CMU-Flownet: Exploring Point Cloud Scene Flow Estimation in Occluded Scenario

0

Sign in to get full access
Overview
- Proposes a novel deep learning model called CMU-Flownet for estimating scene flow from point cloud data, with a focus on handling occluded scenarios
- Introduces a novel method to handle occlusions by learning both forward and backward scene flow
- Demonstrates improved performance on standard benchmarks compared to existing approaches
Plain English Explanation
The paper presents a new deep learning model called CMU-Flownet that can estimate the movement of objects and scenes from 3D point cloud data. This is an important task in computer vision, as it allows us to understand how objects and environments are changing over time.
One key challenge in scene flow estimation is handling occlusions - situations where an object is partially hidden from view. The researchers behind CMU-Flownet have developed a novel approach to address this issue. Instead of just estimating the forward motion of objects, their model also learns the backward motion, or how objects move back into view after being occluded. This gives the model a more complete understanding of the 3D scene and how it is changing.
When tested on standard benchmarks, CMU-Flownet outperformed existing scene flow estimation methods, demonstrating the value of this new approach to handling occlusions. The researchers believe their work could have important applications in areas like autonomous driving, robotics, and augmented reality, where understanding 3D scene dynamics is crucial.
Technical Explanation
The key innovation in CMU-Flownet is the use of a bidirectional scene flow formulation to handle occlusions. Typical scene flow estimation models only predict the forward motion of objects, but CMU-Flownet also learns the backward motion - how occluded objects move back into view.
The model takes 3D point cloud data as input and uses a neural network architecture consisting of a PointNet-based encoder and a convolutional decoder. This allows the model to effectively process and reason about the unstructured 3D point cloud data. The bidirectional scene flow is represented as vector fields that encode both the forward and backward motion of each point in the cloud.
The researchers trained and evaluated CMU-Flownet on standard benchmarks like SceneTracker and Semantic Flow, demonstrating significant performance improvements over existing methods, especially in occluded regions.
Critical Analysis
The paper provides a thoughtful approach to addressing occlusions in scene flow estimation, a common challenge in this field. The bidirectional formulation is a novel and promising idea that allows the model to better understand the 3D dynamics of a scene, even when parts of it are temporarily hidden from view.
However, the paper does not discuss the computational complexity or real-time performance of CMU-Flownet, which would be an important consideration for practical applications like 3D object detection for autonomous vehicles. Additionally, the evaluation is limited to standard benchmarks, and more real-world testing would be needed to fully assess the model's capabilities and limitations.
Overall, the CMU-Flownet approach represents a valuable contribution to the field of 3D scene understanding, and the authors' focus on handling occlusions is an important step forward. Further research and development in this area could lead to significant advancements in applications that rely on robust 3D perception.
Conclusion
The CMU-Flownet paper presents a novel deep learning model for 3D scene flow estimation that effectively handles occlusions by learning both forward and backward motion. This bidirectional approach outperforms existing methods on standard benchmarks, suggesting it could have important applications in areas like autonomous driving, robotics, and augmented reality, where understanding the dynamic 3D environment is crucial. While the paper raises a few open questions, it represents a significant advancement in the field of 3D scene understanding and points the way towards more robust and reliable 3D perception systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CMU-Flownet: Exploring Point Cloud Scene Flow Estimation in Occluded Scenario
Jingze Chen, Junfeng Yao, Qiqin Lin, Lei Li
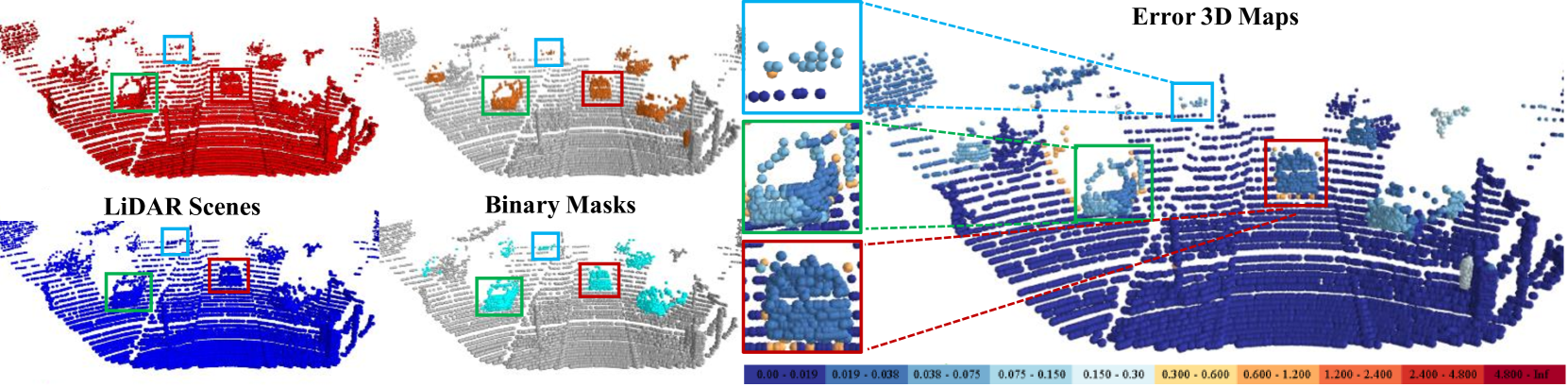
Occlusions hinder point cloud frame alignment in LiDAR data, a challenge inadequately addressed by scene flow models tested mainly on occlusion-free datasets. Attempts to integrate occlusion handling within networks often suffer accuracy issues due to two main limitations: a) the inadequate use of occlusion information, often merging it with flow estimation without an effective integration strategy, and b) reliance on distance-weighted upsampling that falls short in correcting occlusion-related errors. To address these challenges, we introduce the Correlation Matrix Upsampling Flownet (CMU-Flownet), incorporating an occlusion estimation module within its cost volume layer, alongside an Occlusion-aware Cost Volume (OCV) mechanism. Specifically, we propose an enhanced upsampling approach that expands the sensory field of the sampling process which integrates a Correlation Matrix designed to evaluate point-level similarity. Meanwhile, our model robustly integrates occlusion data within the context of scene flow, deploying this information strategically during the refinement phase of the flow estimation. The efficacy of this approach is demonstrated through subsequent experimental validation. Empirical assessments reveal that CMU-Flownet establishes state-of-the-art performance within the realms of occluded Flyingthings3D and KITTY datasets, surpassing previous methodologies across a majority of evaluated metrics.
Read more4/17/2024
0
EgoFlowNet: Non-Rigid Scene Flow from Point Clouds with Ego-Motion Support
Ramy Battrawy, Ren'e Schuster, Didier Stricker
Recent weakly-supervised methods for scene flow estimation from LiDAR point clouds are limited to explicit reasoning on object-level. These methods perform multiple iterative optimizations for each rigid object, which makes them vulnerable to clustering robustness. In this paper, we propose our EgoFlowNet - a point-level scene flow estimation network trained in a weakly-supervised manner and without object-based abstraction. Our approach predicts a binary segmentation mask that implicitly drives two parallel branches for ego-motion and scene flow. Unlike previous methods, we provide both branches with all input points and carefully integrate the binary mask into the feature extraction and losses. We also use a shared cost volume with local refinement that is updated at multiple scales without explicit clustering or rigidity assumptions. On realistic KITTI scenes, we show that our EgoFlowNet performs better than state-of-the-art methods in the presence of ground surface points.
Read more7/4/2024

0
Attack on Scene Flow using Point Clouds
Haniyeh Ehsani Oskouie, Mohammad-Shahram Moin, Shohreh Kasaei
Deep neural networks have made significant advancements in accurately estimating scene flow using point clouds, which is vital for many applications like video analysis, action recognition, and navigation. The robustness of these techniques, however, remains a concern, particularly in the face of adversarial attacks that have been proven to deceive state-of-the-art deep neural networks in many domains. Surprisingly, the robustness of scene flow networks against such attacks has not been thoroughly investigated. To address this problem, the proposed approach aims to bridge this gap by introducing adversarial white-box attacks specifically tailored for scene flow networks. Experimental results show that the generated adversarial examples obtain up to 33.7 relative degradation in average end-point error on the KITTI and FlyingThings3D datasets. The study also reveals the significant impact that attacks targeting point clouds in only one dimension or color channel have on average end-point error. Analyzing the success and failure of these attacks on the scene flow networks and their 2D optical flow network variants shows a higher vulnerability for the optical flow networks. Code is available at https://github.com/aheldis/Attack-on-Scene-Flow-using-Point-Clouds.git.
Read more8/28/2024

0
SSFlowNet: Semi-supervised Scene Flow Estimation On Point Clouds With Pseudo Label
Jingze Chen, Junfeng Yao, Qiqin Lin, Rongzhou Zhou, Lei Li
In the domain of supervised scene flow estimation, the process of manual labeling is both time-intensive and financially demanding. This paper introduces SSFlowNet, a semi-supervised approach for scene flow estimation, that utilizes a blend of labeled and unlabeled data, optimizing the balance between the cost of labeling and the precision of model training. SSFlowNet stands out through its innovative use of pseudo-labels, mainly reducing the dependency on extensively labeled datasets while maintaining high model accuracy. The core of our model is its emphasis on the intricate geometric structures of point clouds, both locally and globally, coupled with a novel spatial memory feature. This feature is adept at learning the geometric relationships between points over sequential time frames. By identifying similarities between labeled and unlabeled points, SSFlowNet dynamically constructs a correlation matrix to evaluate scene flow dependencies at individual point level. Furthermore, the integration of a flow consistency module within SSFlowNet enhances its capability to consistently estimate flow, an essential aspect for analyzing dynamic scenes. Empirical results demonstrate that SSFlowNet surpasses existing methods in pseudo-label generation and shows adaptability across varying data volumes. Moreover, our semi-supervised training technique yields promising outcomes even with different smaller ratio labeled data, marking a substantial advancement in the field of scene flow estimation.
Read more6/5/2024