Robust Reinforcement Learning from Corrupted Human Feedback

0
Sign in to get full access
Overview
- This paper presents a method for robust reinforcement learning (RL) from corrupted human feedback.
- The proposed approach aims to address the challenge of learning from noisy or biased human feedback, which can occur in real-world RL scenarios.
- The authors introduce a novel training pipeline that can effectively learn from diverse human preferences, even in the presence of corrupted feedback.
Plain English Explanation
Human feedback can be a valuable source of information for reinforcement learning (RL) systems, as it can provide insights into what actions or behaviors are preferred. However, this feedback can sometimes be noisy, biased, or even outright incorrect, which can negatively impact the RL agent's performance.
The researchers in this paper have developed a new method to help RL agents learn effectively even when the human feedback they receive is not perfect. Their approach involves a multi-stage training pipeline that can handle diverse human preferences and filter out corrupted or unreliable feedback.
The key idea is to first learn a general preference model from the available human feedback, and then use that model to detect and downweight any corrupted feedback during the RL training process. This helps the agent focus on the reliable feedback and learn a more robust policy that can generalize well to various situations.
By addressing the challenge of learning from noisy human input, this research could pave the way for more effective and trustworthy RL systems that can be deployed in real-world applications where user feedback is an important component.
Technical Explanation
The paper introduces a novel training pipeline for robust reinforcement learning from corrupted human feedback. The proposed method consists of several key components:
-
Preference Learning: The authors first train a preference model to capture the general patterns in the available human feedback, using techniques like contrastive preference learning.
-
Corruption Detection: During the RL training phase, the preference model is used to detect and downweight any corrupted or unreliable human feedback, based on its divergence from the learned preferences.
-
Iterative RL: The RL agent is then trained using the filtered feedback, with the preference model being updated iteratively to adapt to the agent's improving performance. This helps the agent learn a robust policy that can generalize well to diverse human preferences.
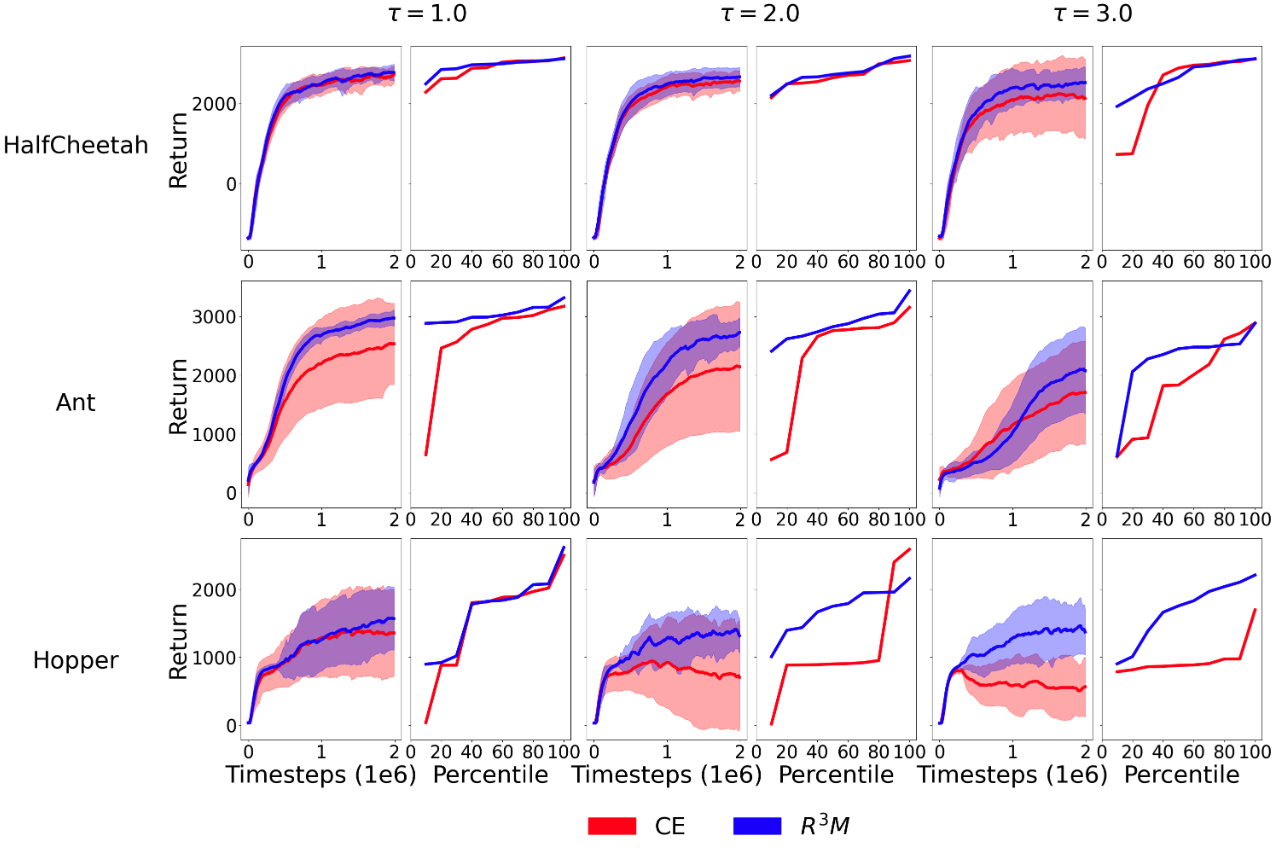
The authors evaluate their approach on several benchmark environments and show that it outperforms previous methods in terms of sample efficiency and final performance, especially when the human feedback is subject to different types of corruption, such as random noise or systematic biases.
Critical Analysis
The paper presents a compelling approach to address a important challenge in the field of reinforcement learning – learning from noisy or biased human feedback. The authors have carefully designed a multi-stage training pipeline that can effectively handle diverse and corrupted feedback, which is a common issue in real-world RL applications.
One potential limitation of the proposed method is that it relies on the availability of a substantial amount of human feedback data to learn a reliable preference model. In scenarios where only limited feedback is available, the preference learning stage may not be as effective, and the corruption detection may not be as accurate.
Additionally, the paper does not explore the robustness of the method to more complex or adversarial forms of feedback corruption, such as targeted attempts to mislead the RL agent. Further research could investigate the resilience of the approach in such more challenging settings.
Overall, the paper makes a valuable contribution to the field of robust reinforcement learning, and the proposed training pipeline could have important implications for the development of more reliable and trustworthy RL systems that can effectively leverage human guidance.
Conclusion
This paper presents a novel approach for robust reinforcement learning from corrupted human feedback. The key innovation is a multi-stage training pipeline that can effectively learn from diverse human preferences, even in the presence of noisy or biased feedback.
By incorporating a preference learning stage to capture general patterns in the feedback, and then using this model to detect and downweight corrupted inputs during RL training, the proposed method can help RL agents learn more robust and generalizable policies. This work represents an important step towards developing RL systems that can reliably leverage human guidance in real-world applications.
While the paper has some limitations, such as the dependence on a large amount of feedback data, the authors have demonstrated the effectiveness of their approach on various benchmark environments. Further research in this direction could lead to even more powerful and trustworthy RL systems that can seamlessly integrate human knowledge and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robust Reinforcement Learning from Corrupted Human Feedback
Alexander Bukharin, Ilgee Hong, Haoming Jiang, Zichong Li, Qingru Zhang, Zixuan Zhang, Tuo Zhao
Reinforcement learning from human feedback (RLHF) provides a principled framework for aligning AI systems with human preference data. For various reasons, e.g., personal bias, context ambiguity, lack of training, etc, human annotators may give incorrect or inconsistent preference labels. To tackle this challenge, we propose a robust RLHF approach -- $R^3M$, which models the potentially corrupted preference label as sparse outliers. Accordingly, we formulate the robust reward learning as an $ell_1$-regularized maximum likelihood estimation problem. Computationally, we develop an efficient alternating optimization algorithm, which only incurs negligible computational overhead compared with the standard RLHF approach. Theoretically, we prove that under proper regularity conditions, $R^3M$ can consistently learn the underlying reward and identify outliers, provided that the number of outlier labels scales sublinearly with the preference sample size. Furthermore, we remark that $R^3M$ is versatile and can be extended to various preference optimization methods, including direct preference optimization (DPO). Our experiments on robotic control and natural language generation with large language models (LLMs) show that $R^3M$ improves robustness of the reward against several types of perturbations to the preference data.
Read more7/10/2024
🏅
0
Online Iterative Reinforcement Learning from Human Feedback with General Preference Model
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
We study Reinforcement Learning from Human Feedback (RLHF) under a general preference oracle. In particular, we do not assume that there exists a reward function and the preference signal is drawn from the Bradley-Terry model as most of the prior works do. We consider a standard mathematical formulation, the reverse-KL regularized minimax game between two LLMs for RLHF under general preference oracle. The learning objective of this formulation is to find a policy so that it is consistently preferred by the KL-regularized preference oracle over any competing LLMs. We show that this framework is strictly more general than the reward-based one, and propose sample-efficient algorithms for both the offline learning from a pre-collected preference dataset and online learning where we can query the preference oracle along the way of training. Empirical studies verify the effectiveness of the proposed framework.
Read more4/26/2024
0
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, Natasha Jaques
Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
Read more8/20/2024
🏅
0
Reinforcement Learning from Diverse Human Preferences
Wanqi Xue, Bo An, Shuicheng Yan, Zhongwen Xu
The complexity of designing reward functions has been a major obstacle to the wide application of deep reinforcement learning (RL) techniques. Describing an agent's desired behaviors and properties can be difficult, even for experts. A new paradigm called reinforcement learning from human preferences (or preference-based RL) has emerged as a promising solution, in which reward functions are learned from human preference labels among behavior trajectories. However, existing methods for preference-based RL are limited by the need for accurate oracle preference labels. This paper addresses this limitation by developing a method for crowd-sourcing preference labels and learning from diverse human preferences. The key idea is to stabilize reward learning through regularization and correction in a latent space. To ensure temporal consistency, a strong constraint is imposed on the reward model that forces its latent space to be close to the prior distribution. Additionally, a confidence-based reward model ensembling method is designed to generate more stable and reliable predictions. The proposed method is tested on a variety of tasks in DMcontrol and Meta-world and has shown consistent and significant improvements over existing preference-based RL algorithms when learning from diverse feedback, paving the way for real-world applications of RL methods.
Read more5/9/2024