Reflectance Estimation for Proximity Sensing by Vision-Language Models: Utilizing Distributional Semantics for Low-Level Cognition in Robotics

0

Sign in to get full access
Overview
- This paper explores the use of vision-language models for estimating surface reflectance properties, which can be used for proximity sensing in robotics.
- The researchers investigate how distributional semantics and low-level cognition in vision-language models can be leveraged to infer physical properties from images.
- The findings could have applications in areas like robot navigation, object manipulation, and scene understanding.
Plain English Explanation
Vision-language models are a type of artificial intelligence that can understand and generate human-like language based on visual information. In this research, the authors explore how these models can be used to estimate the reflectance properties of surfaces, which is important for robots to understand their physical environment.
Reflectance refers to how much light a surface reflects. By understanding the reflectance of different objects and materials, robots can better sense their proximity to things and navigate their surroundings. This is a key capability for tasks like navigating safely, manipulating objects, and understanding complex scenes.
The researchers in this paper demonstrate that vision-language models, which are trained on vast amounts of visual and textual data, can pick up on subtle cues about material properties and use that knowledge to estimate reflectance. This is an example of how these powerful models can be applied to low-level perception tasks that are crucial for robotics.
By leveraging the semantic knowledge captured in vision-language models, the researchers show it's possible to infer physical characteristics of the world from images alone, without needing specialized sensors. This could lead to more versatile and affordable robotic systems that can better understand and interact with their environments.
Technical Explanation
The key idea behind this research is to utilize the rich semantic knowledge captured by vision-language models to infer physical properties like surface reflectance, which can be used for proximity sensing in robotics applications.
The researchers propose a framework that takes an image as input and outputs an estimated reflectance map. At the heart of this system is a vision-language model that has been pre-trained on large-scale datasets of images paired with corresponding text descriptions. By learning the associations between visual features and semantic concepts, these models can pick up on subtle cues about material properties and surface characteristics.
To leverage this capability, the authors fine-tune the vision-language model on a dataset of images with ground-truth reflectance information. This allows the model to learn the mapping between visual appearance and quantitative reflectance values. They experiment with different model architectures and training strategies to optimize the reflectance estimation performance.
The results demonstrate that the vision-language-based approach can accurately estimate surface reflectance, outperforming baseline methods that rely on specialized sensors or hand-crafted features. The researchers analyze the model's internal representations and find that it is indeed capturing semantically meaningful information about materials and surfaces, which enables the effective inference of physical properties.
Critical Analysis
One key strength of this research is the innovative use of vision-language models for a low-level perception task that is traditionally done with specialized sensors. By leveraging the broad semantic knowledge in these models, the authors show it's possible to infer physical properties from images alone, which could lead to more affordable and versatile robotic systems.
However, the paper does acknowledge some limitations of the current approach. The experiments are conducted in a controlled lab setting with known lighting conditions, and the performance may degrade in more complex, real-world environments. Additionally, the reflectance estimation is limited to a single surface property, and extending the framework to handle more nuanced material characteristics could be an area for future research.
Another potential concern is the reliance on large, pre-trained vision-language models, which can be computationally intensive and may raise privacy or security concerns when deployed on robotic platforms. Exploring more efficient or on-device implementation strategies could help address these challenges.
Overall, this research demonstrates the potential of vision-language models for bridging the gap between high-level semantics and low-level physical reasoning, which is an important direction for advancing robotic perception and cognition. Further exploration of these techniques in diverse real-world scenarios could yield valuable insights and inspire new applications in the field of robotics.
Conclusion
This paper presents a novel approach to estimating surface reflectance using vision-language models, which can be a valuable capability for proximity sensing and scene understanding in robotics. By leveraging the semantic knowledge captured in these powerful models, the researchers show it's possible to infer physical properties from images alone, without relying on specialized sensors.
The findings suggest that vision-language models can be a versatile tool for bridging the gap between high-level cognition and low-level perception, which could lead to more affordable and adaptive robotic systems. While the current implementation has some limitations, the general approach opens up exciting possibilities for further research and development in the field of robotic perception and interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reflectance Estimation for Proximity Sensing by Vision-Language Models: Utilizing Distributional Semantics for Low-Level Cognition in Robotics
Masashi Osada, Gustavo A. Garcia Ricardez, Yosuke Suzuki, Tadahiro Taniguchi
Large language models (LLMs) and vision-language models (VLMs) have been increasingly used in robotics for high-level cognition, but their use for low-level cognition, such as interpreting sensor information, remains underexplored. In robotic grasping, estimating the reflectance of objects is crucial for successful grasping, as it significantly impacts the distance measured by proximity sensors. We investigate whether LLMs can estimate reflectance from object names alone, leveraging the embedded human knowledge in distributional semantics, and if the latent structure of language in VLMs positively affects image-based reflectance estimation. In this paper, we verify that 1) LLMs such as GPT-3.5 and GPT-4 can estimate an object's reflectance using only text as input; and 2) VLMs such as CLIP can increase their generalization capabilities in reflectance estimation from images. Our experiments show that GPT-4 can estimate an object's reflectance using only text input with a mean error of 14.7%, lower than the image-only ResNet. Moreover, CLIP achieved the lowest mean error of 11.8%, while GPT-3.5 obtained a competitive 19.9% compared to ResNet's 17.8%. These results suggest that the distributional semantics in LLMs and VLMs increases their generalization capabilities, and the knowledge acquired by VLMs benefits from the latent structure of language.
Read more4/15/2024
0
From Words to Poses: Enhancing Novel Object Pose Estimation with Vision Language Models
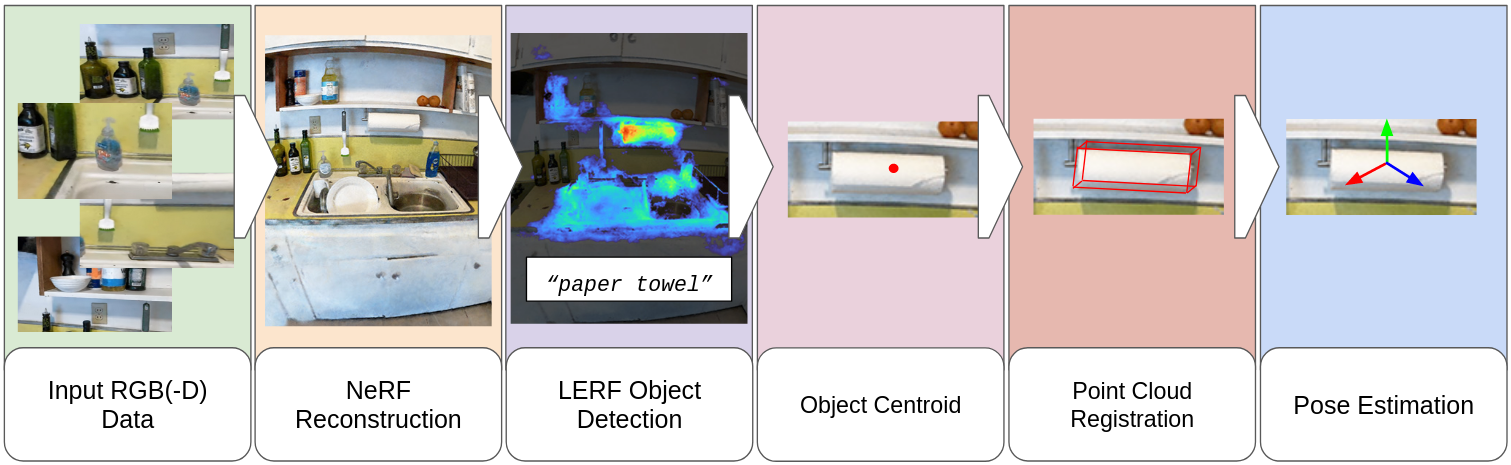
Tessa Pulli, Stefan Thalhammer, Simon Schwaiger, Markus Vincze
Robots are increasingly envisioned to interact in real-world scenarios, where they must continuously adapt to new situations. To detect and grasp novel objects, zero-shot pose estimators determine poses without prior knowledge. Recently, vision language models (VLMs) have shown considerable advances in robotics applications by establishing an understanding between language input and image input. In our work, we take advantage of VLMs zero-shot capabilities and translate this ability to 6D object pose estimation. We propose a novel framework for promptable zero-shot 6D object pose estimation using language embeddings. The idea is to derive a coarse location of an object based on the relevancy map of a language-embedded NeRF reconstruction and to compute the pose estimate with a point cloud registration method. Additionally, we provide an analysis of LERF's suitability for open-set object pose estimation. We examine hyperparameters, such as activation thresholds for relevancy maps and investigate the zero-shot capabilities on an instance- and category-level. Furthermore, we plan to conduct robotic grasping experiments in a real-world setting.
Read more9/10/2024
0
Vision-Language Model-based Physical Reasoning for Robot Liquid Perception
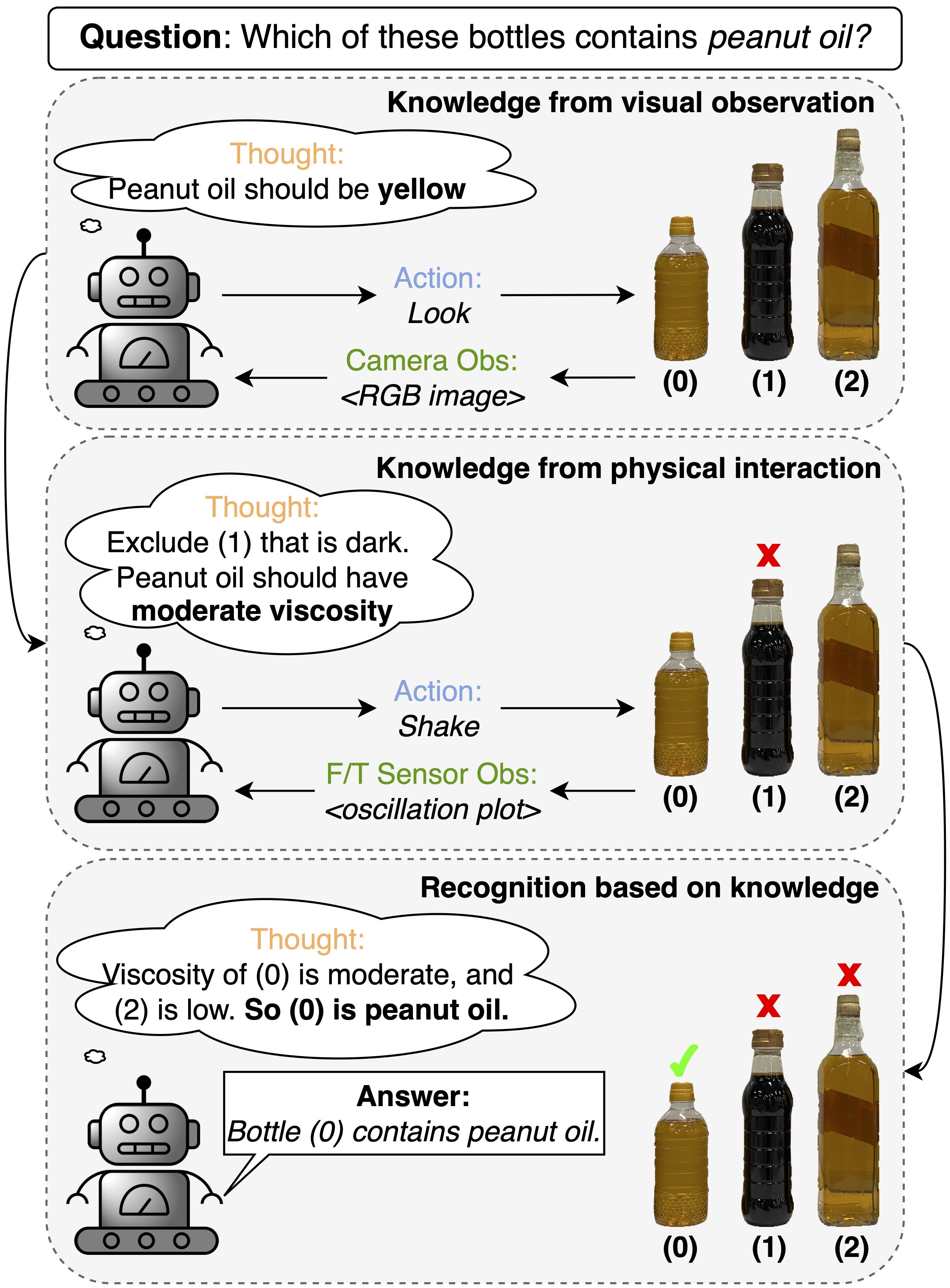
Wenqiang Lai, Yuan Gao, Tin Lun Lam
There is a growing interest in applying large language models (LLMs) in robotic tasks, due to their remarkable reasoning ability and extensive knowledge learned from vast training corpora. Grounding LLMs in the physical world remains an open challenge as they can only process textual input. Recent advancements in large vision-language models (LVLMs) have enabled a more comprehensive understanding of the physical world by incorporating visual input, which provides richer contextual information than language alone. In this work, we proposed a novel paradigm that leveraged GPT-4V(ision), the state-of-the-art LVLM by OpenAI, to enable embodied agents to perceive liquid objects via image-based environmental feedback. Specifically, we exploited the physical understanding of GPT-4V to interpret the visual representation (e.g., time-series plot) of non-visual feedback (e.g., F/T sensor data), indirectly enabling multimodal perception beyond vision and language using images as proxies. We evaluated our method using 10 common household liquids with containers of various geometry and material. Without any training or fine-tuning, we demonstrated that our method can enable the robot to indirectly perceive the physical response of liquids and estimate their viscosity. We also showed that by jointly reasoning over the visual and physical attributes learned through interactions, our method could recognize liquid objects in the absence of strong visual cues (e.g., container labels with legible text or symbols), increasing the accuracy from 69.0% -- achieved by the best-performing vision-only variant -- to 86.0%.
Read more4/11/2024

0
Toward Automatic Relevance Judgment using Vision--Language Models for Image--Text Retrieval Evaluation
Jheng-Hong Yang, Jimmy Lin
Vision--Language Models (VLMs) have demonstrated success across diverse applications, yet their potential to assist in relevance judgments remains uncertain. This paper assesses the relevance estimation capabilities of VLMs, including CLIP, LLaVA, and GPT-4V, within a large-scale textit{ad hoc} retrieval task tailored for multimedia content creation in a zero-shot fashion. Preliminary experiments reveal the following: (1) Both LLaVA and GPT-4V, encompassing open-source and closed-source visual-instruction-tuned Large Language Models (LLMs), achieve notable Kendall's $tau sim 0.4$ when compared to human relevance judgments, surpassing the CLIPScore metric. (2) While CLIPScore is strongly preferred, LLMs are less biased towards CLIP-based retrieval systems. (3) GPT-4V's score distribution aligns more closely with human judgments than other models, achieving a Cohen's $kappa$ value of around 0.08, which outperforms CLIPScore at approximately -0.096. These findings underscore the potential of LLM-powered VLMs in enhancing relevance judgments.
Read more8/6/2024