Beyond Instruction Following: Evaluating Rule Following of Large Language Models

0

Sign in to get full access
Overview
- Evaluates the rule-following abilities of large language models (LLMs) beyond just following instructions
- Introduces a new benchmark called FollowBench to assess LLMs' ability to follow multi-level, fine-grained constraints
- Compares LLMs' performance on FollowBench to their instruction-following ability, revealing discrepancies
- Provides insights into the capabilities and limitations of LLMs when it comes to complex rule-following tasks
Plain English Explanation
This paper examines how well large language models (LLMs) can follow rules and constraints, going beyond just following simple instructions. The researchers developed a new benchmark called FollowBench that tests LLMs' ability to follow multi-level, detailed rules and constraints.
When they compared LLMs' performance on FollowBench to their ability to follow instructions, they found some discrepancies. This suggests that LLMs may have limitations when it comes to complex rule-following tasks, even if they can perform well on simpler instruction-following.
The paper provides valuable insights into the current capabilities and limitations of LLMs, which is important as these models become more widely used in real-world applications that require adherence to rules and constraints.
Technical Explanation
The paper introduces a new benchmark called FollowBench to evaluate LLMs' ability to follow multi-level, fine-grained constraints. This goes beyond just testing instruction-following, which has been the focus of prior work like FollowIR and SIFO.
The researchers compared LLMs' performance on FollowBench to their instruction-following ability, as evaluated by benchmarks like Evaluating Instruction Following Ability of Large Language Models. They found that while LLMs can excel at simple instruction-following, they struggle more with complex, multi-level rule-following tasks.
This suggests that the capabilities of LLMs may be limited when it comes to adhering to detailed constraints, even if they can perform well on simpler tasks. The paper provides important insights into the current strengths and weaknesses of these large language models.
Critical Analysis
The paper acknowledges that FollowBench represents a challenging new benchmark for LLMs, going beyond the instruction-following tasks that have been the focus of prior work. This is an important step in more rigorously evaluating the capabilities of these models.
However, the paper also notes that FollowBench may not capture all aspects of real-world rule-following, and that further research is needed to understand the nuances of LLMs' abilities in this area. Additionally, the paper does not explore potential reasons why LLMs may struggle more with complex rule-following, which could be an interesting area for future study.
Overall, this paper makes a valuable contribution by shedding light on the limitations of LLMs when it comes to following detailed constraints, an important consideration as these models are deployed in high-stakes applications. Continued research in this area can help us better understand the capabilities and boundaries of these powerful language models.
Conclusion
This paper presents a new benchmark called FollowBench that evaluates large language models' ability to follow multi-level, fine-grained rules and constraints. By comparing LLMs' performance on FollowBench to their instruction-following ability, the researchers found that LLMs may have significant limitations when it comes to complex rule-following tasks, even if they can excel at simpler instruction-following.
These insights are crucial as LLMs become more widely deployed in real-world applications that require adherence to detailed rules and constraints. The paper lays the groundwork for further research into the nuances of LLMs' rule-following capabilities, which will be essential for understanding the appropriate use cases and limitations of these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Instruction Following: Evaluating Rule Following of Large Language Models
Wangtao Sun, Chenxiang Zhang, Xueyou Zhang, Ziyang Huang, Haotian Xu, Pei Chen, Shizhu He, Jun Zhao, Kang Liu
Although Large Language Models (LLMs) have demonstrated strong instruction-following ability, they are further supposed to be controlled and guided by rules in real-world scenarios to be safe, accurate, and intelligent. This demands the possession of inferential rule-following capability of LLMs. However, few works have made a clear evaluation of the inferential rule-following capability of LLMs. Previous studies that try to evaluate the inferential rule-following capability of LLMs fail to distinguish the inferential rule-following scenarios from the instruction-following scenarios. Therefore, this paper first clarifies the concept of inferential rule-following and proposes a comprehensive benchmark, RuleBench, to evaluate a diversified range of inferential rule-following abilities. Our experimental results on a variety of LLMs show that they are still limited in following rules. Our analysis based on the evaluation results provides insights into the improvements for LLMs toward a better inferential rule-following intelligent agent. We further propose Inferential Rule-Following Tuning (IRFT), which outperforms IFT in helping LLMs solve RuleBench. The data and code can be found at: https://anonymous.4open.science/r/llm-rule-following-B3E3/
Read more8/20/2024
💬
0
Evaluating Large Language Models at Evaluating Instruction Following
Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, Danqi Chen
As research in large language models (LLMs) continues to accelerate, LLM-based evaluation has emerged as a scalable and cost-effective alternative to human evaluations for comparing the ever increasing list of models. This paper investigates the efficacy of these ``LLM evaluators'', particularly in using them to assess instruction following, a metric that gauges how closely generated text adheres to the given instruction. We introduce a challenging meta-evaluation benchmark, LLMBar, designed to test the ability of an LLM evaluator in discerning instruction-following outputs. The authors manually curated 419 pairs of outputs, one adhering to instructions while the other diverging, yet may possess deceptive qualities that mislead an LLM evaluator, e.g., a more engaging tone. Contrary to existing meta-evaluation, we discover that different evaluators (i.e., combinations of LLMs and prompts) exhibit distinct performance on LLMBar and even the highest-scoring ones have substantial room for improvement. We also present a novel suite of prompting strategies that further close the gap between LLM and human evaluators. With LLMBar, we hope to offer more insight into LLM evaluators and foster future research in developing better instruction-following models.
Read more4/17/2024
0
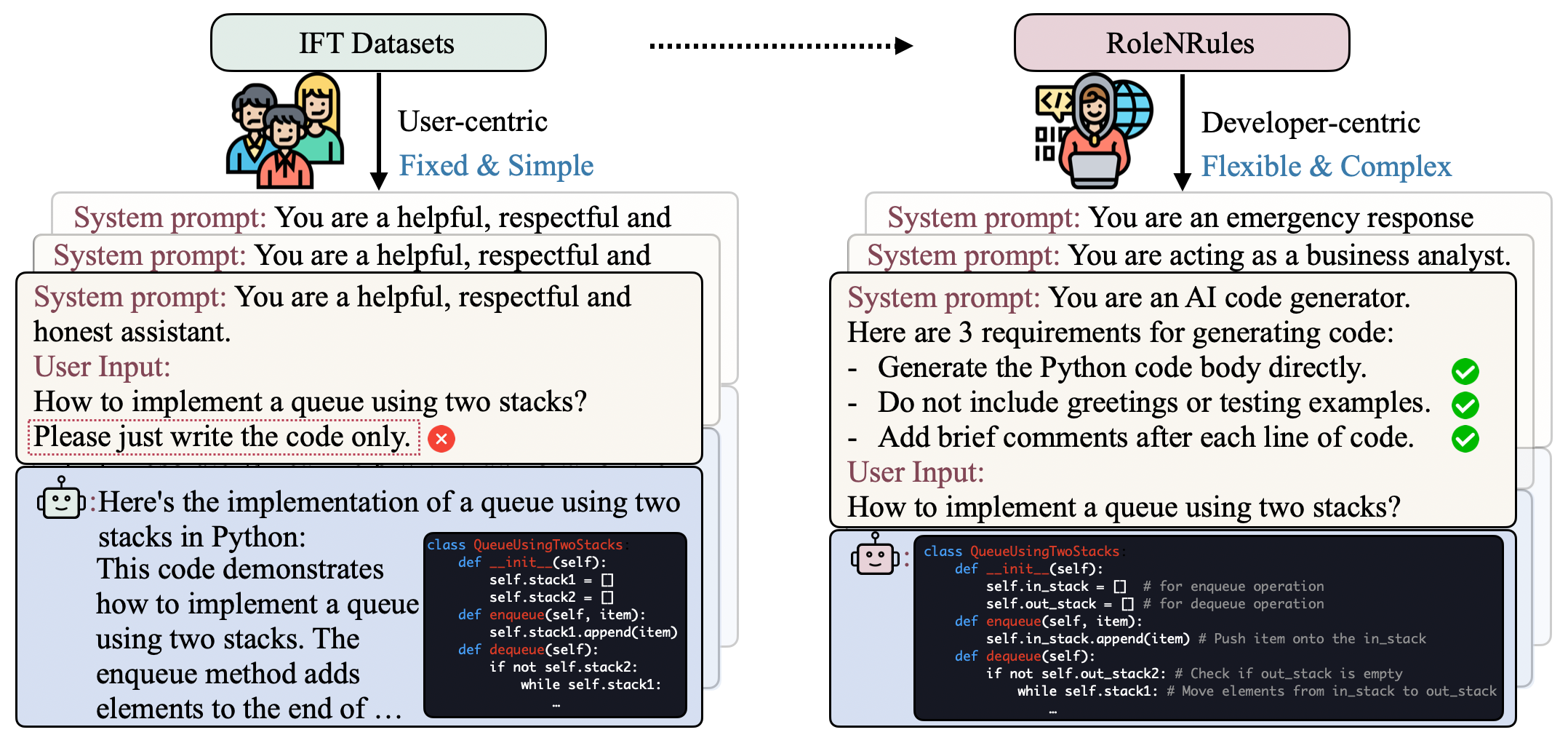
RNR: Teaching Large Language Models to Follow Roles and Rules
Kuan Wang, Alexander Bukharin, Haoming Jiang, Qingyu Yin, Zhengyang Wang, Tuo Zhao, Jingbo Shang, Chao Zhang, Bing Yin, Xian Li, Jianshu Chen, Shiyang Li
Instruction fine-tuning (IFT) elicits instruction following capabilities and steers the behavior of large language models (LLMs) via supervised learning. However, existing models trained on open-source IFT datasets only have the ability to follow instructions from users, and often fail to follow complex role and rules specified by developers, a.k.a. system prompts. The ability to follow these roles and rules is essential for deployment, as it ensures that the model safely interacts with users within developer defined guidelines. To improve such role and rule following ability, we propose model, an automated data generation pipeline that generates diverse roles and rules from existing IFT instructions, along with corresponding responses. This data can then be used to train models that follow complex system prompts. The models are evaluated on our newly created benchmarks for role and rule following ability, as well as standard instruction-following benchmarks and general NLP tasks. Our framework significantly improves role and rule following capability in LLMs, as evidenced by over 25% increase in pass-rate on rule adherence, i.e. following all requirements, in our experiments with the Alpaca and Ultrachat datasets. Moreover, our models achieves this increase without any regression on popular instruction following benchmarks.
Read more9/24/2024
0
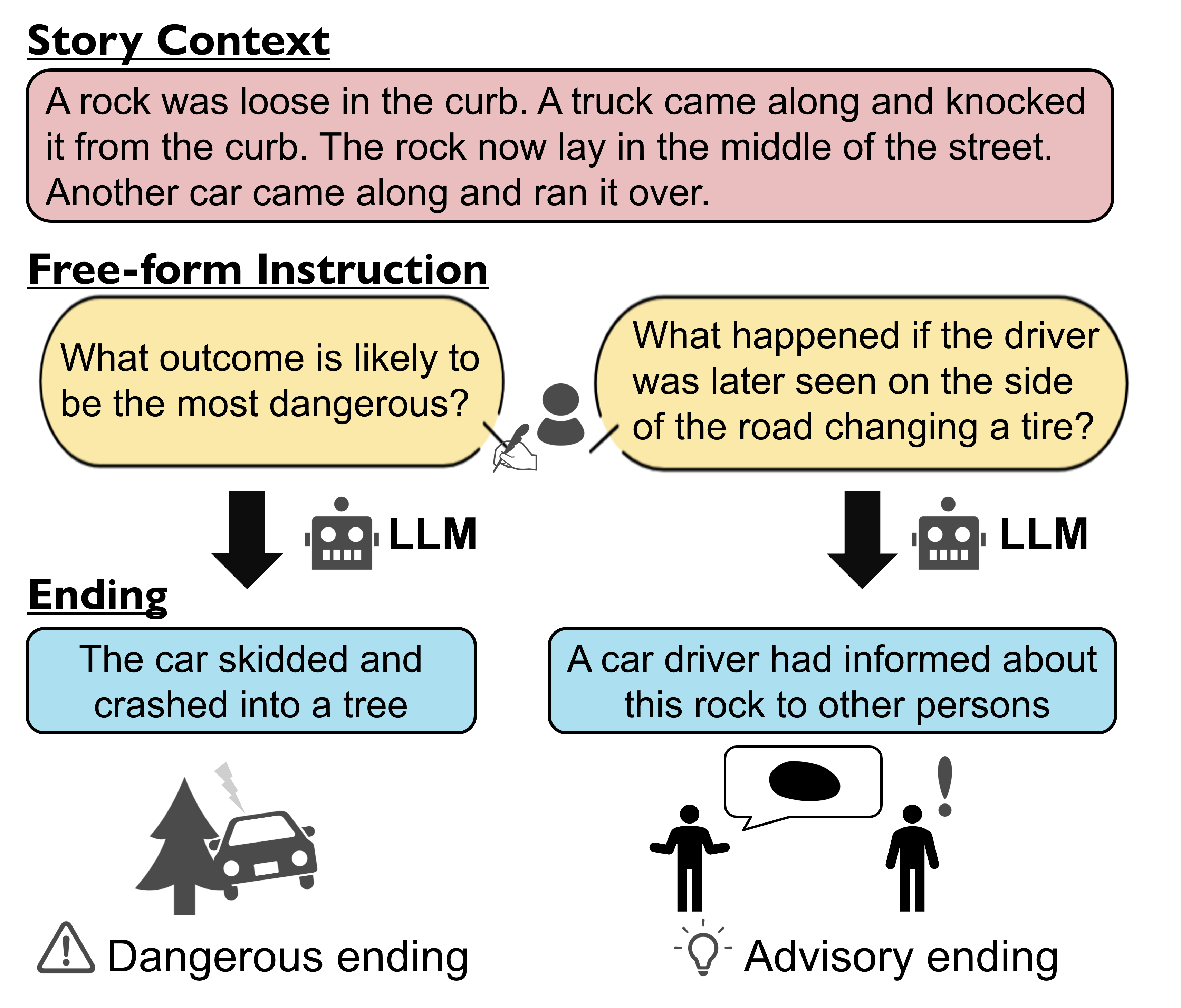
Evaluation of Instruction-Following Ability for Large Language Models on Story-Ending Generation
Rem Hida, Junki Ohmura, Toshiyuki Sekiya
Instruction-tuned Large Language Models (LLMs) have achieved remarkable performance across various benchmark tasks. While providing instructions to LLMs for guiding their generations is user-friendly, assessing their instruction-following capabilities is still unclarified due to a lack of evaluation metrics. In this paper, we focus on evaluating the instruction-following ability of LLMs in the context of story-ending generation, which requires diverse and context-specific instructions. We propose an automatic evaluation pipeline that utilizes a machine reading comprehension (MRC) model to determine whether the generated story-ending reflects instruction. Our findings demonstrate that our proposed metric aligns with human evaluation. Furthermore, our experiments confirm that recent open-source LLMs can achieve instruction-following performance close to GPT-3.5, as assessed through automatic evaluation.
Read more6/26/2024