Role of Dependency Distance in Text Simplification: A Human vs ChatGPT Simplification Comparison

0
⚙️
Sign in to get full access
Overview
- This study investigates the relationship between text simplification and dependency distance, which measures the complexity of sentence structure.
- The researchers simplified a set of 220 sentences using both a human expert and the language model ChatGPT, and compared the resulting dependency distances.
- They found that the original sentences had the highest mean dependency distance, followed by the ChatGPT simplified sentences, and the human simplified sentences had the lowest mean dependency distance.
Plain English Explanation
The researchers in this study looked at how the complexity of sentence structure changes when sentences are simplified by a human expert or by the AI language model ChatGPT. They used a measure called "dependency distance" to quantify the complexity of the sentence structure.
The researchers started with a set of 220 sentences that were previously found to have increasing levels of grammatical difficulty. They then had a human expert simplify these sentences, and they also used ChatGPT to simplify the same sentences.
When the researchers compared the dependency distances of the original sentences, the ChatGPT simplified sentences, and the human simplified sentences, they found some interesting differences. The original sentences had the highest average dependency distance, meaning they had the most complex sentence structures. The ChatGPT simplified sentences had a lower average dependency distance, indicating that ChatGPT was able to simplify the sentences to some extent. However, the human simplified sentences had the lowest average dependency distance, suggesting that the human expert was able to simplify the sentences even further than ChatGPT.
This research provides insight into how well different approaches, such as human experts and language models, can simplify complex text. It could have implications for text simplification tasks and understanding the capabilities of language models compared to human experts.
Technical Explanation
The researchers in this study used a set of 220 sentences that had been previously rated for grammatical difficulty by human participants. They then had a human expert simplify these sentences, and they also used the language model ChatGPT to simplify the same sentences.
To measure the complexity of the sentence structure, the researchers calculated the "dependency distance" for each sentence. Dependency distance is a metric that quantifies the distance between words in a sentence that are grammatically dependent on each other. Higher dependency distances indicate more complex sentence structures.
The researchers compared the mean dependency distances of the original sentences, the ChatGPT simplified sentences, and the human simplified sentences. They found that the original sentences had the highest mean dependency distance, followed by the ChatGPT simplified sentences, and the human simplified sentences had the lowest mean dependency distance.
These results suggest that both the human expert and ChatGPT were able to simplify the sentence structures, but the human was more effective at reducing the overall complexity as measured by dependency distance. This aligns with previous research showing that human-generated text can be more grammatically accurate and linguistically complex than text generated by language models.
Critical Analysis
The researchers acknowledge that their study has some limitations. For example, they only used a single set of 220 sentences, and the results may not generalize to other types of text. Additionally, they did not assess the semantic or pragmatic quality of the simplified sentences, only the structural complexity.
Further research could explore how other factors, such as the specific simplification strategies used by humans and language models, influence the resulting text complexity. It would also be valuable to investigate the relationship between dependency distance and other measures of text comprehension or readability.
Overall, this study provides an interesting comparison of human and machine text simplification, but more research is needed to fully understand the tradeoffs and capabilities of each approach. Readers should think critically about the limitations of the research and consider how it fits into the broader landscape of text simplification and language model evaluation.
Conclusion
This study investigated the relationship between text simplification and dependency distance, a measure of sentence structure complexity. The researchers found that human experts were more effective than the language model ChatGPT at reducing the dependency distance of sentences, suggesting that humans are better able to simplify complex text structures.
These findings have implications for text simplification tasks and our understanding of the capabilities of language models compared to human experts. Further research is needed to explore the broader implications and applications of this work, as well as its limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Role of Dependency Distance in Text Simplification: A Human vs ChatGPT Simplification Comparison
Sumi Lee, Gondy Leroy, David Kauchak, Melissa Just
This study investigates human and ChatGPT text simplification and its relationship to dependency distance. A set of 220 sentences, with increasing grammatical difficulty as measured in a prior user study, were simplified by a human expert and using ChatGPT. We found that the three sentence sets all differed in mean dependency distances: the highest in the original sentence set, followed by ChatGPT simplified sentences, and the human simplified sentences showed the lowest mean dependency distance.
Read more6/27/2024
👨🏫
0
Text and Audio Simplification: Human vs. ChatGPT
Gondy Leroy, David Kauchak, Philip Harber, Ankit Pal, Akash Shukla
Text and audio simplification to increase information comprehension are important in healthcare. With the introduction of ChatGPT, an evaluation of its simplification performance is needed. We provide a systematic comparison of human and ChatGPT simplified texts using fourteen metrics indicative of text difficulty. We briefly introduce our online editor where these simplification tools, including ChatGPT, are available. We scored twelve corpora using our metrics: six text, one audio, and five ChatGPT simplified corpora. We then compare these corpora with texts simplified and verified in a prior user study. Finally, a medical domain expert evaluated these texts and five, new ChatGPT simplified versions. We found that simple corpora show higher similarity with the human simplified texts. ChatGPT simplification moves metrics in the right direction. The medical domain expert evaluation showed a preference for the ChatGPT style, but the text itself was rated lower for content retention.
Read more5/6/2024
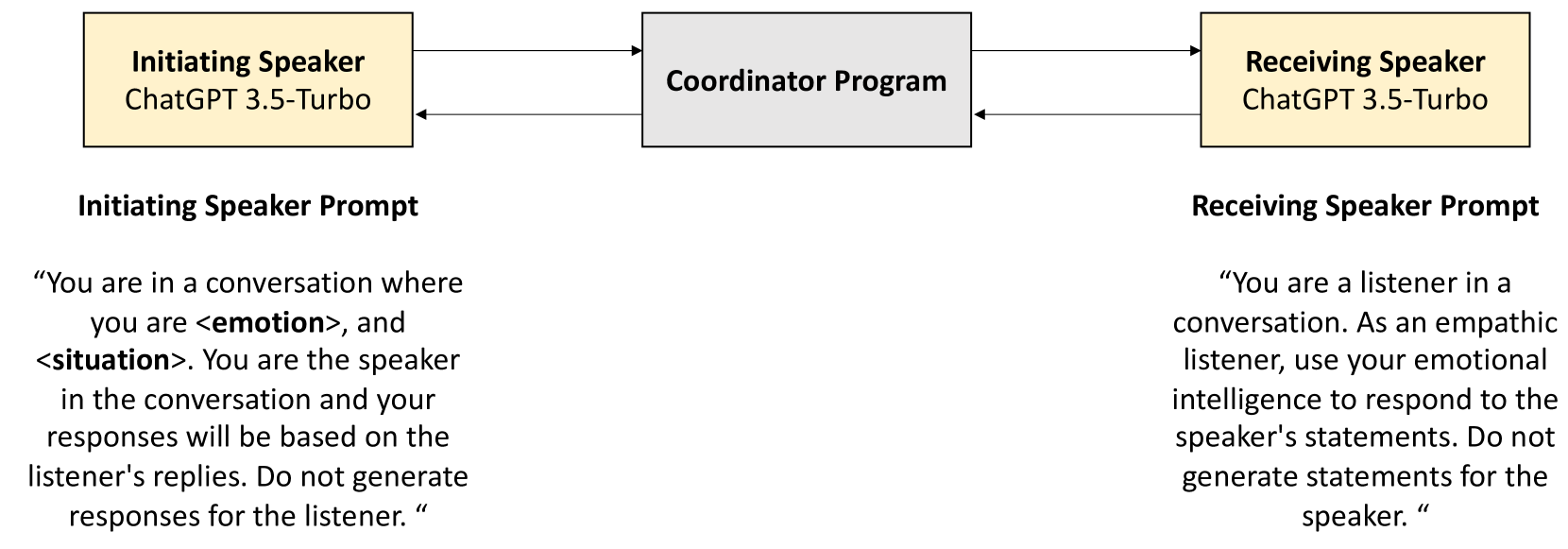
0
A Linguistic Comparison between Human and ChatGPT-Generated Conversations
Morgan Sandler, Hyesun Choung, Arun Ross, Prabu David
This study explores linguistic differences between human and LLM-generated dialogues, using 19.5K dialogues generated by ChatGPT-3.5 as a companion to the EmpathicDialogues dataset. The research employs Linguistic Inquiry and Word Count (LIWC) analysis, comparing ChatGPT-generated conversations with human conversations across 118 linguistic categories. Results show greater variability and authenticity in human dialogues, but ChatGPT excels in categories such as social processes, analytical style, cognition, attentional focus, and positive emotional tone, reinforcing recent findings of LLMs being more human than human. However, no significant difference was found in positive or negative affect between ChatGPT and human dialogues. Classifier analysis of dialogue embeddings indicates implicit coding of the valence of affect despite no explicit mention of affect in the conversations. The research also contributes a novel, companion ChatGPT-generated dataset of conversations between two independent chatbots, which were designed to replicate a corpus of human conversations available for open access and used widely in AI research on language modeling. Our findings enhance understanding of ChatGPT's linguistic capabilities and inform ongoing efforts to distinguish between human and LLM-generated text, which is critical in detecting AI-generated fakes, misinformation, and disinformation.
Read more4/29/2024
📊
0
Distance Sampling-based Paraphraser Leveraging ChatGPT for Text Data Manipulation
Yoori Oh, Yoseob Han, Kyogu Lee
There has been growing interest in audio-language retrieval research, where the objective is to establish the correlation between audio and text modalities. However, most audio-text paired datasets often lack rich expression of the text data compared to the audio samples. One of the significant challenges facing audio-text datasets is the presence of similar or identical captions despite different audio samples. Therefore, under many-to-one mapping conditions, audio-text datasets lead to poor performance of retrieval tasks. In this paper, we propose a novel approach to tackle the data imbalance problem in audio-language retrieval task. To overcome the limitation, we introduce a method that employs a distance sampling-based paraphraser leveraging ChatGPT, utilizing distance function to generate a controllable distribution of manipulated text data. For a set of sentences with the same context, the distance is used to calculate a degree of manipulation for any two sentences, and ChatGPT's few-shot prompting is performed using a text cluster with a similar distance defined by the Jaccard similarity. Therefore, ChatGPT, when applied to few-shot prompting with text clusters, can adjust the diversity of the manipulated text based on the distance. The proposed approach is shown to significantly enhance performance in audio-text retrieval, outperforming conventional text augmentation techniques.
Read more5/2/2024