Towards Certification of Uncertainty Calibration under Adversarial Attacks
2405.13922
0
0
🔎
Abstract
Since neural classifiers are known to be sensitive to adversarial perturbations that alter their accuracy, textit{certification methods} have been developed to provide provable guarantees on the insensitivity of their predictions to such perturbations. Furthermore, in safety-critical applications, the frequentist interpretation of the confidence of a classifier (also known as model calibration) can be of utmost importance. This property can be measured via the Brier score or the expected calibration error. We show that attacks can significantly harm calibration, and thus propose certified calibration as worst-case bounds on calibration under adversarial perturbations. Specifically, we produce analytic bounds for the Brier score and approximate bounds via the solution of a mixed-integer program on the expected calibration error. Finally, we propose novel calibration attacks and demonstrate how they can improve model calibration through textit{adversarial calibration training}.
Create account to get full access
Overview
- Neural classifiers are sensitive to adversarial perturbations that can alter their accuracy.
- Certification methods have been developed to provide guarantees on the insensitivity of their predictions to such perturbations.
- In safety-critical applications, the frequentist interpretation of a classifier's confidence (model calibration) is important.
- Attacks can significantly harm calibration, so the researchers propose certified calibration as worst-case bounds on calibration under adversarial perturbations.
- The researchers produce analytic bounds for the Brier score and approximate bounds via mixed-integer programming for the expected calibration error.
- They also propose novel calibration attacks and demonstrate how they can improve model calibration through adversarial calibration training.
Plain English Explanation
Neural networks, a type of machine learning model, are known to be vulnerable to small changes in their input data, called adversarial perturbations. These changes can cause the model to make incorrect predictions, even when the original input appears unchanged to a human. To address this, researchers have developed certification methods that can provide guarantees about the model's resilience to these perturbations.
In safety-critical applications, like healthcare or self-driving cars, it's important that the model's confidence in its predictions is well-calibrated. This means that if the model is 90% confident in a prediction, it should be correct 90% of the time. The researchers show that adversarial attacks can disrupt this calibration, causing the model to be overconfident or underconfident in its predictions.
To address this, the researchers propose "certified calibration" - bounds on how much the model's calibration can be affected by adversarial perturbations. They derive mathematical formulas to calculate these bounds, both for a metric called the Brier score and for another metric called the expected calibration error.
The researchers also develop new types of adversarial attacks that specifically target the model's calibration. They show that by training the model to be robust to these calibration attacks, the model's overall calibration can be improved, a process they call "adversarial calibration training."
Technical Explanation
The paper explores the problem of model calibration - the alignment between a classifier's predicted probabilities and the true probabilities of the corresponding outcomes. The researchers show that neural classifiers, which are known to be vulnerable to adversarial perturbations, can also have their calibration significantly harmed by such attacks.
To address this, the researchers propose the concept of "certified calibration" - providing provable guarantees on the worst-case deviation of a classifier's calibration under adversarial perturbations. Specifically, they derive analytic bounds on the Brier score, a common metric for measuring calibration, and approximate bounds on the expected calibration error via the solution of a mixed-integer program.
Additionally, the researchers introduce novel "calibration attacks" that specifically target a model's calibration, rather than its overall accuracy. They show that by training models to be robust to these calibration-focused attacks, a process they call "adversarial calibration training," the overall calibration of the model can be improved.
The experiments in the paper demonstrate the effectiveness of the proposed certification methods and calibration attacks across a variety of benchmark datasets and model architectures. The researchers also discuss the potential implications of their findings for safety-critical applications where model calibration is of utmost importance.
Critical Analysis
The paper presents a comprehensive study of adversarial attacks on model calibration, an important but often overlooked aspect of neural network performance. The proposed certification methods and calibration attacks are technically sound and the empirical results are compelling.
However, one potential limitation is the computational complexity of the mixed-integer programming approach used to derive bounds on the expected calibration error. This may limit the scalability of the proposed methods to larger models or datasets. Additionally, the paper does not explore the trade-offs between certified calibration and other desirable model properties, such as predictive accuracy or robustness to other types of adversarial attacks.
Further research could investigate more efficient approximation techniques for certified calibration, as well as the interplay between calibration, accuracy, and other model characteristics in the presence of adversarial perturbations. Exploring the practical implications of certified calibration in real-world, safety-critical applications would also be a valuable avenue for future work.
Conclusion
This paper makes important contributions to the field of model calibration, particularly in the context of adversarial robustness. By proposing certified calibration and novel calibration attacks, the researchers have expanded our understanding of the vulnerabilities of neural classifiers and provided tools to mitigate these issues.
The findings have significant implications for the deployment of machine learning models in safety-critical applications, where accurate and well-calibrated predictions are of paramount importance. The techniques presented in this paper can help ensure that models maintain their reliability and trustworthiness, even in the face of adversarial threats.
As machine learning systems become increasingly ubiquitous, the importance of addressing these challenges will only grow. This paper serves as a valuable step forward in the ongoing effort to develop more robust and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Calibration Attacks: A Comprehensive Study of Adversarial Attacks on Model Confidence
Stephen Obadinma, Xiaodan Zhu, Hongyu Guo
0
0
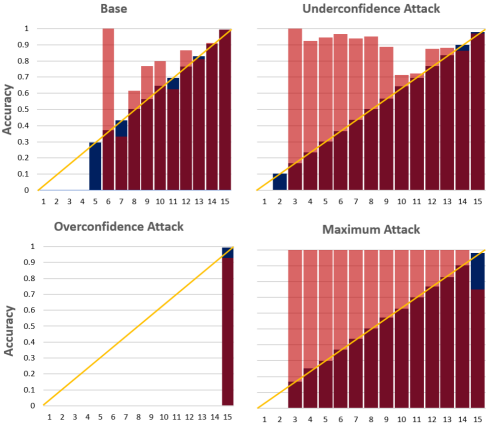
In this work, we highlight and perform a comprehensive study on calibration attacks, a form of adversarial attacks that aim to trap victim models to be heavily miscalibrated without altering their predicted labels, hence endangering the trustworthiness of the models and follow-up decision making based on their confidence. We propose four typical forms of calibration attacks: underconfidence, overconfidence, maximum miscalibration, and random confidence attacks, conducted in both the black-box and white-box setups. We demonstrate that the attacks are highly effective on both convolutional and attention-based models: with a small number of queries, they seriously skew confidence without changing the predictive performance. Given the potential danger, we further investigate the effectiveness of a wide range of adversarial defence and recalibration methods, including our proposed defences specifically designed for calibration attacks to mitigate the harm. From the ECE and KS scores, we observe that there are still significant limitations in handling calibration attacks. To the best of our knowledge, this is the first dedicated study that provides a comprehensive investigation on calibration-focused attacks. We hope this study helps attract more attention to these types of attacks and hence hamper their potential serious damages. To this end, this work also provides detailed analyses to understand the characteristics of the attacks.
5/21/2024
🧠
Et Tu Certifications: Robustness Certificates Yield Better Adversarial Examples
Andrew C. Cullen, Shijie Liu, Paul Montague, Sarah M. Erfani, Benjamin I. P. Rubinstein
0
0
In guaranteeing the absence of adversarial examples in an instance's neighbourhood, certification mechanisms play an important role in demonstrating neural net robustness. In this paper, we ask if these certifications can compromise the very models they help to protect? Our new emph{Certification Aware Attack} exploits certifications to produce computationally efficient norm-minimising adversarial examples $74 %$ more often than comparable attacks, while reducing the median perturbation norm by more than $10%$. While these attacks can be used to assess the tightness of certification bounds, they also highlight that releasing certifications can paradoxically reduce security.
6/13/2024
Extreme Miscalibration and the Illusion of Adversarial Robustness
Vyas Raina, Samson Tan, Volkan Cevher, Aditya Rawal, Sheng Zha, George Karypis
0
0
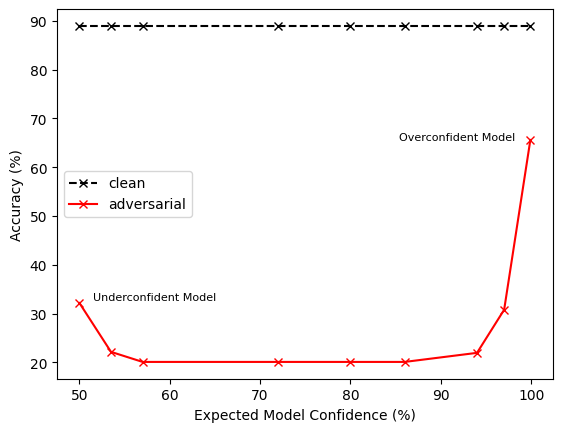
Deep learning-based Natural Language Processing (NLP) models are vulnerable to adversarial attacks, where small perturbations can cause a model to misclassify. Adversarial Training (AT) is often used to increase model robustness. However, we have discovered an intriguing phenomenon: deliberately or accidentally miscalibrating models masks gradients in a way that interferes with adversarial attack search methods, giving rise to an apparent increase in robustness. We show that this observed gain in robustness is an illusion of robustness (IOR), and demonstrate how an adversary can perform various forms of test-time temperature calibration to nullify the aforementioned interference and allow the adversarial attack to find adversarial examples. Hence, we urge the NLP community to incorporate test-time temperature scaling into their robustness evaluations to ensure that any observed gains are genuine. Finally, we show how the temperature can be scaled during textit{training} to improve genuine robustness.
6/3/2024
🐍
Calibration-Aware Bayesian Learning
Jiayi Huang, Sangwoo Park, Osvaldo Simeone
0
0
Deep learning models, including modern systems like large language models, are well known to offer unreliable estimates of the uncertainty of their decisions. In order to improve the quality of the confidence levels, also known as calibration, of a model, common approaches entail the addition of either data-dependent or data-independent regularization terms to the training loss. Data-dependent regularizers have been recently introduced in the context of conventional frequentist learning to penalize deviations between confidence and accuracy. In contrast, data-independent regularizers are at the core of Bayesian learning, enforcing adherence of the variational distribution in the model parameter space to a prior density. The former approach is unable to quantify epistemic uncertainty, while the latter is severely affected by model misspecification. In light of the limitations of both methods, this paper proposes an integrated framework, referred to as calibration-aware Bayesian neural networks (CA-BNNs), that applies both regularizers while optimizing over a variational distribution as in Bayesian learning. Numerical results validate the advantages of the proposed approach in terms of expected calibration error (ECE) and reliability diagrams.
4/15/2024