learning cautious calibration maps. Through experiments, we explore and compare our method to various approaches, including methods originally not devised for cautious calibration but applicable in this context. We show that our approach is the most consistent in providing cautious estimates. Our work establishes a strong baseline for further developments in this novel framework.
Read more8/12/2024

0
PAC-Bayes Analysis for Recalibration in Classification
Masahiro Fujisawa, Futoshi Futami
Nonparametric estimation with binning is widely employed in the calibration error evaluation and the recalibration of machine learning models. Recently, theoretical analyses of the bias induced by this estimation approach have been actively pursued; however, the understanding of the generalization of the calibration error to unknown data remains limited. In addition, although many recalibration algorithms have been proposed, their generalization performance lacks theoretical guarantees. To address this problem, we conduct a generalization analysis of the calibration error under the probably approximately correct (PAC) Bayes framework. This approach enables us to derive a first optimizable upper bound for the generalization error in the calibration context. We then propose a generalization-aware recalibration algorithm based on our generalization theory. Numerical experiments show that our algorithm improves the Gaussian-process-based recalibration performance on various benchmark datasets and models.
Read more6/11/2024