RMS-FlowNet++: Efficient and Robust Multi-Scale Scene Flow Estimation for Large-Scale Point Clouds

0
Sign in to get full access
Overview
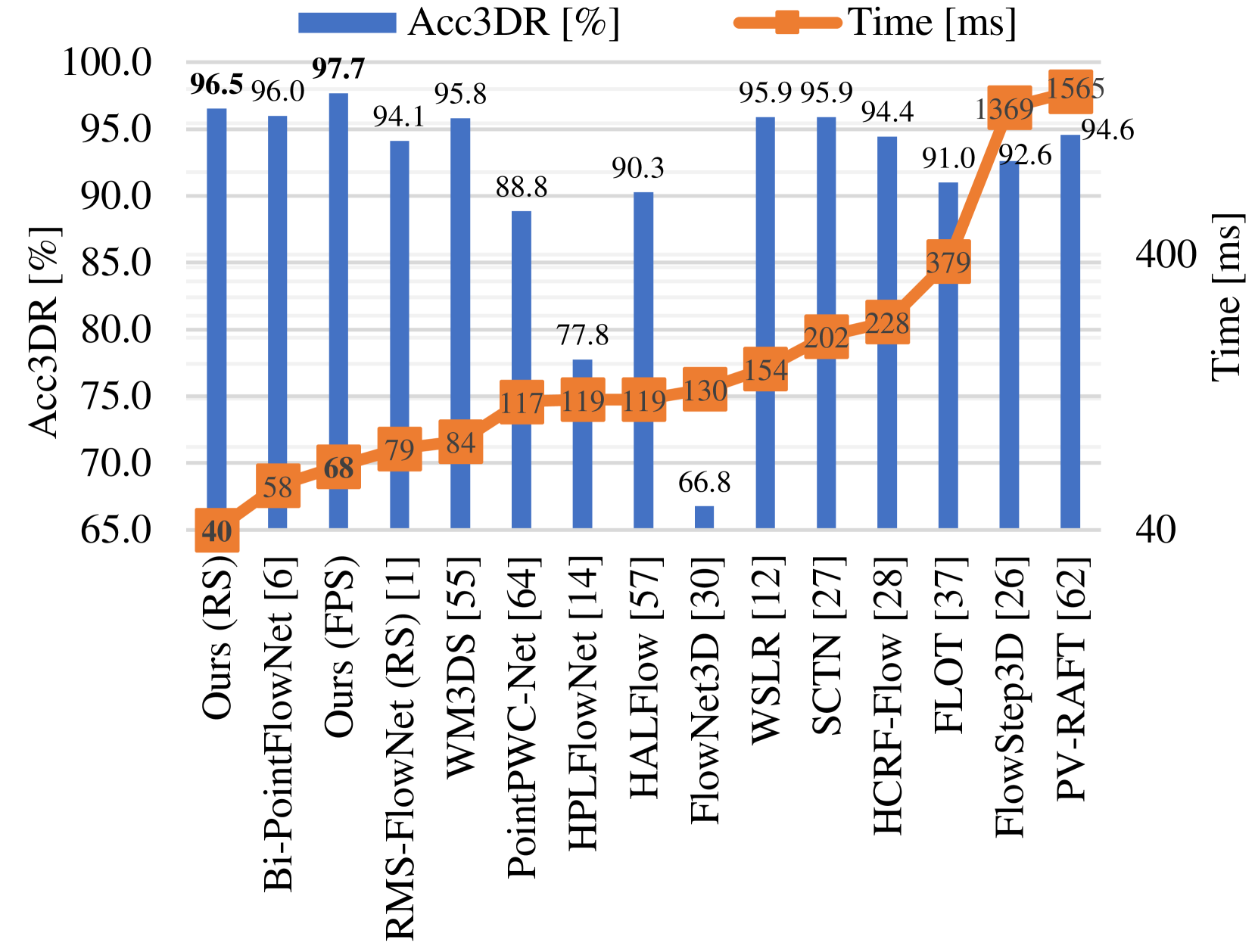
- This paper presents RMS-FlowNet++, an efficient and robust multi-scale scene flow estimation model for large-scale point clouds.
- The key contributions include a new multi-scale feature extraction module, a novel flow estimation head, and an efficient inference pipeline.
- The model demonstrates state-of-the-art performance on several public benchmarks while being computationally efficient.
Plain English Explanation
RMS-FlowNet++ is a machine learning model that can estimate the motion of objects in 3D point cloud data. Point clouds are a type of 3D data representation that uses a collection of individual data points to describe the shape and position of objects.
The main idea behind RMS-FlowNet++ is to extract features at multiple scales from the input point cloud data and then use those features to estimate the movement, or "scene flow", of the objects in the scene. This multi-scale approach allows the model to capture both fine-grained details and broader contextual information, leading to more accurate and robust scene flow estimates.
The model has several key innovations, including a new feature extraction module and a specialized flow estimation head. These components work together to make the model efficient in terms of computational cost while still achieving state-of-the-art performance on benchmark datasets.
The ability to accurately estimate scene flow from 3D point clouds has many practical applications, such as in autonomous vehicles, robotics, and virtual/augmented reality systems, where understanding the motion of objects in a scene is crucial for tasks like navigation, manipulation, and interaction.
Technical Explanation
RMS-FlowNet++ builds upon previous work on scene flow estimation from point clouds, such as SSFlowNet, Let it Flow, and CMU-FlowNet. The key advancements include:
- Multi-Scale Feature Extraction: The model uses a novel multi-scale feature extraction module that captures contextual information at different scales, allowing it to better handle large-scale point cloud data.
- Efficient Flow Estimation Head: The model introduces a specialized flow estimation head that predicts scene flow in an efficient and robust manner, improving both accuracy and inference speed.
- Efficient Inference Pipeline: The model is designed with an efficient inference pipeline, enabling it to process large-scale point clouds in real-time.
The model is evaluated on several public benchmarks, including SceneFlow and KITTI, and demonstrates state-of-the-art performance while being computationally efficient.
Critical Analysis
The paper provides a comprehensive evaluation of RMS-FlowNet++ and highlights its strengths, such as the improved accuracy and efficiency compared to previous methods. However, the authors do not extensively discuss the potential limitations or failure cases of the model.
One area that could be further explored is the model's robustness to noise, occlusions, and other real-world challenges that may arise in large-scale point cloud data. Additionally, the paper could have provided more insights into the trade-offs between the model's complexity and its performance, as well as potential avenues for further improving efficiency and scalability.
Conclusion
RMS-FlowNet++ is a significant advancement in the field of scene flow estimation from large-scale point clouds. Its efficient and robust multi-scale approach, combined with state-of-the-art performance on benchmark datasets, makes it a promising solution for a wide range of applications, such as autonomous navigation, robotics, and mixed reality systems. The innovations presented in this work can serve as a foundation for further research and development in the broader field of 3D scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!