RoDE: Linear Rectified Mixture of Diverse Experts for Food Large Multi-Modal Models

0

Sign in to get full access
Overview
• The paper proposes a novel model called RoDE (Linear Rectified Mixture of Diverse Experts) for large multi-modal food models. • RoDE introduces a mixture-of-experts architecture that combines specialized sub-models, or "experts," to improve performance on diverse food-related tasks. • The researchers construct a large multi-modal food dataset to train and evaluate their model, addressing limitations in existing datasets.
Plain English Explanation
The researchers have developed a new model called RoDE that aims to improve performance on a wide range of food-related tasks, such as food image classification and fine-grained food understanding.
RoDE uses a "mixture-of-experts" approach, which means it combines multiple specialized sub-models, each focused on a particular aspect of food-related tasks. This allows the overall model to draw on the unique strengths of each expert, resulting in better performance compared to a single, generalized model.
To train and evaluate their RoDE model, the researchers also constructed a new large-scale multi-modal food dataset. This dataset addresses limitations in existing food datasets, such as FoodLMM and FoodieQA, by providing a more diverse and comprehensive set of food-related data.
Technical Explanation
The key innovation of the RoDE model is its mixture-of-experts architecture, which combines multiple specialized sub-models to improve performance on diverse food-related tasks. Each "expert" in the mixture is trained on a specific aspect of food data, such as food image recognition or recipe understanding. The outputs of these experts are then linearly combined and rectified to produce the final output.
To train and evaluate RoDE, the researchers constructed a large multi-modal food dataset that includes a wide variety of food-related data, such as images, recipes, and nutritional information. This dataset addresses limitations in existing food datasets, which tend to be more focused on specific tasks or cultures.
The researchers conducted extensive experiments to validate the effectiveness of their RoDE model, comparing its performance to state-of-the-art food models on a range of benchmark tasks. Their results demonstrate that the mixture-of-experts approach of RoDE can outperform single-model baselines, particularly on more challenging or diverse food-related tasks.
Critical Analysis
The paper provides a thorough and well-designed study of the RoDE model and the accompanying multi-modal food dataset. The mixture-of-experts approach is a promising direction for improving the performance of large, multi-modal food models, as it allows the model to leverage the unique strengths of specialized sub-models.
However, the paper does not fully address the potential limitations of the RoDE architecture, such as the complexity of training and managing multiple experts, or the potential for overfitting on specific task domains. Additionally, the researchers could have explored the transferability of the RoDE model to other food-related tasks or datasets, which would help demonstrate the broader applicability of their approach.
Conclusion
The RoDE model and the accompanying multi-modal food dataset represent a significant contribution to the field of food-related AI and computer vision. By introducing a novel mixture-of-experts architecture and a comprehensive food dataset, the researchers have taken important steps towards developing more versatile and high-performing food models that can support a wide range of applications, from recipe recommendation to fine-grained food understanding. As the field of food-related AI continues to advance, the insights and resources provided by this work will likely prove valuable for researchers and developers working to push the boundaries of what's possible in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RoDE: Linear Rectified Mixture of Diverse Experts for Food Large Multi-Modal Models
Pengkun Jiao, Xinlan Wu, Bin Zhu, Jingjing Chen, Chong-Wah Ngo, Yugang Jiang
Large Multi-modal Models (LMMs) have significantly advanced a variety of vision-language tasks. The scalability and availability of high-quality training data play a pivotal role in the success of LMMs. In the realm of food, while comprehensive food datasets such as Recipe1M offer an abundance of ingredient and recipe information, they often fall short of providing ample data for nutritional analysis. The Recipe1M+ dataset, despite offering a subset for nutritional evaluation, is limited in the scale and accuracy of nutrition information. To bridge this gap, we introduce Uni-Food, a unified food dataset that comprises over 100,000 images with various food labels, including categories, ingredients, recipes, and ingredient-level nutritional information. Uni-Food is designed to provide a more holistic approach to food data analysis, thereby enhancing the performance and capabilities of LMMs in this domain. To mitigate the conflicts arising from multi-task supervision during fine-tuning of LMMs, we introduce a novel Linear Rectification Mixture of Diverse Experts (RoDE) approach. RoDE utilizes a diverse array of experts to address tasks of varying complexity, thereby facilitating the coordination of trainable parameters, i.e., it allocates more parameters for more complex tasks and, conversely, fewer parameters for simpler tasks. RoDE implements linear rectification union to refine the router's functionality, thereby enhancing the efficiency of sparse task allocation. These design choices endow RoDE with features that ensure GPU memory efficiency and ease of optimization. Our experimental results validate the effectiveness of our proposed approach in addressing the inherent challenges of food-related multitasking.
Read more7/18/2024

0
FoodLMM: A Versatile Food Assistant using Large Multi-modal Model
Yuehao Yin, Huiyan Qi, Bin Zhu, Jingjing Chen, Yu-Gang Jiang, Chong-Wah Ngo
Large Multi-modal Models (LMMs) have made impressive progress in many vision-language tasks. Nevertheless, the performance of general LMMs in specific domains is still far from satisfactory. This paper proposes FoodLMM, a versatile food assistant based on LMMs with various capabilities, including food recognition, ingredient recognition, recipe generation, nutrition estimation, food segmentation and multi-round conversation. To facilitate FoodLMM to deal with tasks beyond pure text output, we introduce a series of novel task-specific tokens and heads, enabling the model to predict food nutritional values and multiple segmentation masks. We adopt a two-stage training strategy. In the first stage, we utilize multiple public food benchmarks for multi-task learning by leveraging the instruct-following paradigm. In the second stage, we construct a multi-round conversation dataset and a reasoning segmentation dataset to fine-tune the model, enabling it to conduct professional dialogues and generate segmentation masks based on complex reasoning in the food domain. Our fine-tuned FoodLMM achieves state-of-the-art results across several food benchmarks. We will make our code, models and datasets publicly available.
Read more4/15/2024
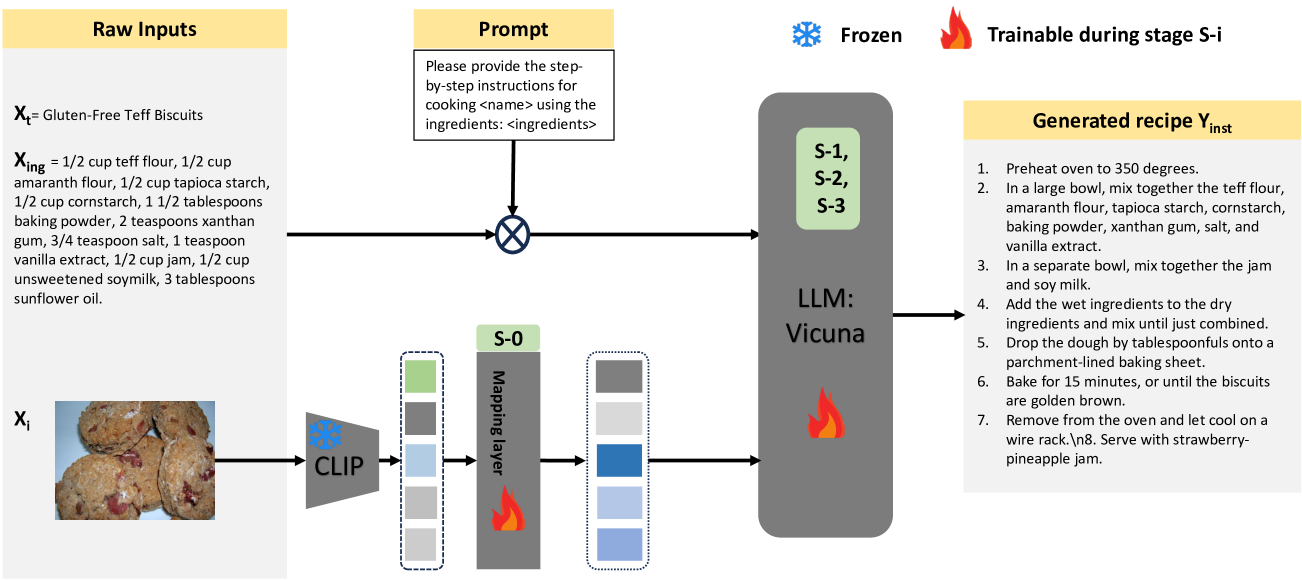
0
LLaVA-Chef: A Multi-modal Generative Model for Food Recipes
Fnu Mohbat, Mohammed J. Zaki
In the rapidly evolving landscape of online recipe sharing within a globalized context, there has been a notable surge in research towards comprehending and generating food recipes. Recent advancements in large language models (LLMs) like GPT-2 and LLaVA have paved the way for Natural Language Processing (NLP) approaches to delve deeper into various facets of food-related tasks, encompassing ingredient recognition and comprehensive recipe generation. Despite impressive performance and multi-modal adaptability of LLMs, domain-specific training remains paramount for their effective application. This work evaluates existing LLMs for recipe generation and proposes LLaVA-Chef, a novel model trained on a curated dataset of diverse recipe prompts in a multi-stage approach. First, we refine the mapping of visual food image embeddings to the language space. Second, we adapt LLaVA to the food domain by fine-tuning it on relevant recipe data. Third, we utilize diverse prompts to enhance the model's recipe comprehension. Finally, we improve the linguistic quality of generated recipes by penalizing the model with a custom loss function. LLaVA-Chef demonstrates impressive improvements over pretrained LLMs and prior works. A detailed qualitative analysis reveals that LLaVA-Chef generates more detailed recipes with precise ingredient mentions, compared to existing approaches.
Read more9/2/2024

0
FoodieQA: A Multimodal Dataset for Fine-Grained Understanding of Chinese Food Culture
Wenyan Li, Xinyu Zhang, Jiaang Li, Qiwei Peng, Raphael Tang, Li Zhou, Weijia Zhang, Guimin Hu, Yifei Yuan, Anders S{o}gaard, Daniel Hershcovich, Desmond Elliott
Food is a rich and varied dimension of cultural heritage, crucial to both individuals and social groups. To bridge the gap in the literature on the often-overlooked regional diversity in this domain, we introduce FoodieQA, a manually curated, fine-grained image-text dataset capturing the intricate features of food cultures across various regions in China. We evaluate vision-language Models (VLMs) and large language models (LLMs) on newly collected, unseen food images and corresponding questions. FoodieQA comprises three multiple-choice question-answering tasks where models need to answer questions based on multiple images, a single image, and text-only descriptions, respectively. While LLMs excel at text-based question answering, surpassing human accuracy, the open-sourced VLMs still fall short by 41% on multi-image and 21% on single-image VQA tasks, although closed-weights models perform closer to human levels (within 10%). Our findings highlight that understanding food and its cultural implications remains a challenging and under-explored direction.
Read more6/18/2024