Robust and Resource-Efficient Data-Free Knowledge Distillation by Generative Pseudo Replay

0
🐍
Sign in to get full access
Overview
- This paper introduces a practical method for data-free knowledge distillation (KD)
- KD allows transferring knowledge from a large, trained neural network (teacher) to a smaller, more compact one (student)
- Existing methods rely on a validation set to monitor the student's accuracy, but this data may not be available during distillation
- The proposed approach uses a generative network to model the distribution of synthetic data, preventing knowledge degradation without storing samples
Plain English Explanation
Knowledge distillation is a technique used to compress the knowledge of a large, complex neural network into a smaller, more efficient one. The idea is to take what the large network has learned and transfer it to the smaller network, so the smaller network can perform similarly well without needing as much computing power.
Typically, this is done by using a validation set - a collection of real-world data - to track the smaller network's performance and ensure it is learning effectively. However, in some cases, this validation data may not be available when you want to do the distillation.
The authors of this paper propose a solution to this problem. Instead of relying on real validation data, they use a generative network to create synthetic data that the smaller network can be trained on. This generative network is trained to model the distribution of the previously generated synthetic data, so the smaller network can continually be exposed to new, relevant samples without needing to store the original data.
This approach helps prevent the smaller network from experiencing "knowledge degradation" - where its performance starts to worsen over time due to the distribution shift of the synthetic data. By keeping the synthetic data generation consistent, the smaller network can steadily improve its performance throughout the distillation process.
Technical Explanation
The key technical contribution of this paper is the use of a Variational Autoencoder (VAE) to model the distribution of the synthetic data used for data-free knowledge distillation.
Existing data-free KD methods rely on storing and rehearsing the generated synthetic samples, which can lead to large memory overhead and privacy concerns. The proposed approach avoids these issues by using the VAE to generate new samples on-the-fly, without needing to store the original samples.
The VAE is trained with a customized objective function to learn optimal representations of the synthetic data. This allows the generative pseudo replay technique to produce samples that are well-aligned with the student network's learning, preventing knowledge degradation over the course of distillation.
The authors evaluate their method on image classification benchmarks and show that it can optimize the expected value of the distilled model's accuracy while eliminating the large memory overhead associated with sample-storing methods.
Critical Analysis
The authors acknowledge that their method still relies on the availability of a pre-trained teacher model, which may not always be the case in practical scenarios. They also note that the performance of their approach is sensitive to the quality of the synthetic data generated by the VAE.
One potential area for further research would be investigating techniques to make the VAE more robust to distribution shift, as the authors mention that significant distribution differences between the synthetic and real data can still lead to performance degradation.
Additionally, the paper does not provide a detailed analysis of the computational overhead of training the VAE, which could be an important consideration for real-world deployment. It would be valuable to understand the trade-offs between the memory savings and the additional training computational requirements.
Conclusion
This paper presents a practical solution for data-free knowledge distillation that addresses the limitations of existing methods. By modeling the distribution of synthetic data using a Variational Autoencoder, the proposed approach can prevent knowledge degradation in the student network without the need for storing large amounts of data.
The demonstrated performance improvements on image classification tasks suggest that this technique could be a valuable tool for deploying compact, high-performing neural networks in resource-constrained environments where access to the original training data is limited.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
0
Robust and Resource-Efficient Data-Free Knowledge Distillation by Generative Pseudo Replay
Kuluhan Binici, Shivam Aggarwal, Nam Trung Pham, Karianto Leman, Tulika Mitra
Data-Free Knowledge Distillation (KD) allows knowledge transfer from a trained neural network (teacher) to a more compact one (student) in the absence of original training data. Existing works use a validation set to monitor the accuracy of the student over real data and report the highest performance throughout the entire process. However, validation data may not be available at distillation time either, making it infeasible to record the student snapshot that achieved the peak accuracy. Therefore, a practical data-free KD method should be robust and ideally provide monotonically increasing student accuracy during distillation. This is challenging because the student experiences knowledge degradation due to the distribution shift of the synthetic data. A straightforward approach to overcome this issue is to store and rehearse the generated samples periodically, which increases the memory footprint and creates privacy concerns. We propose to model the distribution of the previously observed synthetic samples with a generative network. In particular, we design a Variational Autoencoder (VAE) with a training objective that is customized to learn the synthetic data representations optimally. The student is rehearsed by the generative pseudo replay technique, with samples produced by the VAE. Hence knowledge degradation can be prevented without storing any samples. Experiments on image classification benchmarks show that our method optimizes the expected value of the distilled model accuracy while eliminating the large memory overhead incurred by the sample-storing methods.
Read more7/30/2024

0
Small Scale Data-Free Knowledge Distillation
He Liu, Yikai Wang, Huaping Liu, Fuchun Sun, Anbang Yao
Data-free knowledge distillation is able to utilize the knowledge learned by a large teacher network to augment the training of a smaller student network without accessing the original training data, avoiding privacy, security, and proprietary risks in real applications. In this line of research, existing methods typically follow an inversion-and-distillation paradigm in which a generative adversarial network on-the-fly trained with the guidance of the pre-trained teacher network is used to synthesize a large-scale sample set for knowledge distillation. In this paper, we reexamine this common data-free knowledge distillation paradigm, showing that there is considerable room to improve the overall training efficiency through a lens of ``small-scale inverted data for knowledge distillation. In light of three empirical observations indicating the importance of how to balance class distributions in terms of synthetic sample diversity and difficulty during both data inversion and distillation processes, we propose Small Scale Data-free Knowledge Distillation SSD-KD. In formulation, SSD-KD introduces a modulating function to balance synthetic samples and a priority sampling function to select proper samples, facilitated by a dynamic replay buffer and a reinforcement learning strategy. As a result, SSD-KD can perform distillation training conditioned on an extremely small scale of synthetic samples (e.g., 10X less than the original training data scale), making the overall training efficiency one or two orders of magnitude faster than many mainstream methods while retaining superior or competitive model performance, as demonstrated on popular image classification and semantic segmentation benchmarks. The code is available at https://github.com/OSVAI/SSD-KD.
Read more6/13/2024
0
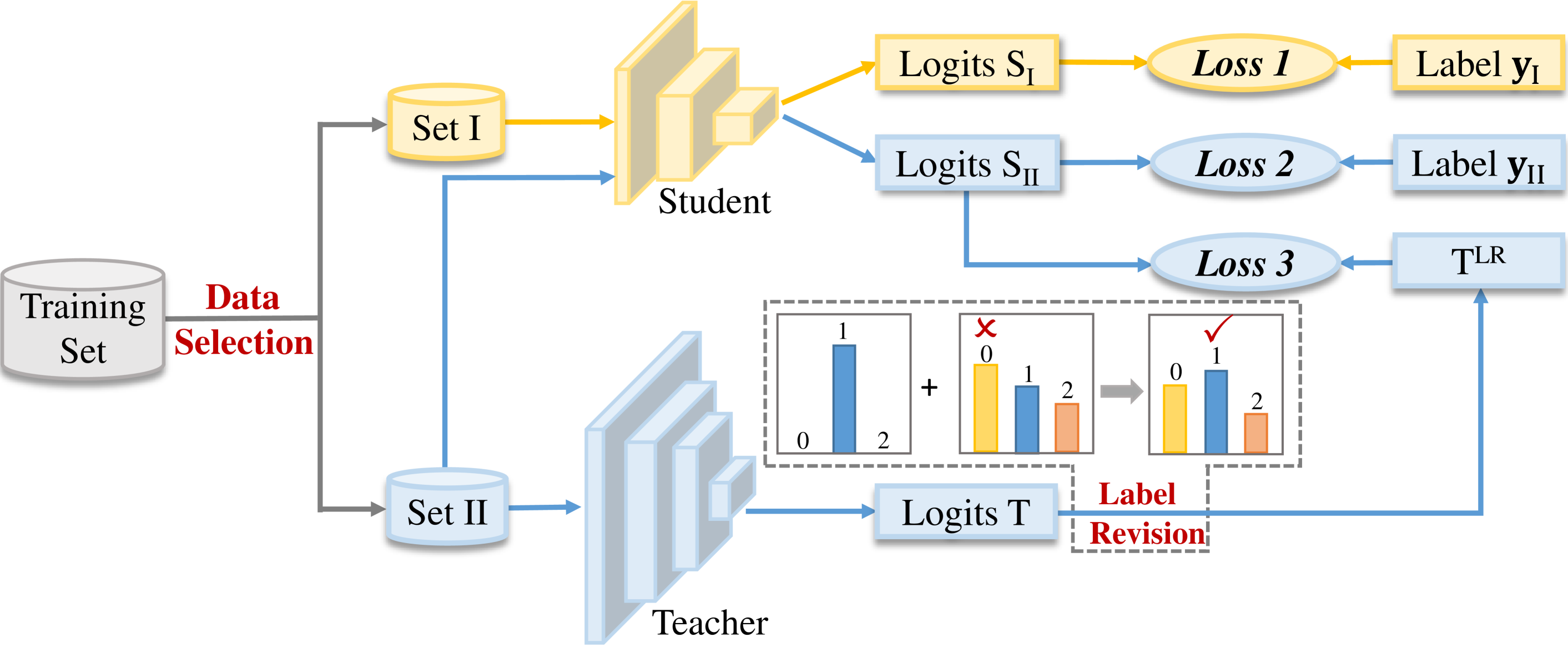
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
Read more4/8/2024

0
ReffAKD: Resource-efficient Autoencoder-based Knowledge Distillation
Divyang Doshi, Jung-Eun Kim
In this research, we propose an innovative method to boost Knowledge Distillation efficiency without the need for resource-heavy teacher models. Knowledge Distillation trains a smaller ``student'' model with guidance from a larger ``teacher'' model, which is computationally costly. However, the main benefit comes from the soft labels provided by the teacher, helping the student grasp nuanced class similarities. In our work, we propose an efficient method for generating these soft labels, thereby eliminating the need for a large teacher model. We employ a compact autoencoder to extract essential features and calculate similarity scores between different classes. Afterward, we apply the softmax function to these similarity scores to obtain a soft probability vector. This vector serves as valuable guidance during the training of the student model. Our extensive experiments on various datasets, including CIFAR-100, Tiny Imagenet, and Fashion MNIST, demonstrate the superior resource efficiency of our approach compared to traditional knowledge distillation methods that rely on large teacher models. Importantly, our approach consistently achieves similar or even superior performance in terms of model accuracy. We also perform a comparative study with various techniques recently developed for knowledge distillation showing our approach achieves competitive performance with using significantly less resources. We also show that our approach can be easily added to any logit based knowledge distillation method. This research contributes to making knowledge distillation more accessible and cost-effective for practical applications, making it a promising avenue for improving the efficiency of model training. The code for this work is available at, https://github.com/JEKimLab/ReffAKD.
Read more4/16/2024