Exploring the Impact of Table-to-Text Methods on Augmenting LLM-based Question Answering with Domain Hybrid Data
2402.12869
0
0
Abstract
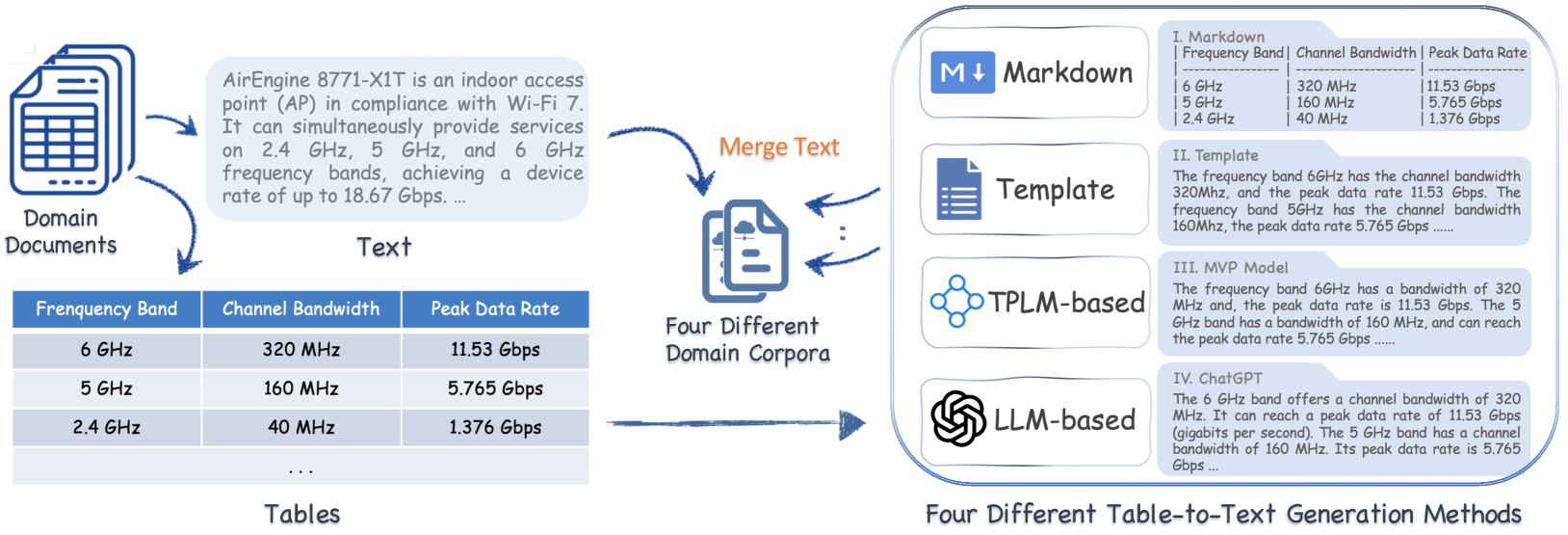
Augmenting Large Language Models (LLMs) for Question Answering (QA) with domain specific data has attracted wide attention. However, domain data often exists in a hybrid format, including text and semi-structured tables, posing challenges for the seamless integration of information. Table-to-Text Generation is a promising solution by facilitating the transformation of hybrid data into a uniformly text-formatted corpus. Although this technique has been widely studied by the NLP community, there is currently no comparative analysis on how corpora generated by different table-to-text methods affect the performance of QA systems. In this paper, we address this research gap in two steps. First, we innovatively integrate table-to-text generation into the framework of enhancing LLM-based QA systems with domain hybrid data. Then, we utilize this framework in real-world industrial data to conduct extensive experiments on two types of QA systems (DSFT and RAG frameworks) with four representative methods: Markdown format, Template serialization, TPLM-based method, and LLM-based method. Based on the experimental results, we draw some empirical findings and explore the underlying reasons behind the success of some methods. We hope the findings of this work will provide a valuable reference for the academic and industrial communities in developing robust QA systems.
Create account to get full access
Overview
- This paper explores the impact of table-to-text generation methods on augmenting large language model (LLM)-based question answering systems with domain-specific data.
- The researchers investigate how integrating table-to-text techniques can enhance the performance of LLM-based question answering models, particularly when working with hybrid datasets that combine structured and unstructured data.
Plain English Explanation
Large language models (LLMs) like GPT-3 have demonstrated impressive capabilities in natural language processing tasks, including question answering. However, these models are often trained on broad, general-purpose data, which can limit their performance on domain-specific tasks.
To address this, the researchers in this paper explore the use of table-to-text generation methods to augment the training data for LLM-based question answering systems. Table-to-text generation is the task of converting structured tabular data into natural language text, which can help bridge the gap between the structured and unstructured data that LLMs are typically trained on.
By incorporating domain-specific tabular data and generating relevant text from it, the researchers aim to enhance the LLM's understanding of the domain and improve its ability to answer questions accurately. This approach can be particularly useful in fields where specialized knowledge is crucial, such as healthcare, finance, or scientific research.
Technical Explanation
The researchers propose a framework that integrates table-to-text generation techniques with LLM-based question answering models. They experiment with different table-to-text generation methods, such as TableLLaMA, to augment the training data for the LLM-based question answering system.
The researchers use a hybrid dataset that combines structured tabular data and unstructured text data from various domains. They evaluate the performance of the LLM-based question answering model both with and without the table-to-text augmented data, and analyze the impact on the model's accuracy, robustness, and generalization capabilities.
The results of the experiments show that the incorporation of table-to-text generation techniques can significantly improve the performance of the LLM-based question answering model, particularly on domain-specific tasks. The researchers provide insights into the optimal table-to-text generation methods and the trade-offs between model complexity, training data size, and overall system performance.
Critical Analysis
The paper presents a well-designed and thorough investigation of the impact of table-to-text generation on LLM-based question answering systems. The researchers acknowledge the limitations of LLMs in handling domain-specific knowledge and effectively leverage table-to-text techniques to address this challenge.
One potential area for further research could be exploring the scalability of this approach, as the performance gains may be influenced by the size and diversity of the hybrid dataset used. Additionally, the researchers could investigate the transferability of the table-to-text generation models across different domains, as this could lead to more efficient and versatile question answering systems.
It would also be interesting to see how this approach compares to other data augmentation techniques, such as unsupervised pretraining on domain-specific corpora or leveraging heterogeneous graph structures, to gain a more comprehensive understanding of the strengths and limitations of table-to-text augmentation.
Conclusion
This paper presents a compelling approach to improving the performance of LLM-based question answering systems by integrating table-to-text generation techniques. The researchers demonstrate that leveraging domain-specific tabular data can significantly enhance the LLM's understanding and ability to answer questions in specialized domains.
The findings of this study have the potential to inform the development of more robust and versatile question answering systems, which could benefit a wide range of applications, from medical diagnosis to financial analysis. As the field of natural language processing continues to evolve, techniques like table-to-text generation may play an increasingly important role in bridging the gap between structured and unstructured data, ultimately leading to more accurate and reliable AI-powered question answering systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
On the Robustness of Language Models for Tabular Question Answering
Kushal Raj Bhandari, Sixue Xing, Soham Dan, Jianxi Gao
0
0
Large Language Models (LLMs), originally shown to ace various text comprehension tasks have also remarkably been shown to tackle table comprehension tasks without specific training. While previous research has explored LLM capabilities with tabular dataset tasks, our study assesses the influence of $textit{in-context learning}$,$ textit{model scale}$, $textit{instruction tuning}$, and $textit{domain biases}$ on Tabular Question Answering (TQA). We evaluate the robustness of LLMs on Wikipedia-based $textbf{WTQ}$ and financial report-based $textbf{TAT-QA}$ TQA datasets, focusing on their ability to robustly interpret tabular data under various augmentations and perturbations. Our findings indicate that instructions significantly enhance performance, with recent models like Llama3 exhibiting greater robustness over earlier versions. However, data contamination and practical reliability issues persist, especially with WTQ. We highlight the need for improved methodologies, including structure-aware self-attention mechanisms and better handling of domain-specific tabular data, to develop more reliable LLMs for table comprehension.
6/19/2024
💬
HeLM: Highlighted Evidence augmented Language Model for Enhanced Table-to-Text Generation
Junyi Bian, Xiaolei Qin, Wuhe Zou, Mengzuo Huang, Congyi Luo, Ke Zhang, Weidong Zhang
0
0
Large models have demonstrated significant progress across various domains, particularly in tasks related to text generation. In the domain of Table to Text, many Large Language Model (LLM)-based methods currently resort to modifying prompts to invoke public APIs, incurring potential costs and information leaks. With the advent of open-source large models, fine-tuning LLMs has become feasible. In this study, we conducted parameter-efficient fine-tuning on the LLaMA2 model. Distinguishing itself from previous fine-tuning-based table-to-text methods, our approach involves injecting reasoning information into the input by emphasizing table-specific row data. Our model consists of two modules: 1) a table reasoner that identifies relevant row evidence, and 2) a table summarizer that generates sentences based on the highlighted table. To facilitate this, we propose a search strategy to construct reasoning labels for training the table reasoner. On both the FetaQA and QTSumm datasets, our approach achieved state-of-the-art results. Additionally, we observed that highlighting input tables significantly enhances the model's performance and provides valuable interpretability.
4/30/2024
Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL
Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, Xiao Huang
0
0
Generating accurate SQL according to natural language questions (text-to-SQL) is a long-standing challenge due to the complexities involved in user question understanding, database schema comprehension, and SQL generation. Conventional text-to-SQL systems, comprising human engineering and deep neural networks, have made substantial progress. Subsequently, pre-trained language models (PLMs) have been developed and utilized for text-to-SQL tasks, achieving promising performance. As modern databases become more complex, the corresponding user questions also grow more challenging, leading PLMs with limited comprehension capabilities to produce incorrect SQL. This necessitates more sophisticated and tailored optimization methods for PLMs, which, in turn, restricts the applications of PLM-based systems. Most recently, large language models (LLMs) have demonstrated significant capabilities in natural language understanding as the model scale remains increasing. Therefore, integrating the LLM-based implementation can bring unique opportunities, improvements, and solutions to text-to-SQL research. In this survey, we present a comprehensive review of LLM-based text-to-SQL. Specifically, we propose a brief overview of the technical challenges and the evolutionary process of text-to-SQL. Then, we provide a detailed introduction to the datasets and metrics designed to evaluate text-to-SQL systems. After that, we present a systematic analysis of recent advances in LLM-based text-to-SQL. Finally, we discuss the remaining challenges in this field and propose expectations for future research directions.
6/28/2024

TTQA-RS- A break-down prompting approach for Multi-hop Table-Text Question Answering with Reasoning and Summarization
Jayetri Bardhan, Bushi Xiao, Daisy Zhe Wang
0
0
Question answering (QA) over tables and text has gained much popularity over the years. Multi-hop table-text QA requires multiple hops between the table and text, making it a challenging QA task. Although several works have attempted to solve the table-text QA task, most involve training the models and requiring labeled data. In this paper, we have proposed a model - TTQA-RS: A break-down prompting approach for Multi-hop Table-Text Question Answering with Reasoning and Summarization. Our model uses augmented knowledge including table-text summary with decomposed sub-question with answer for a reasoning-based table-text QA. Using open-source language models our model outperformed all existing prompting methods for table-text QA tasks on existing table-text QA datasets like HybridQA and OTT-QA's development set. Our results are comparable with the training-based state-of-the-art models, demonstrating the potential of prompt-based approaches using open-source LLMs. Additionally, by using GPT-4 with LLaMA3-70B, our model achieved state-of-the-art performance for prompting-based methods on multi-hop table-text QA.
6/24/2024