Robust and Explainable Fine-Grained Visual Classification with Transfer Learning: A Dual-Carriageway Framework

0
Sign in to get full access
Overview
- This paper proposes a "Dual-Carriageway Framework" for robust and explainable fine-grained visual classification using transfer learning.
- The framework aims to improve the performance and interpretability of deep learning models for fine-grained visual tasks, such as distinguishing between similar bird or car species.
- It leverages dual neural networks and a novel contrastive learning approach to achieve both high accuracy and model explainability.
Plain English Explanation
The paper introduces a new way to train deep learning models for fine-grained visual classification tasks, which involve distinguishing between very similar objects or classes, like different species of birds or car models. This can be challenging because the visual differences between the classes are often subtle.
The key idea is to use two neural networks that work together in a "Dual-Carriageway Framework." One network focuses on achieving high classification accuracy, while the other network aims to make the model more interpretable, meaning you can better understand how it is making its decisions.
The authors use a technique called contrastive learning to train these two networks. Contrastive learning helps the networks learn useful features by comparing similar and dissimilar examples. This allows the model to not only classify the images accurately, but also highlight the important visual cues it uses to tell the classes apart.
By combining these two goals - high accuracy and interpretability - the framework produces deep learning models that are both powerful and transparent. This can be valuable in applications where you need to trust the model's decisions, such as medical diagnosis or self-driving cars.
Technical Explanation
The paper proposes a "Dual-Carriageway Framework" for fine-grained visual classification tasks. The framework consists of two neural networks trained using a novel contrastive learning approach:
-
Accuracy-Oriented Network: This network is optimized for achieving high classification accuracy on the target task, such as distinguishing between similar bird or car species.
-
Interpretability-Oriented Network: This network is trained to learn visual features that can be used to explain the model's decision-making process, making it more interpretable.
The two networks are trained simultaneously using a contrastive learning objective. Contrastive learning compares similar and dissimilar examples to help the networks learn discriminative features. This allows the Accuracy-Oriented Network to achieve high performance, while the Interpretability-Oriented Network learns to highlight the key visual cues used for classification.
The authors evaluate their approach on several fine-grained visual classification datasets, including CUB-200-2011, StanfordCars, and FGVC-Aircraft. They demonstrate that their Dual-Carriageway Framework outperforms several state-of-the-art models in terms of both classification accuracy and model interpretability.
Critical Analysis
The paper presents a promising approach for achieving both high performance and interpretability in fine-grained visual classification tasks. The authors' use of contrastive learning to train the two networks simultaneously is a novel and interesting technique.
However, the paper does not provide a thorough discussion of the limitations or potential issues with the Dual-Carriageway Framework. For example, it is unclear how the framework would scale to larger and more complex datasets, or how sensitive the performance is to the choice of hyperparameters.
Additionally, the paper could have delved deeper into the interpretability aspect of the framework, providing more details on the type of explanations generated by the Interpretability-Oriented Network and how they can be used in practical applications. Advancing Ante-hoc Explainable Models Through Generative Approaches and The Road to Clarity: Exploring the Explainable AI World provide valuable context on the challenges and opportunities in this area.
Overall, the Dual-Carriageway Framework is a promising contribution to the field of fine-grained visual classification, and the authors' focus on both accuracy and interpretability is a valuable direction for the community to explore further.
Conclusion
This paper introduces a novel "Dual-Carriageway Framework" for robust and explainable fine-grained visual classification using transfer learning. The framework leverages two neural networks trained with a contrastive learning approach to achieve high accuracy and model interpretability simultaneously.
The key contribution of this work is the ability to produce deep learning models that not only perform well on challenging fine-grained tasks, but also provide transparency into their decision-making process. This can be valuable in applications where trust and accountability are important, such as medical diagnosis or autonomous systems.
While the paper presents promising results, it could benefit from a more thorough discussion of the limitations and potential issues with the framework. Nonetheless, the Dual-Carriageway approach is an interesting and relevant development in the field of explainable AI, and the authors' work opens up new avenues for further research and practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robust and Explainable Fine-Grained Visual Classification with Transfer Learning: A Dual-Carriageway Framework
Zheming Zuo, Joseph Smith, Jonathan Stonehouse, Boguslaw Obara
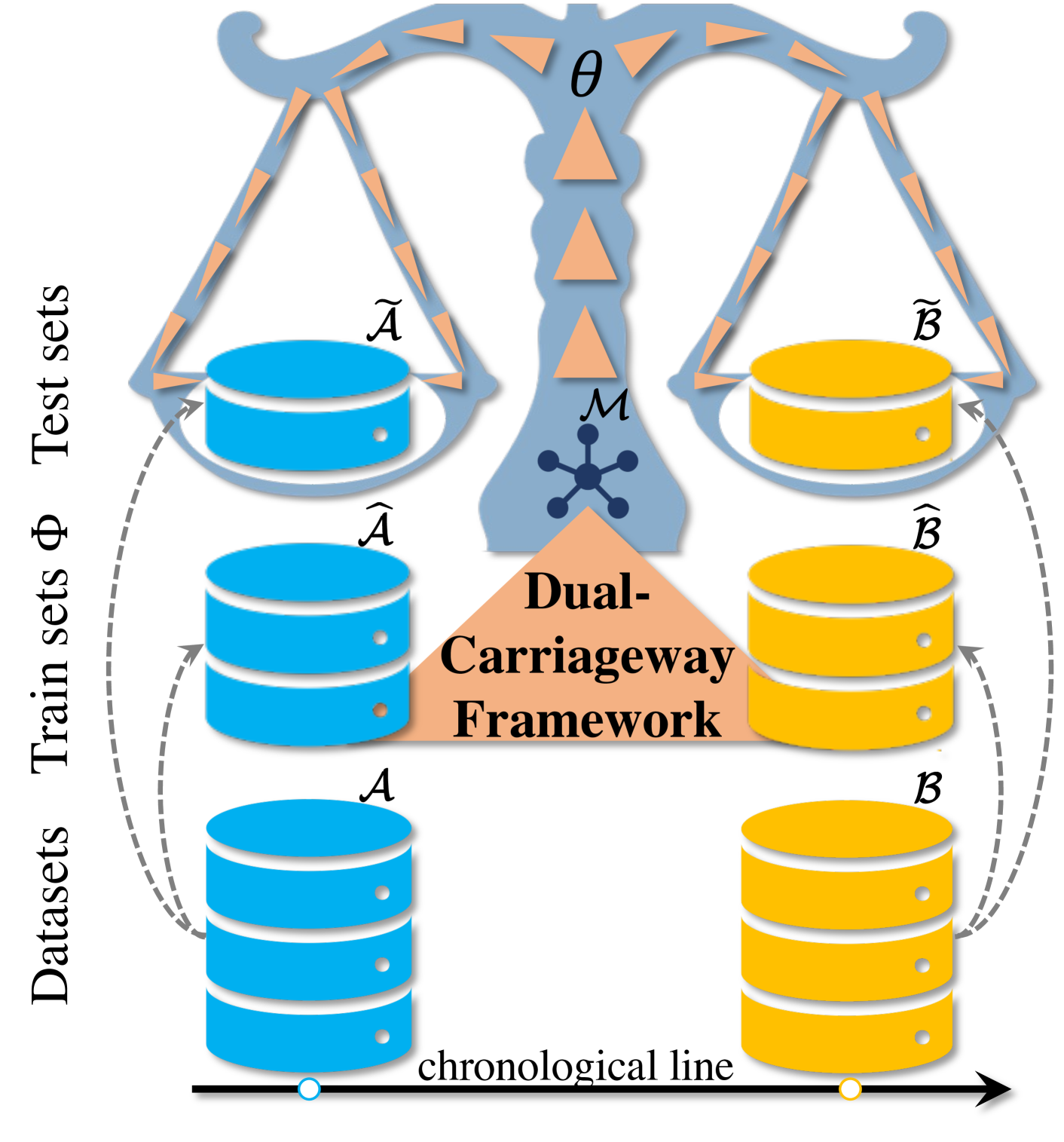
In the realm of practical fine-grained visual classification applications rooted in deep learning, a common scenario involves training a model using a pre-existing dataset. Subsequently, a new dataset becomes available, prompting the desire to make a pivotal decision for achieving enhanced and leveraged inference performance on both sides: Should one opt to train datasets from scratch or fine-tune the model trained on the initial dataset using the newly released dataset? The existing literature reveals a lack of methods to systematically determine the optimal training strategy, necessitating explainability. To this end, we present an automatic best-suit training solution searching framework, the Dual-Carriageway Framework (DCF), to fill this gap. DCF benefits from the design of a dual-direction search (starting from the pre-existing or the newly released dataset) where five different training settings are enforced. In addition, DCF is not only capable of figuring out the optimal training strategy with the capability of avoiding overfitting but also yields built-in quantitative and visual explanations derived from the actual input and weights of the trained model. We validated DCF's effectiveness through experiments with three convolutional neural networks (ResNet18, ResNet34 and Inception-v3) on two temporally continued commercial product datasets. Results showed fine-tuning pathways outperformed training-from-scratch ones by up to 2.13% and 1.23% on the pre-existing and new datasets, respectively, in terms of mean accuracy. Furthermore, DCF identified reflection padding as the superior padding method, enhancing testing accuracy by 3.72% on average. This framework stands out for its potential to guide the development of robust and explainable AI solutions in fine-grained visual classification tasks.
Read more5/10/2024

0
Data-free Knowledge Distillation for Fine-grained Visual Categorization
Renrong Shao, Wei Zhang, Jianhua Yin, Jun Wang
Data-free knowledge distillation (DFKD) is a promising approach for addressing issues related to model compression, security privacy, and transmission restrictions. Although the existing methods exploiting DFKD have achieved inspiring achievements in coarse-grained classification, in practical applications involving fine-grained classification tasks that require more detailed distinctions between similar categories, sub-optimal results are obtained. To address this issue, we propose an approach called DFKD-FGVC that extends DFKD to fine-grained visual categorization~(FGVC) tasks. Our approach utilizes an adversarial distillation framework with attention generator, mixed high-order attention distillation, and semantic feature contrast learning. Specifically, we introduce a spatial-wise attention mechanism to the generator to synthesize fine-grained images with more details of discriminative parts. We also utilize the mixed high-order attention mechanism to capture complex interactions among parts and the subtle differences among discriminative features of the fine-grained categories, paying attention to both local features and semantic context relationships. Moreover, we leverage the teacher and student models of the distillation framework to contrast high-level semantic feature maps in the hyperspace, comparing variances of different categories. We evaluate our approach on three widely-used FGVC benchmarks (Aircraft, Cars196, and CUB200) and demonstrate its superior performance.
Read more4/19/2024

0
DCNN: Dual Cross-current Neural Networks Realized Using An Interactive Deep Learning Discriminator for Fine-grained Objects
Da Fu, Mingfei Rong, Eun-Hu Kim, Hao Huang, Witold Pedrycz
Accurate classification of fine-grained images remains a challenge in backbones based on convolutional operations or self-attention mechanisms. This study proposes novel dual-current neural networks (DCNN), which combine the advantages of convolutional operations and self-attention mechanisms to improve the accuracy of fine-grained image classification. The main novel design features for constructing a weakly supervised learning backbone model DCNN include (a) extracting heterogeneous data, (b) keeping the feature map resolution unchanged, (c) expanding the receptive field, and (d) fusing global representations and local features. Experimental results demonstrated that using DCNN as the backbone network for classifying certain fine-grained benchmark datasets achieved performance advantage improvements of 13.5--19.5% and 2.2--12.9%, respectively, compared to other advanced convolution or attention-based fine-grained backbones.
Read more5/8/2024
🏅
0
Detail Reinforcement Diffusion Model: Augmentation Fine-Grained Visual Categorization in Few-Shot Conditions
Tianxu Wu, Shuo Ye, Shuhuang Chen, Qinmu Peng, Xinge You
The challenge in fine-grained visual categorization lies in how to explore the subtle differences between different subclasses and achieve accurate discrimination. Previous research has relied on large-scale annotated data and pre-trained deep models to achieve the objective. However, when only a limited amount of samples is available, similar methods may become less effective. Diffusion models have been widely adopted in data augmentation due to their outstanding diversity in data generation. However, the high level of detail required for fine-grained images makes it challenging for existing methods to be directly employed. To address this issue, we propose a novel approach termed the detail reinforcement diffusion model~(DRDM), which leverages the rich knowledge of large models for fine-grained data augmentation and comprises two key components including discriminative semantic recombination (DSR) and spatial knowledge reference~(SKR). Specifically, DSR is designed to extract implicit similarity relationships from the labels and reconstruct the semantic mapping between labels and instances, which enables better discrimination of subtle differences between different subclasses. Furthermore, we introduce the SKR module, which incorporates the distributions of different datasets as references in the feature space. This allows the SKR to aggregate the high-dimensional distribution of subclass features in few-shot FGVC tasks, thus expanding the decision boundary. Through these two critical components, we effectively utilize the knowledge from large models to address the issue of data scarcity, resulting in improved performance for fine-grained visual recognition tasks. Extensive experiments demonstrate the consistent performance gain offered by our DRDM.
Read more5/16/2024