On the Robustness of Language Models for Tabular Question Answering
2406.12719
0
0
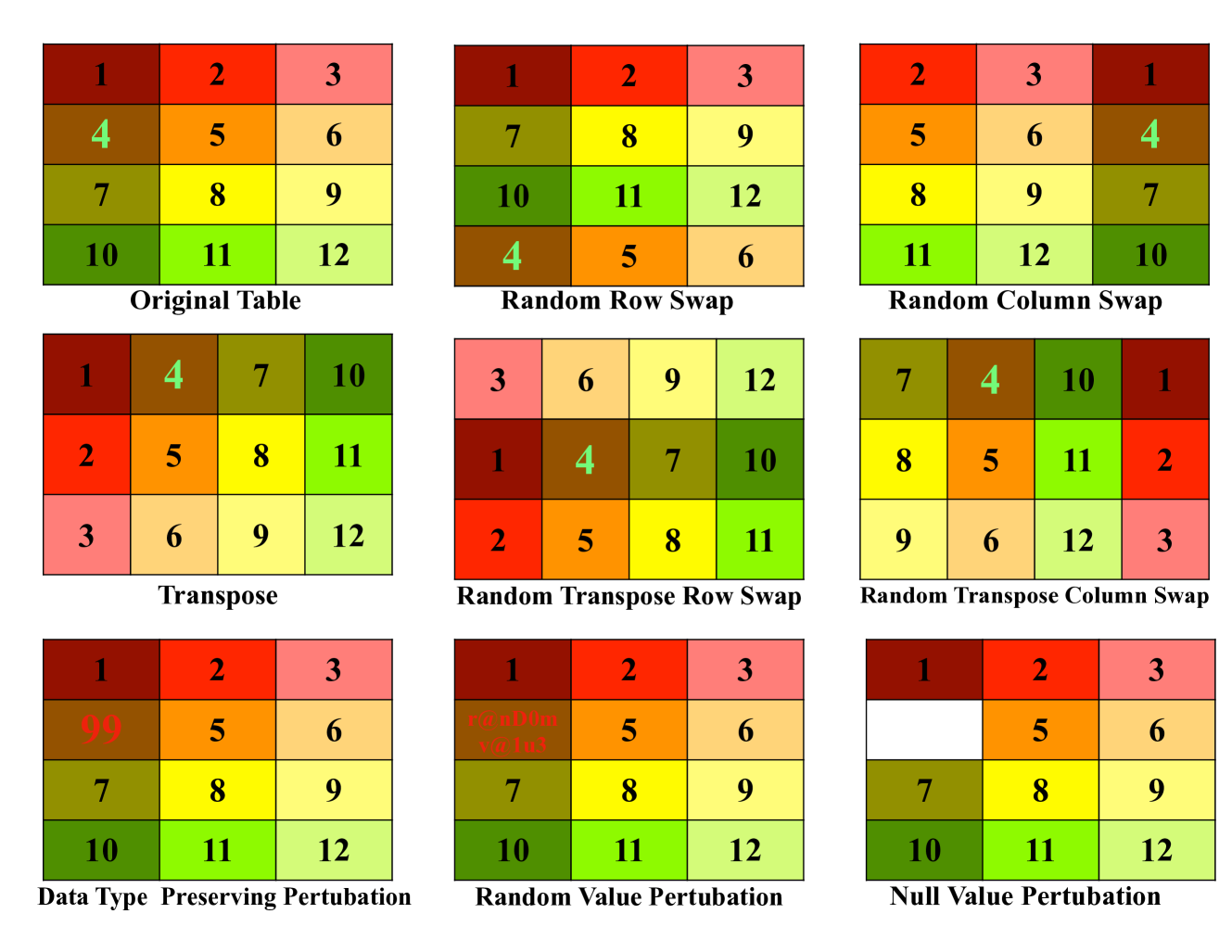
Abstract
Large Language Models (LLMs), originally shown to ace various text comprehension tasks have also remarkably been shown to tackle table comprehension tasks without specific training. While previous research has explored LLM capabilities with tabular dataset tasks, our study assesses the influence of $textit{in-context learning}$,$ textit{model scale}$, $textit{instruction tuning}$, and $textit{domain biases}$ on Tabular Question Answering (TQA). We evaluate the robustness of LLMs on Wikipedia-based $textbf{WTQ}$ and financial report-based $textbf{TAT-QA}$ TQA datasets, focusing on their ability to robustly interpret tabular data under various augmentations and perturbations. Our findings indicate that instructions significantly enhance performance, with recent models like Llama3 exhibiting greater robustness over earlier versions. However, data contamination and practical reliability issues persist, especially with WTQ. We highlight the need for improved methodologies, including structure-aware self-attention mechanisms and better handling of domain-specific tabular data, to develop more reliable LLMs for table comprehension.
Create account to get full access
Overview
- This paper examines the robustness of large language models (LLMs) when used for tabular question answering, a common task in data analysis and business intelligence.
- The researchers investigate how LLMs perform under various types of perturbations to the tabular data, such as changes in column names, data types, or the inclusion of irrelevant columns.
- The goal is to understand the strengths and limitations of LLMs in handling real-world data challenges and to identify areas for improvement.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive capabilities in understanding and generating human language. Recently, researchers have explored using these models for tasks beyond just text, such as answering questions about data in tables.
However, real-world data can be messy and unpredictable, with changes in column names, data types, or the inclusion of irrelevant information. This paper investigates how robust LLMs are to these types of "perturbations" in the tabular data they are asked to reason about. The researchers want to understand the strengths and limitations of LLMs in handling the challenges that can arise when working with real-world data, so that the technology can be improved and deployed more effectively.
Technical Explanation
The researchers consider several categories of perturbations that can be applied to tabular data:
- Column Name Perturbations: Changing the names of the columns in the table, either by replacing them with random strings or by swapping the names between columns.
- Data Type Perturbations: Changing the data type of one or more columns, such as converting a numeric column to text.
- Irrelevant Column Perturbations: Adding extra, irrelevant columns to the table to see how the LLM handles extraneous information.
They evaluate the performance of several state-of-the-art LLMs, including HELM and T2T, on question-answering tasks across these perturbed datasets. The results provide insights into the strengths and weaknesses of the different models in handling real-world data challenges.
Critical Analysis
The paper acknowledges that the perturbations considered, while representative of common data quality issues, may not cover the full spectrum of real-world data challenges. Additional types of perturbations, such as missing values or inconsistent formatting, could be explored in future work.
Furthermore, the researchers note that the performance of the LLMs may be influenced by the specific datasets and tasks used in the evaluation. Expanding the range of datasets and tasks could provide a more comprehensive understanding of the models' robustness.
It would also be valuable to investigate the interpretability and transparency of the LLMs' reasoning process when dealing with perturbed data. Understanding how the models arrive at their predictions could inform efforts to improve their robustness and trustworthiness.
Conclusion
This paper provides valuable insights into the robustness of state-of-the-art large language models when applied to tabular question answering tasks. The researchers have identified several types of data perturbations that can challenge the performance of these models, highlighting areas for further research and development.
As LLMs continue to be applied to a growing range of tabular data tasks, understanding their strengths and limitations in handling real-world data complexities will be crucial for ensuring their effective and trustworthy deployment in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey
Xi Fang, Weijie Xu, Fiona Anting Tan, Jiani Zhang, Ziqing Hu, Yanjun Qi, Scott Nickleach, Diego Socolinsky, Srinivasan Sengamedu, Christos Faloutsos
0
0
Recent breakthroughs in large language modeling have facilitated rigorous exploration of their application in diverse tasks related to tabular data modeling, such as prediction, tabular data synthesis, question answering, and table understanding. Each task presents unique challenges and opportunities. However, there is currently a lack of comprehensive review that summarizes and compares the key techniques, metrics, datasets, models, and optimization approaches in this research domain. This survey aims to address this gap by consolidating recent progress in these areas, offering a thorough survey and taxonomy of the datasets, metrics, and methodologies utilized. It identifies strengths, limitations, unexplored territories, and gaps in the existing literature, while providing some insights for future research directions in this vital and rapidly evolving field. It also provides relevant code and datasets references. Through this comprehensive review, we hope to provide interested readers with pertinent references and insightful perspectives, empowering them with the necessary tools and knowledge to effectively navigate and address the prevailing challenges in the field.
6/26/2024
💬
HeLM: Highlighted Evidence augmented Language Model for Enhanced Table-to-Text Generation
Junyi Bian, Xiaolei Qin, Wuhe Zou, Mengzuo Huang, Congyi Luo, Ke Zhang, Weidong Zhang
0
0
Large models have demonstrated significant progress across various domains, particularly in tasks related to text generation. In the domain of Table to Text, many Large Language Model (LLM)-based methods currently resort to modifying prompts to invoke public APIs, incurring potential costs and information leaks. With the advent of open-source large models, fine-tuning LLMs has become feasible. In this study, we conducted parameter-efficient fine-tuning on the LLaMA2 model. Distinguishing itself from previous fine-tuning-based table-to-text methods, our approach involves injecting reasoning information into the input by emphasizing table-specific row data. Our model consists of two modules: 1) a table reasoner that identifies relevant row evidence, and 2) a table summarizer that generates sentences based on the highlighted table. To facilitate this, we propose a search strategy to construct reasoning labels for training the table reasoner. On both the FetaQA and QTSumm datasets, our approach achieved state-of-the-art results. Additionally, we observed that highlighting input tables significantly enhances the model's performance and provides valuable interpretability.
4/30/2024
💬
Unleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science
Yazheng Yang, Yuqi Wang, Sankalok Sen, Lei Li, Qi Liu
0
0
In the domain of data science, the predictive tasks of classification, regression, and imputation of missing values are commonly encountered challenges associated with tabular data. This research endeavors to apply Large Language Models (LLMs) towards addressing these predictive tasks. Despite their proficiency in comprehending natural language, LLMs fall short in dealing with structured tabular data. This limitation stems from their lacking exposure to the intricacies of tabular data during their foundational training. Our research aims to mitigate this gap by compiling a comprehensive corpus of tables annotated with instructions and executing large-scale training of Llama-2 on this enriched dataset. Furthermore, we investigate the practical application of applying the trained model to zero-shot prediction, few-shot prediction, and in-context learning scenarios. Through extensive experiments, our methodology has shown significant improvements over existing benchmarks. These advancements highlight the efficacy of tailoring LLM training to solve table-related problems in data science, thereby establishing a new benchmark in the utilization of LLMs for enhancing tabular intelligence.
4/9/2024
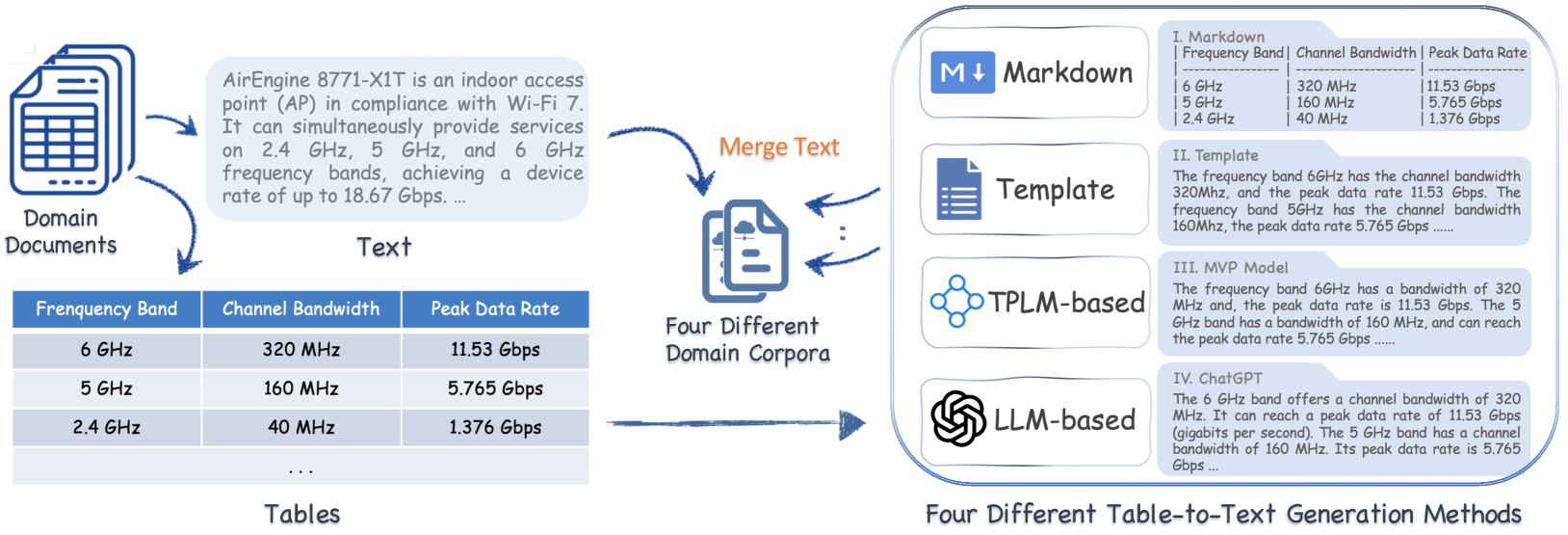
Exploring the Impact of Table-to-Text Methods on Augmenting LLM-based Question Answering with Domain Hybrid Data
Dehai Min, Nan Hu, Rihui Jin, Nuo Lin, Jiaoyan Chen, Yongrui Chen, Yu Li, Guilin Qi, Yun Li, Nijun Li, Qianren Wang
0
0
Augmenting Large Language Models (LLMs) for Question Answering (QA) with domain specific data has attracted wide attention. However, domain data often exists in a hybrid format, including text and semi-structured tables, posing challenges for the seamless integration of information. Table-to-Text Generation is a promising solution by facilitating the transformation of hybrid data into a uniformly text-formatted corpus. Although this technique has been widely studied by the NLP community, there is currently no comparative analysis on how corpora generated by different table-to-text methods affect the performance of QA systems. In this paper, we address this research gap in two steps. First, we innovatively integrate table-to-text generation into the framework of enhancing LLM-based QA systems with domain hybrid data. Then, we utilize this framework in real-world industrial data to conduct extensive experiments on two types of QA systems (DSFT and RAG frameworks) with four representative methods: Markdown format, Template serialization, TPLM-based method, and LLM-based method. Based on the experimental results, we draw some empirical findings and explore the underlying reasons behind the success of some methods. We hope the findings of this work will provide a valuable reference for the academic and industrial communities in developing robust QA systems.
4/10/2024