On the Robustness of Language Guidance for Low-Level Vision Tasks: Findings from Depth Estimation

0

Sign in to get full access
Overview
- This paper investigates the robustness of language guidance for low-level vision tasks, focusing specifically on depth estimation.
- The researchers explore how language-guided depth estimation models perform in the presence of various distribution shifts, such as changes in scene content, viewpoint, or imaging conditions.
- The findings provide insights into the strengths and limitations of incorporating language information into depth estimation, with implications for developing more robust and generalizable computer vision systems.
Plain English Explanation
Depth estimation is the task of determining the distance between objects in an image and the camera. This is a fundamental problem in computer vision, with applications in areas like robotics, augmented reality, and autonomous vehicles.
The researchers in this paper wanted to understand how well depth estimation models that use language information perform when faced with different types of changes or "distribution shifts" in the input data. For example, they looked at how the models handled changes in the scene content, camera viewpoint, or lighting conditions.
By testing the models in these diverse scenarios, the researchers were able to gain insights into the strengths and weaknesses of incorporating language guidance into depth estimation. This information is important for developing more robust and generalizable computer vision systems that can work reliably in the real world, where conditions are constantly changing.
The key findings from this research suggest that language-guided depth estimation models can be quite effective, but they also have some limitations. The models generally performed well when faced with changes in scene content or viewpoint, but struggled more with changes in imaging conditions like lighting or camera settings.
These insights can help guide the development of future depth estimation models, ensuring they are more versatile and can handle the unpredictable nature of real-world environments. The researchers also highlight areas for further investigation, such as exploring alternative ways of incorporating language information or designing more robust training procedures.
Technical Explanation
The paper proposes a novel framework for language-guided depth estimation, building on prior work in WordDepth: Variational Language Prior for Monocular Depth Estimation and Reflectance Estimation and Proximity Sensing by Vision and Language.
The core idea is to leverage language information, in the form of text descriptions, to guide the depth estimation process. This is achieved by incorporating a language-based prior into the depth estimation model, which encourages the model to produce depth maps that are consistent with the accompanying text descriptions.
To assess the robustness of this language-guided approach, the researchers conducted a series of experiments evaluating the model's performance under various distribution shifts, including changes in scene content, viewpoint, and imaging conditions. This analysis was inspired by prior work on Analyzing the Roles of Language and Vision in Learning and Repurposing Diffusion-based Image Generators for Monocular Depth Estimation.
The experiments revealed that the language-guided depth estimation model generally performed well when faced with changes in scene content and viewpoint, demonstrating the benefits of incorporating language information. However, the model's performance degraded more significantly when confronted with changes in imaging conditions, such as lighting variations.
These findings highlight the strengths and limitations of the language-guided approach and provide valuable insights for the development of more robust and generalizable depth estimation systems. The researchers also discuss potential avenues for future work, such as exploring alternative ways of integrating language information or designing more diverse training datasets to improve the model's ability to handle a wider range of distribution shifts.
Critical Analysis
The researchers provide a comprehensive analysis of the robustness of language-guided depth estimation models, which is a crucial step in understanding the practical limitations and potential of this approach.
One notable strength of the study is the systematic evaluation of the models' performance under various distribution shifts, which helps identify the specific scenarios where language guidance is most effective and where it falls short. This level of nuance is essential for guiding future research and development efforts.
However, the paper could have delved deeper into the reasons behind the observed performance differences across the different distribution shift scenarios. A more detailed exploration of the underlying mechanisms and model vulnerabilities could have provided additional insights and direction for improving the robustness of language-guided depth estimation.
Additionally, the paper could have discussed the potential implications of the findings for other low-level vision tasks beyond depth estimation, as the insights gained may be relevant to a broader range of computer vision applications that could benefit from language-guided approaches.
Overall, this work represents a valuable contribution to the growing body of research on the intersection of language and vision in machine learning. The findings provide a solid foundation for continued exploration into developing more robust and generalizable computer vision systems that can leverage the complementary strengths of language and visual information.
Conclusion
This paper presents a comprehensive investigation into the robustness of language-guided depth estimation models, exploring their performance under various distribution shifts in scene content, viewpoint, and imaging conditions.
The key findings suggest that incorporating language information can indeed improve the depth estimation process, but the models also exhibit limitations in their ability to handle certain types of distribution shifts, particularly those related to changes in imaging conditions.
These insights have important implications for the development of more robust and generalizable computer vision systems, guiding future research efforts to explore alternative ways of integrating language information or designing more diverse training datasets to improve the models' versatility.
By shedding light on the strengths and weaknesses of language-guided depth estimation, this work contributes to a deeper understanding of the role of language in low-level vision tasks and sets the stage for ongoing advancements in this rapidly evolving field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Robustness of Language Guidance for Low-Level Vision Tasks: Findings from Depth Estimation
Agneet Chatterjee, Tejas Gokhale, Chitta Baral, Yezhou Yang
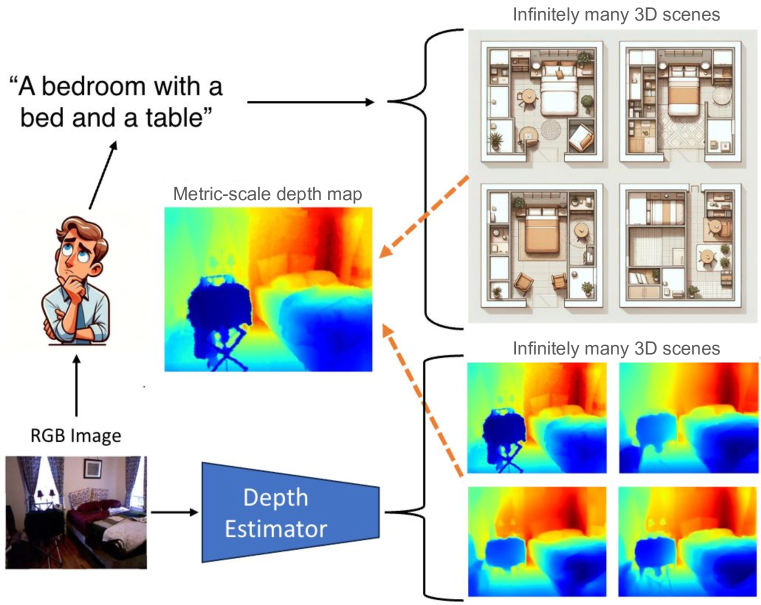
Recent advances in monocular depth estimation have been made by incorporating natural language as additional guidance. Although yielding impressive results, the impact of the language prior, particularly in terms of generalization and robustness, remains unexplored. In this paper, we address this gap by quantifying the impact of this prior and introduce methods to benchmark its effectiveness across various settings. We generate low-level sentences that convey object-centric, three-dimensional spatial relationships, incorporate them as additional language priors and evaluate their downstream impact on depth estimation. Our key finding is that current language-guided depth estimators perform optimally only with scene-level descriptions and counter-intuitively fare worse with low level descriptions. Despite leveraging additional data, these methods are not robust to directed adversarial attacks and decline in performance with an increase in distribution shift. Finally, to provide a foundation for future research, we identify points of failures and offer insights to better understand these shortcomings. With an increasing number of methods using language for depth estimation, our findings highlight the opportunities and pitfalls that require careful consideration for effective deployment in real-world settings
Read more4/15/2024
0
WorDepth: Variational Language Prior for Monocular Depth Estimation
Ziyao Zeng, Daniel Wang, Fengyu Yang, Hyoungseob Park, Yangchao Wu, Stefano Soatto, Byung-Woo Hong, Dong Lao, Alex Wong
Three-dimensional (3D) reconstruction from a single image is an ill-posed problem with inherent ambiguities, i.e. scale. Predicting a 3D scene from text description(s) is similarly ill-posed, i.e. spatial arrangements of objects described. We investigate the question of whether two inherently ambiguous modalities can be used in conjunction to produce metric-scaled reconstructions. To test this, we focus on monocular depth estimation, the problem of predicting a dense depth map from a single image, but with an additional text caption describing the scene. To this end, we begin by encoding the text caption as a mean and standard deviation; using a variational framework, we learn the distribution of the plausible metric reconstructions of 3D scenes corresponding to the text captions as a prior. To select a specific reconstruction or depth map, we encode the given image through a conditional sampler that samples from the latent space of the variational text encoder, which is then decoded to the output depth map. Our approach is trained alternatingly between the text and image branches: in one optimization step, we predict the mean and standard deviation from the text description and sample from a standard Gaussian, and in the other, we sample using a (image) conditional sampler. Once trained, we directly predict depth from the encoded text using the conditional sampler. We demonstrate our approach on indoor (NYUv2) and outdoor (KITTI) scenarios, where we show that language can consistently improve performance in both.
Read more6/4/2024

0
Large Language Models Can Understanding Depth from Monocular Images
Zhongyi Xia, Tianzhao Wu
Monocular depth estimation is a critical function in computer vision applications. This paper shows that large language models (LLMs) can effectively interpret depth with minimal supervision, using efficient resource utilization and a consistent neural network architecture. We introduce LLM-MDE, a multimodal framework that deciphers depth through language comprehension. Specifically, LLM-MDE employs two main strategies to enhance the pretrained LLM's capability for depth estimation: cross-modal reprogramming and an adaptive prompt estimation module. These strategies align vision representations with text prototypes and automatically generate prompts based on monocular images, respectively. Comprehensive experiments on real-world MDE datasets confirm the effectiveness and superiority of LLM-MDE, which excels in few-/zero-shot tasks while minimizing resource use. The source code is available.
Read more9/4/2024

0
Can 3D Vision-Language Models Truly Understand Natural Language?
Weipeng Deng, Jihan Yang, Runyu Ding, Jiahui Liu, Yijiang Li, Xiaojuan Qi, Edith Ngai
Rapid advancements in 3D vision-language (3D-VL) tasks have opened up new avenues for human interaction with embodied agents or robots using natural language. Despite this progress, we find a notable limitation: existing 3D-VL models exhibit sensitivity to the styles of language input, struggling to understand sentences with the same semantic meaning but written in different variants. This observation raises a critical question: Can 3D vision-language models truly understand natural language? To test the language understandability of 3D-VL models, we first propose a language robustness task for systematically assessing 3D-VL models across various tasks, benchmarking their performance when presented with different language style variants. Importantly, these variants are commonly encountered in applications requiring direct interaction with humans, such as embodied robotics, given the diversity and unpredictability of human language. We propose a 3D Language Robustness Dataset, designed based on the characteristics of human language, to facilitate the systematic study of robustness. Our comprehensive evaluation uncovers a significant drop in the performance of all existing models across various 3D-VL tasks. Even the state-of-the-art 3D-LLM fails to understand some variants of the same sentences. Further in-depth analysis suggests that the existing models have a fragile and biased fusion module, which stems from the low diversity of the existing dataset. Finally, we propose a training-free module driven by LLM, which improves language robustness. Datasets and code will be available at github.
Read more7/4/2024