FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions
2403.15246
0
0

Abstract
Modern Language Models (LMs) are capable of following long and complex instructions that enable a large and diverse set of user requests. While Information Retrieval (IR) models use these LMs as the backbone of their architectures, virtually none of them allow users to provide detailed instructions alongside queries, thus limiting their ability to satisfy complex information needs. In this work, we study the use of instructions in IR systems. First, we introduce our dataset FollowIR, which contains a rigorous instruction evaluation benchmark as well as a training set for helping IR models learn to better follow real-world instructions. FollowIR repurposes detailed instructions -- also known as narratives -- developed for professional assessors to evaluate retrieval systems. In particular, we build our benchmark from three collections curated for shared tasks at the Text REtrieval Conference (TREC). These collections contains hundreds to thousands of labeled documents per query, making them suitable for our exploration. Through this process, we can measure how well IR models follow instructions, through a new pairwise evaluation framework. Our results indicate that existing retrieval models fail to correctly use instructions, using them for basic keywords and struggling to understand long-form information. However, we show that it is possible for IR models to learn to follow complex instructions: our new FollowIR-7B model has significant improvements after fine-tuning on our training set.
Create account to get full access
Overview
- This paper introduces FollowIR, a new framework for evaluating and teaching information retrieval (IR) models to follow instructions.
- The authors focus on the ability of large language models (LLMs) to understand and follow complex natural language instructions, which is an important capability for real-world applications.
- They propose several novel evaluation tasks and training methods to improve the instruction-following abilities of IR models.
Plain English Explanation
The paper is about a new way to test and train information retrieval (IR) models, which are computer systems that help people find information online or in databases. The key idea is to see how well these models can understand and follow complex instructions written in natural language, rather than just searching for keywords.
Evaluating Large Language Models at Evaluating Instruction and When to Retrieve: Teaching LLMs to Utilize have explored related concepts of testing language models' ability to follow instructions.
The authors propose new ways to test IR models, such as having them complete tasks described in natural language, and new training methods to improve their instruction-following abilities. This is important because in the real world, people often want information retrieval systems that can understand and carry out their requests, not just find relevant documents.
By focusing on instruction-following, the researchers aim to make IR models more useful and user-friendly in practical applications.
Technical Explanation
The paper introduces the FollowIR framework, which consists of several new evaluation tasks and training methods to assess and improve the instruction-following capabilities of IR models.
The key evaluation tasks include:
- Instruction Completion: Given a natural language instruction, the model must complete the requested task.
- Instruction Paraphrasing: The model must rephrase the instruction in its own words.
- Instruction-Guided Retrieval: The model must retrieve relevant information to answer a question based on the provided instructions.
To train the models, the authors propose techniques such as:
- Instruction Augmentation: Expanding the training data with paraphrased or semantically-related instructions.
- Instruction-Guided Fine-Tuning: Fine-tuning the model on a mix of regular IR tasks and instruction-following tasks.
Instruction-Following Evaluation through Verbalizer Manipulation and InstructIE: Bilingual Instruction-Based Information Extraction Dataset have explored related ideas around evaluating and training language models for instruction-following.
The authors test their framework on several popular IR models and datasets, showing that FollowIR can effectively evaluate and improve the instruction-following capabilities of these systems.
Critical Analysis
The paper presents a well-designed framework for evaluating and enhancing the instruction-following abilities of IR models. The proposed tasks and training methods seem sensible and well-motivated, building on related work in this area.
One potential limitation is the reliance on existing IR datasets, which may not fully capture the nuances of real-world, open-ended instructions. Generative Information Retrieval Evaluation has discussed some of the challenges in evaluating IR models in more open-ended settings.
Additionally, the authors do not explore the generalization of the trained models to instructions outside the evaluated domains. Further research could investigate the transferability of the instruction-following skills to new contexts.
Overall, the FollowIR framework is a valuable contribution to the field of information retrieval, highlighting the importance of instruction-following and providing practical tools to advance this capability in real-world applications.
Conclusion
This paper introduces the FollowIR framework, which offers a new approach to evaluating and training information retrieval models to understand and follow natural language instructions. By focusing on instruction-following, the authors aim to make IR systems more user-friendly and effective in practical scenarios where people often want to communicate their information needs in natural language.
The proposed evaluation tasks and training methods show promising results, building on related work in this area. While the framework has some limitations, it represents an important step towards developing more intelligent and intuitive information retrieval systems that can better serve the needs of users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Large Language Models at Evaluating Instruction Following
Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, Danqi Chen
0
0
As research in large language models (LLMs) continues to accelerate, LLM-based evaluation has emerged as a scalable and cost-effective alternative to human evaluations for comparing the ever increasing list of models. This paper investigates the efficacy of these ``LLM evaluators'', particularly in using them to assess instruction following, a metric that gauges how closely generated text adheres to the given instruction. We introduce a challenging meta-evaluation benchmark, LLMBar, designed to test the ability of an LLM evaluator in discerning instruction-following outputs. The authors manually curated 419 pairs of outputs, one adhering to instructions while the other diverging, yet may possess deceptive qualities that mislead an LLM evaluator, e.g., a more engaging tone. Contrary to existing meta-evaluation, we discover that different evaluators (i.e., combinations of LLMs and prompts) exhibit distinct performance on LLMBar and even the highest-scoring ones have substantial room for improvement. We also present a novel suite of prompting strategies that further close the gap between LLM and human evaluators. With LLMBar, we hope to offer more insight into LLM evaluators and foster future research in developing better instruction-following models.
4/17/2024
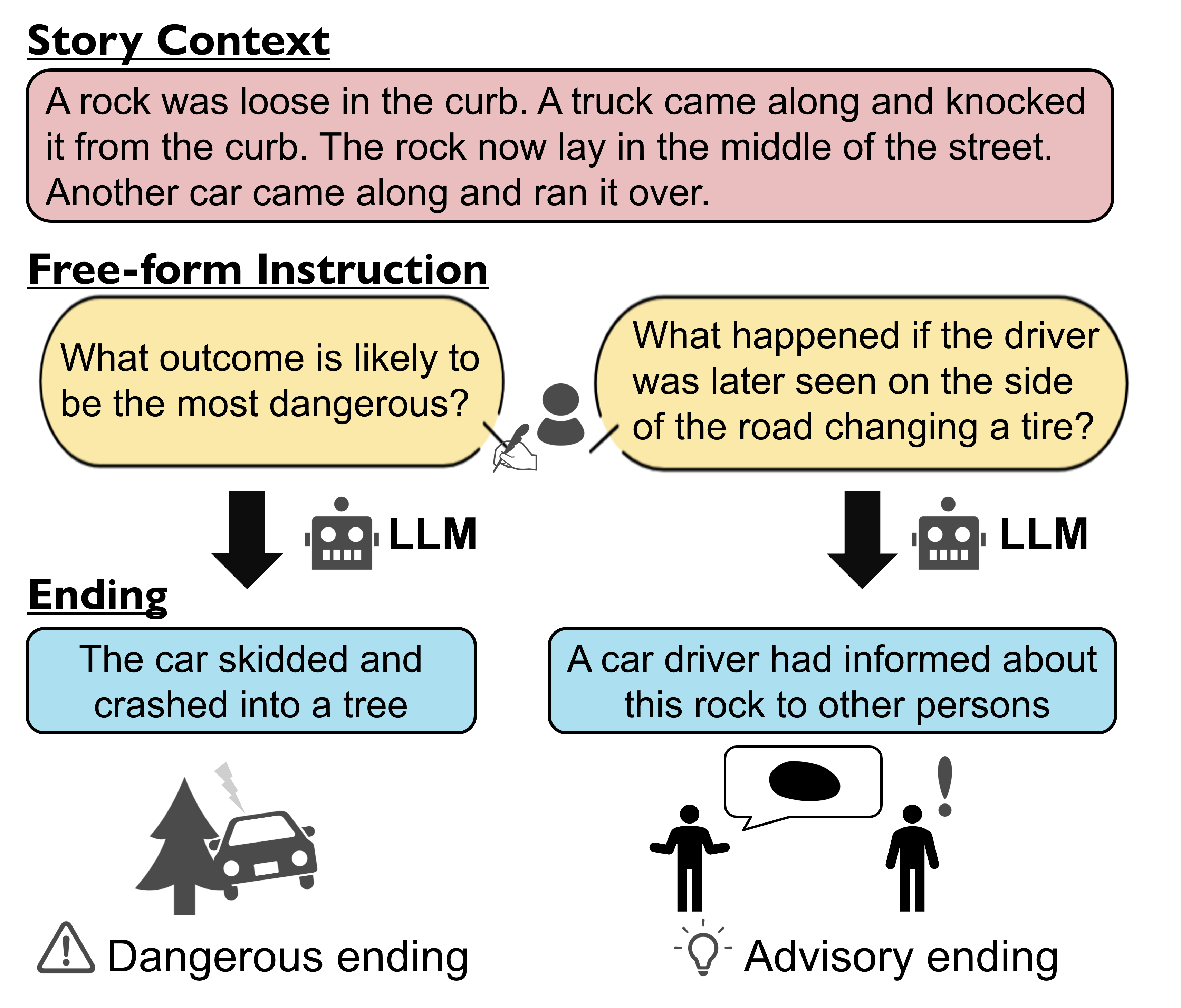
Evaluation of Instruction-Following Ability for Large Language Models on Story-Ending Generation
Rem Hida, Junki Ohmura, Toshiyuki Sekiya
0
0
Instruction-tuned Large Language Models (LLMs) have achieved remarkable performance across various benchmark tasks. While providing instructions to LLMs for guiding their generations is user-friendly, assessing their instruction-following capabilities is still unclarified due to a lack of evaluation metrics. In this paper, we focus on evaluating the instruction-following ability of LLMs in the context of story-ending generation, which requires diverse and context-specific instructions. We propose an automatic evaluation pipeline that utilizes a machine reading comprehension (MRC) model to determine whether the generated story-ending reflects instruction. Our findings demonstrate that our proposed metric aligns with human evaluation. Furthermore, our experiments confirm that recent open-source LLMs can achieve instruction-following performance close to GPT-3.5, as assessed through automatic evaluation.
6/26/2024
🛸
When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
Tiziano Labruna, Jon Ander Campos, Gorka Azkune
0
0
In this paper, we demonstrate how Large Language Models (LLMs) can effectively learn to use an off-the-shelf information retrieval (IR) system specifically when additional context is required to answer a given question. Given the performance of IR systems, the optimal strategy for question answering does not always entail external information retrieval; rather, it often involves leveraging the parametric memory of the LLM itself. Prior research has identified this phenomenon in the PopQA dataset, wherein the most popular questions are effectively addressed using the LLM's parametric memory, while less popular ones require IR system usage. Following this, we propose a tailored training approach for LLMs, leveraging existing open-domain question answering datasets. Here, LLMs are trained to generate a special token, , when they do not know the answer to a question. Our evaluation of the Adaptive Retrieval LLM (Adapt-LLM) on the PopQA dataset showcases improvements over the same LLM under three configurations: (i) retrieving information for all the questions, (ii) using always the parametric memory of the LLM, and (iii) using a popularity threshold to decide when to use a retriever. Through our analysis, we demonstrate that Adapt-LLM is able to generate the token when it determines that it does not know how to answer a question, indicating the need for IR, while it achieves notably high accuracy levels when it chooses to rely only on its parametric memory.
5/8/2024

INTERS: Unlocking the Power of Large Language Models in Search with Instruction Tuning
Yutao Zhu, Peitian Zhang, Chenghao Zhang, Yifei Chen, Binyu Xie, Zheng Liu, Ji-Rong Wen, Zhicheng Dou
0
0
Large language models (LLMs) have demonstrated impressive capabilities in various natural language processing tasks. Despite this, their application to information retrieval (IR) tasks is still challenging due to the infrequent occurrence of many IR-specific concepts in natural language. While prompt-based methods can provide task descriptions to LLMs, they often fall short in facilitating a comprehensive understanding and execution of IR tasks, thereby limiting LLMs' applicability. To address this gap, in this work, we explore the potential of instruction tuning to enhance LLMs' proficiency in IR tasks. We introduce a novel instruction tuning dataset, INTERS, encompassing 20 tasks across three fundamental IR categories: query understanding, document understanding, and query-document relationship understanding. The data are derived from 43 distinct datasets with manually written templates. Our empirical results reveal that INTERS significantly boosts the performance of various publicly available LLMs, such as LLaMA, Mistral, and Phi, in IR tasks. Furthermore, we conduct extensive experiments to analyze the effects of instruction design, template diversity, few-shot demonstrations, and the volume of instructions on performance. We make our dataset and the fine-tuned models publicly accessible at https://github.com/DaoD/INTERS.
5/29/2024