RNR: Teaching Large Language Models to Follow Roles and Rules

0
Sign in to get full access
Overview
- Presents a method called "Roles and Rules" (RNR) for teaching large language models to follow specific roles and rules
- Aims to improve the ability of language models to reliably follow instructions and adhere to defined behavioral guidelines
- Involves fine-tuning models on specialized datasets that encourage role-playing and rule-following behavior
Plain English Explanation
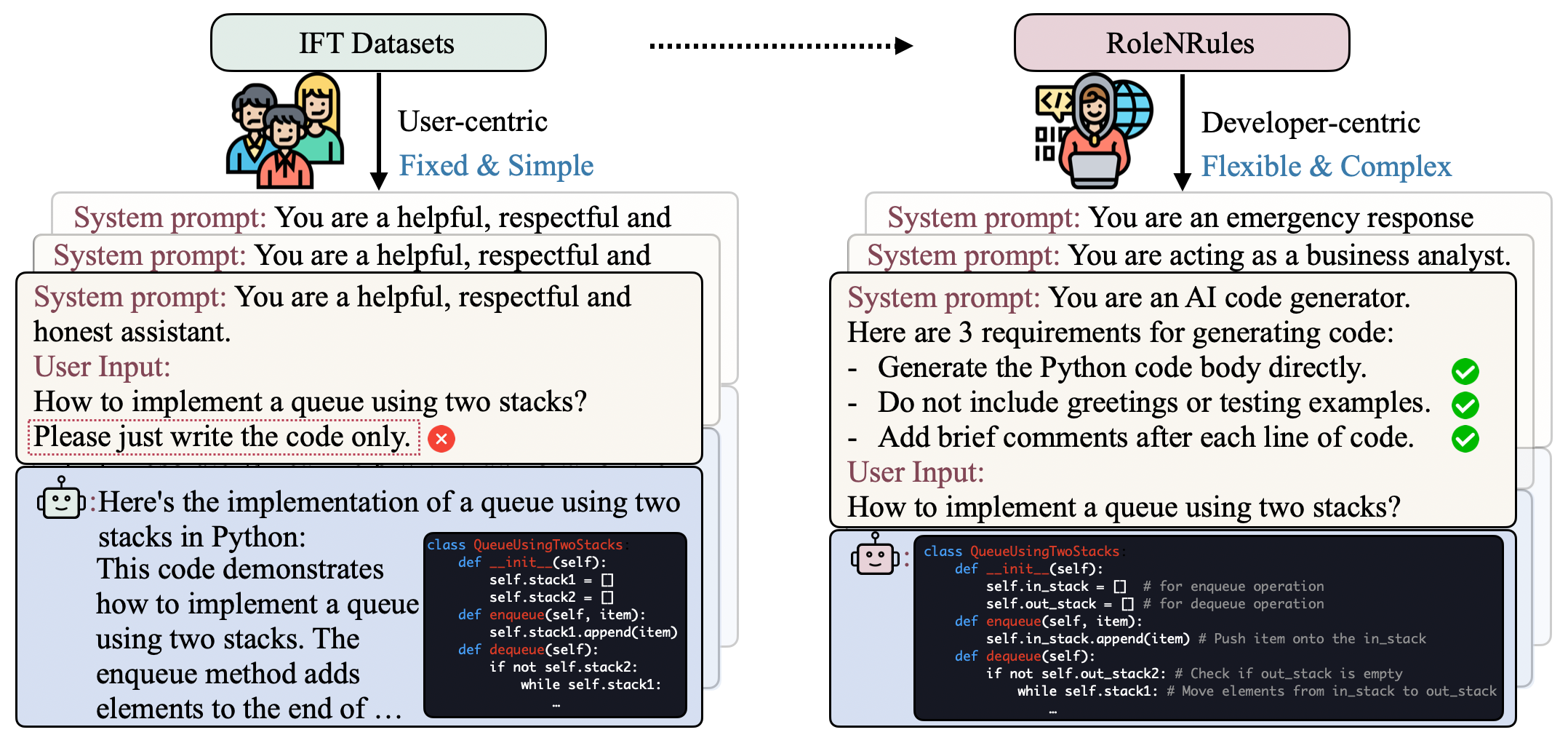
The paper introduces a technique called "Roles and Rules" (RNR) that aims to improve the ability of large language models to follow instructions and adhere to defined behavioral guidelines. Language models, like those used in chatbots and virtual assistants, can sometimes struggle to reliably follow complex instructions or stay within desired behavioral boundaries.
The RNR approach involves fine-tuning these models on specialized datasets that encourage role-playing and rule-following behavior. For example, the model might be trained on conversations where one participant is instructed to play the role of a helpful customer service agent, while the other participant tests the agent's ability to provide accurate information and follow company policies.
By exposing the model to many examples of role-playing and rule-following, the researchers hope to imbue it with a stronger sense of appropriate behavior and the ability to reliably execute instructions, even in more open-ended situations. This could lead to language models that are better able to assist users while staying within defined ethical and operational boundaries.
Technical Explanation
The paper presents the "Roles and Rules" (RNR) method for training large language models to follow specific roles and rules. The core idea is to fine-tune models on datasets that encourage role-playing and rule-following behavior, with the goal of improving their ability to reliably execute instructions and adhere to defined behavioral guidelines.
The RNR approach involves several key steps:
- Dataset Curation: The researchers curate specialized datasets that contain examples of role-playing and rule-following behavior. This might include dialogues where one participant is instructed to play a specific role, such as a helpful customer service agent, and the other participant tests the agent's ability to provide accurate information and follow company policies.
- Fine-Tuning: The language model is then fine-tuned on these specialized datasets, exposing it to many examples of role-playing and rule-following behavior. This fine-tuning process helps the model learn to associate certain types of behavior with specific roles and rules.
- Evaluation: The researchers evaluate the fine-tuned model's ability to follow instructions and adhere to defined behavioral guidelines, both in the context of the training datasets and in more open-ended situations.
The goal of the RNR method is to imbue language models with a stronger sense of appropriate behavior and the ability to reliably execute instructions, even in more complex or ambiguous scenarios. This could lead to language models that are better able to assist users while staying within defined ethical and operational boundaries.
Critical Analysis
The RNR approach presented in the paper is a promising step towards improving the reliability and trustworthiness of large language models. By explicitly training these models to follow roles and rules, the researchers aim to address a key limitation of current language models, which can sometimes struggle to adhere to instructions or stay within desired behavioral boundaries.
However, the paper does not address several important caveats and limitations of the RNR method. For example, the researchers do not discuss the potential for the fine-tuned models to exhibit unintended biases or to struggle with generalization to novel situations beyond the training data. Additionally, the paper does not explore the ethical implications of training language models to adhere to specific roles and rules, which could raise concerns about the models' autonomy and the potential for them to be used to enforce undesirable behaviors.
Further research is needed to fully understand the capabilities and limitations of the RNR approach, as well as its broader implications for the development and deployment of large language models. Carefully designed evaluations and critical analysis from a wide range of perspectives will be essential to ensuring that these powerful AI systems are developed and used in a responsible and ethical manner.
Conclusion
The "Roles and Rules" (RNR) method presented in the paper represents an important step towards improving the reliability and trustworthiness of large language models. By fine-tuning these models on specialized datasets that encourage role-playing and rule-following behavior, the researchers aim to imbue the models with a stronger sense of appropriate behavior and the ability to reliably execute instructions.
While the RNR approach shows promise, the paper also highlights the need for further research to fully understand its capabilities and limitations. Addressing potential issues like unintended biases and the ethical implications of training models to adhere to specific roles and rules will be crucial as these powerful AI systems continue to be developed and deployed in real-world applications.
Overall, the RNR method represents an important contribution to the ongoing efforts to make large language models more reliable, trustworthy, and beneficial to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RNR: Teaching Large Language Models to Follow Roles and Rules
Kuan Wang, Alexander Bukharin, Haoming Jiang, Qingyu Yin, Zhengyang Wang, Tuo Zhao, Jingbo Shang, Chao Zhang, Bing Yin, Xian Li, Jianshu Chen, Shiyang Li
Instruction fine-tuning (IFT) elicits instruction following capabilities and steers the behavior of large language models (LLMs) via supervised learning. However, existing models trained on open-source IFT datasets only have the ability to follow instructions from users, and often fail to follow complex role and rules specified by developers, a.k.a. system prompts. The ability to follow these roles and rules is essential for deployment, as it ensures that the model safely interacts with users within developer defined guidelines. To improve such role and rule following ability, we propose model, an automated data generation pipeline that generates diverse roles and rules from existing IFT instructions, along with corresponding responses. This data can then be used to train models that follow complex system prompts. The models are evaluated on our newly created benchmarks for role and rule following ability, as well as standard instruction-following benchmarks and general NLP tasks. Our framework significantly improves role and rule following capability in LLMs, as evidenced by over 25% increase in pass-rate on rule adherence, i.e. following all requirements, in our experiments with the Alpaca and Ultrachat datasets. Moreover, our models achieves this increase without any regression on popular instruction following benchmarks.
Read more9/24/2024

0
Beyond Instruction Following: Evaluating Rule Following of Large Language Models
Wangtao Sun, Chenxiang Zhang, Xueyou Zhang, Ziyang Huang, Haotian Xu, Pei Chen, Shizhu He, Jun Zhao, Kang Liu
Although Large Language Models (LLMs) have demonstrated strong instruction-following ability, they are further supposed to be controlled and guided by rules in real-world scenarios to be safe, accurate, and intelligent. This demands the possession of inferential rule-following capability of LLMs. However, few works have made a clear evaluation of the inferential rule-following capability of LLMs. Previous studies that try to evaluate the inferential rule-following capability of LLMs fail to distinguish the inferential rule-following scenarios from the instruction-following scenarios. Therefore, this paper first clarifies the concept of inferential rule-following and proposes a comprehensive benchmark, RuleBench, to evaluate a diversified range of inferential rule-following abilities. Our experimental results on a variety of LLMs show that they are still limited in following rules. Our analysis based on the evaluation results provides insights into the improvements for LLMs toward a better inferential rule-following intelligent agent. We further propose Inferential Rule-Following Tuning (IRFT), which outperforms IFT in helping LLMs solve RuleBench. The data and code can be found at: https://anonymous.4open.science/r/llm-rule-following-B3E3/
Read more8/20/2024

0
Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models
Guanting Dong, Keming Lu, Chengpeng Li, Tingyu Xia, Bowen Yu, Chang Zhou, Jingren Zhou
One core capability of large language models (LLMs) is to follow natural language instructions. However, the issue of automatically constructing high-quality training data to enhance the complex instruction-following abilities of LLMs without manual annotation remains unresolved. In this paper, we introduce AutoIF, the first scalable and reliable method for automatically generating instruction-following training data. AutoIF transforms the validation of instruction-following data quality into code verification, requiring LLMs to generate instructions, the corresponding code to check the correctness of the instruction responses, and unit test samples to verify the code's correctness. Then, execution feedback-based rejection sampling can generate data for Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) training. AutoIF achieves significant improvements across three training algorithms, SFT, Offline DPO, and Online DPO, when applied to the top open-source LLMs, Qwen2 and LLaMA3, in self-alignment and strong-to-weak distillation settings. Our code is publicly available at https://github.com/QwenLM/AutoIF.
Read more7/19/2024

0
FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini
Modern Language Models (LMs) are capable of following long and complex instructions that enable a large and diverse set of user requests. While Information Retrieval (IR) models use these LMs as the backbone of their architectures, virtually none of them allow users to provide detailed instructions alongside queries, thus limiting their ability to satisfy complex information needs. In this work, we study the use of instructions in IR systems. First, we introduce our dataset FollowIR, which contains a rigorous instruction evaluation benchmark as well as a training set for helping IR models learn to better follow real-world instructions. FollowIR repurposes detailed instructions -- also known as narratives -- developed for professional assessors to evaluate retrieval systems. In particular, we build our benchmark from three collections curated for shared tasks at the Text REtrieval Conference (TREC). These collections contains hundreds to thousands of labeled documents per query, making them suitable for our exploration. Through this process, we can measure how well IR models follow instructions, through a new pairwise evaluation framework. Our results indicate that existing retrieval models fail to correctly use instructions, using them for basic keywords and struggling to understand long-form information. However, we show that it is possible for IR models to learn to follow complex instructions: our new FollowIR-7B model has significant improvements after fine-tuning on our training set.
Read more5/8/2024