Probabilistic Scores of Classifiers, Calibration is not Enough

0

Sign in to get full access
Overview
- This paper examines the use of probabilistic scores to evaluate the performance of machine learning classifiers.
- The researchers found that simply calibrating the classifier's output probabilities is not enough to ensure reliable probabilistic scores.
- They propose additional techniques to better assess the quality of probabilistic scores produced by classifiers.
Plain English Explanation
Machine learning classifiers are often used to make predictions, and they typically output a probability for each possible class. These probability scores are meant to represent the classifier's confidence in its predictions. A good explanation of classifiers and probability scores.
The researchers in this paper looked at how well these probability scores reflect the true uncertainty of the classifier's predictions. They found that simply calibrating the probability scores (adjusting them to match the true probabilities) is not enough to ensure the scores are reliable. More on calibration and proper scoring rules.
The paper proposes additional techniques to better assess the quality of the probability scores produced by classifiers. These include looking at the distribution of scores, not just the calibration. The goal is to develop more robust ways to evaluate classifier performance beyond just looking at accuracy. Other work on quantifying uncertainty in predictions.
Technical Explanation
The researchers examined the use of probabilistic scores to evaluate the performance of machine learning classifiers. Probabilistic scores measure how well a classifier's output probabilities match the true underlying probabilities.
A common approach is to calibrate the classifier's output probabilities, adjusting them to match the true probabilities. However, the researchers found that calibration alone is not enough to ensure reliable probabilistic scores. More on efficient multi-class calibration.
The paper proposes additional techniques to better assess the quality of the probabilistic scores produced by classifiers. This includes looking at the distribution of scores, not just the calibration. The goal is to develop more robust ways to evaluate classifier performance beyond just accuracy.
Critical Analysis
The paper makes a valid point that calibration is not sufficient for ensuring reliable probabilistic scores from classifiers. This is an important issue, as many real-world applications rely on accurate probability estimates from machine learning models.
However, the paper does not provide a comprehensive solution. The proposed techniques, while helpful, may still miss important aspects of score quality. There could be other factors, beyond calibration and score distribution, that influence the reliability of probabilistic outputs.
Additionally, the paper focuses on offline evaluation of scores. In many applications, classifiers operate in online settings where the true labels are not immediately available. Techniques for online calibration and score evaluation may be needed. Work on online calibrated conformal prediction.
Further research is needed to fully address the challenge of ensuring reliable probabilistic scores from classifiers, especially in complex, real-world scenarios.
Conclusion
This paper highlights an important issue with using calibrated probability scores to evaluate classifier performance. The researchers show that calibration alone is insufficient, and propose additional techniques to better assess score quality.
While not a complete solution, the paper makes a valuable contribution by drawing attention to the limitations of common evaluation practices. Improving the reliability of probabilistic outputs from machine learning models is crucial for many high-stakes applications. This work lays the groundwork for further research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Probabilistic Scores of Classifiers, Calibration is not Enough
Agathe Fernandes Machado, Arthur Charpentier, Emmanuel Flachaire, Ewen Gallic, Franc{c}ois Hu
In binary classification tasks, accurate representation of probabilistic predictions is essential for various real-world applications such as predicting payment defaults or assessing medical risks. The model must then be well-calibrated to ensure alignment between predicted probabilities and actual outcomes. However, when score heterogeneity deviates from the underlying data probability distribution, traditional calibration metrics lose reliability, failing to align score distribution with actual probabilities. In this study, we highlight approaches that prioritize optimizing the alignment between predicted scores and true probability distributions over minimizing traditional performance or calibration metrics. When employing tree-based models such as Random Forest and XGBoost, our analysis emphasizes the flexibility these models offer in tuning hyperparameters to minimize the Kullback-Leibler (KL) divergence between predicted and true distributions. Through extensive empirical analysis across 10 UCI datasets and simulations, we demonstrate that optimizing tree-based models based on KL divergence yields superior alignment between predicted scores and actual probabilities without significant performance loss. In real-world scenarios, the reference probability is determined a priori as a Beta distribution estimated through maximum likelihood. Conversely, minimizing traditional calibration metrics may lead to suboptimal results, characterized by notable performance declines and inferior KL values. Our findings reveal limitations in traditional calibration metrics, which could undermine the reliability of predictive models for critical decision-making.
Read more8/9/2024

0
Reassessing How to Compare and Improve the Calibration of Machine Learning Models
Muthu Chidambaram, Rong Ge
A machine learning model is calibrated if its predicted probability for an outcome matches the observed frequency for that outcome conditional on the model prediction. This property has become increasingly important as the impact of machine learning models has continued to spread to various domains. As a result, there are now a dizzying number of recent papers on measuring and improving the calibration of (specifically deep learning) models. In this work, we reassess the reporting of calibration metrics in the recent literature. We show that there exist trivial recalibration approaches that can appear seemingly state-of-the-art unless calibration and prediction metrics (i.e. test accuracy) are accompanied by additional generalization metrics such as negative log-likelihood. We then derive a calibration-based decomposition of Bregman divergences that can be used to both motivate a choice of calibration metric based on a generalization metric, and to detect trivial calibration. Finally, we apply these ideas to develop a new extension to reliability diagrams that can be used to jointly visualize calibration as well as the estimated generalization error of a model.
Read more6/7/2024
0
Risk-based Calibration for Probabilistic Classifiers
Aritz P'erez, Carlos Echegoyen, Guzm'an Santaf'e
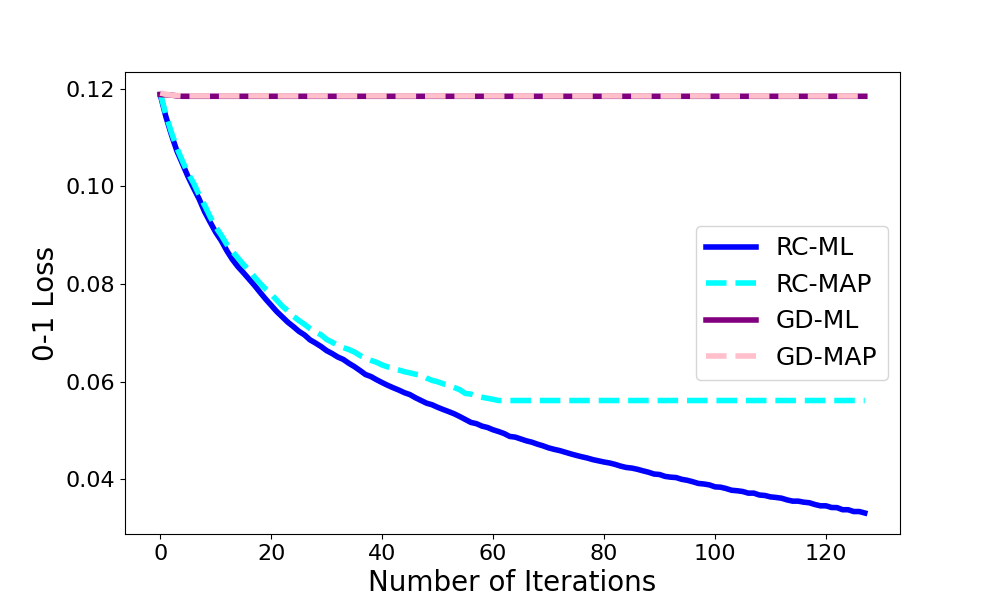
We introduce a general iterative procedure called risk-based calibration (RC) designed to minimize the empirical risk under the 0-1 loss (empirical error) for probabilistic classifiers. These classifiers are based on modeling probability distributions, including those constructed from the joint distribution (generative) and those based on the class conditional distribution (conditional). RC can be particularized to any probabilistic classifier provided a specific learning algorithm that computes the classifier's parameters in closed form using data statistics. RC reinforces the statistics aligned with the true class while penalizing those associated with other classes, guided by the 0-1 loss. The proposed method has been empirically tested on 30 datasets using naive Bayes, quadratic discriminant analysis, and logistic regression classifiers. RC improves the empirical error of the original closed-form learning algorithms and, more notably, consistently outperforms the gradient descent approach with the three classifiers.
Read more9/6/2024
0
Evaluating Posterior Probabilities: Decision Theory, Proper Scoring Rules, and Calibration
Luciana Ferrer, Daniel Ramos
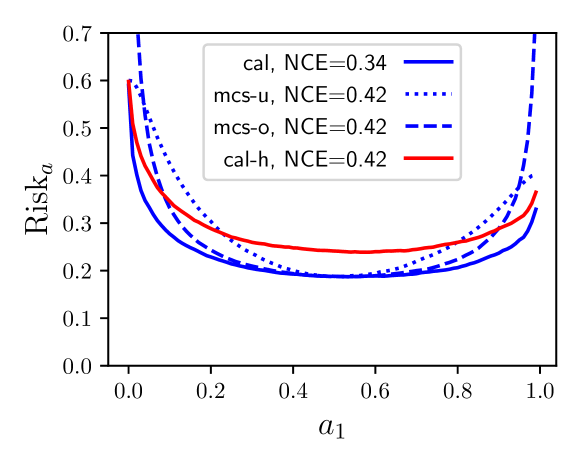
Most machine learning classifiers are designed to output posterior probabilities for the classes given the input sample. These probabilities may be used to make the categorical decision on the class of the sample; provided as input to a downstream system; or provided to a human for interpretation. Evaluating the quality of the posteriors generated by these system is an essential problem which was addressed decades ago with the invention of proper scoring rules (PSRs). Unfortunately, much of the recent machine learning literature uses calibration metrics -- most commonly, the expected calibration error (ECE) -- as a proxy to assess posterior performance. The problem with this approach is that calibration metrics reflect only one aspect of the quality of the posteriors, ignoring the discrimination performance. For this reason, we argue that calibration metrics should play no role in the assessment of posterior quality. Expected PSRs should instead be used for this job, preferably normalized for ease of interpretation. In this work, we first give a brief review of PSRs from a practical perspective, motivating their definition using Bayes decision theory. We discuss why expected PSRs provide a principled measure of the quality of a system's posteriors and why calibration metrics are not the right tool for this job. We argue that calibration metrics, while not useful for performance assessment, may be used as diagnostic tools during system development. With this purpose in mind, we discuss a simple and practical calibration metric, called calibration loss, derived from a decomposition of expected PSRs. We compare this metric with the ECE and with the expected score divergence calibration metric from the PSR literature and argue, using theoretical and empirical evidence, that calibration loss is superior to these two metrics.
Read more8/7/2024