RORA: Robust Free-Text Rationale Evaluation

0
Sign in to get full access
Overview
- The paper introduces a new approach called Rora for evaluating the robustness of free-text rationales provided by AI systems.
- Rora aims to assess the persuasiveness and faithfulness of the rationales generated by AI models for their predictions.
- The paper presents a human evaluation study to validate the Rora framework and demonstrate its effectiveness.
Plain English Explanation
The paper focuses on evaluating the explanations, or "rationales," that AI systems provide for their decisions. When an AI model makes a prediction, it's important that the model can also explain its reasoning in a way that is persuasive and faithful to the user.
The researchers developed a new approach called Rora to assess the robustness of these free-text rationales. Rora aims to measure how convincing the rationales are and how well they align with the model's actual decision-making process. This is important because AI systems should be able to justify their choices in a way that humans can understand and trust.
To validate the Rora framework, the researchers conducted a human evaluation study. They had people review the rationales generated by AI models and rate how persuasive and faithful the explanations were. This allowed the researchers to assess the effectiveness of the Rora approach and identify areas where the AI models could improve their rationale generation.
Technical Explanation
The paper introduces a new evaluation framework called Rora (Robust Free-Text Rationale Evaluation) for assessing the persuasiveness and faithfulness of free-text rationales generated by AI models. Rora builds on the concept of conditional V-information, which measures the mutual information between the model's predictions and its rationales.
The key innovation of Rora is that it goes beyond simply measuring this mutual information. Rora also evaluates the robustness of the rationales to perturbations, such as by generating alternative rationales or modifying the input text. This allows Rora to assess whether the rationales are truly faithful to the model's decision-making process, rather than just superficially correlated with the predictions.
To validate the Rora framework, the researchers conducted a human evaluation study. They collected rationales generated by AI models on various tasks and had human raters assess the persuasiveness and faithfulness of the explanations. The results demonstrated that Rora was able to effectively distinguish between robust and non-robust rationales, providing a useful tool for improving the transparency and trustworthiness of AI systems.
Critical Analysis
The Rora framework represents an important advance in the evaluation of free-text rationales generated by AI models. By going beyond simple mutual information metrics and assessing the robustness of the rationales, Rora provides a more comprehensive and nuanced way to assess the quality and faithfulness of the explanations.
One potential limitation of the study is that the human evaluation was conducted on a relatively small scale, with only a few raters assessing each rationale. Expanding the scope of the human evaluation, perhaps by crowdsourcing assessments, could provide more robust and generalizable insights.
Additionally, the paper does not explore the potential biases and limitations that may be present in the rationales generated by the AI models themselves. Further research could investigate how these biases might impact the effectiveness of the Rora framework.
Overall, the Rora approach represents an important step forward in the ongoing effort to improve the transparency and trustworthiness of AI systems. By providing a more robust and reliable way to evaluate the explanations generated by these models, the Rora framework can help drive the development of more accountable and trustworthy AI technologies.
Conclusion
The paper introduces a novel evaluation framework called Rora that assesses the robustness and faithfulness of free-text rationales generated by AI models. Rora goes beyond simply measuring the mutual information between predictions and rationales, and instead evaluates the rationales' resilience to perturbations.
The researchers conducted a human evaluation study to validate the Rora approach, demonstrating its effectiveness in distinguishing between robust and non-robust rationales. This work represents an important step towards improving the transparency and trustworthiness of AI systems, as the ability to provide faithful and persuasive explanations is critical for building user trust and acceptance.
By continuing to develop and refine evaluation frameworks like Rora, researchers can drive progress in the field of explainable AI, ensuring that these powerful technologies are aligned with human values and can be effectively deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RORA: Robust Free-Text Rationale Evaluation
Zhengping Jiang, Yining Lu, Hanjie Chen, Daniel Khashabi, Benjamin Van Durme, Anqi Liu
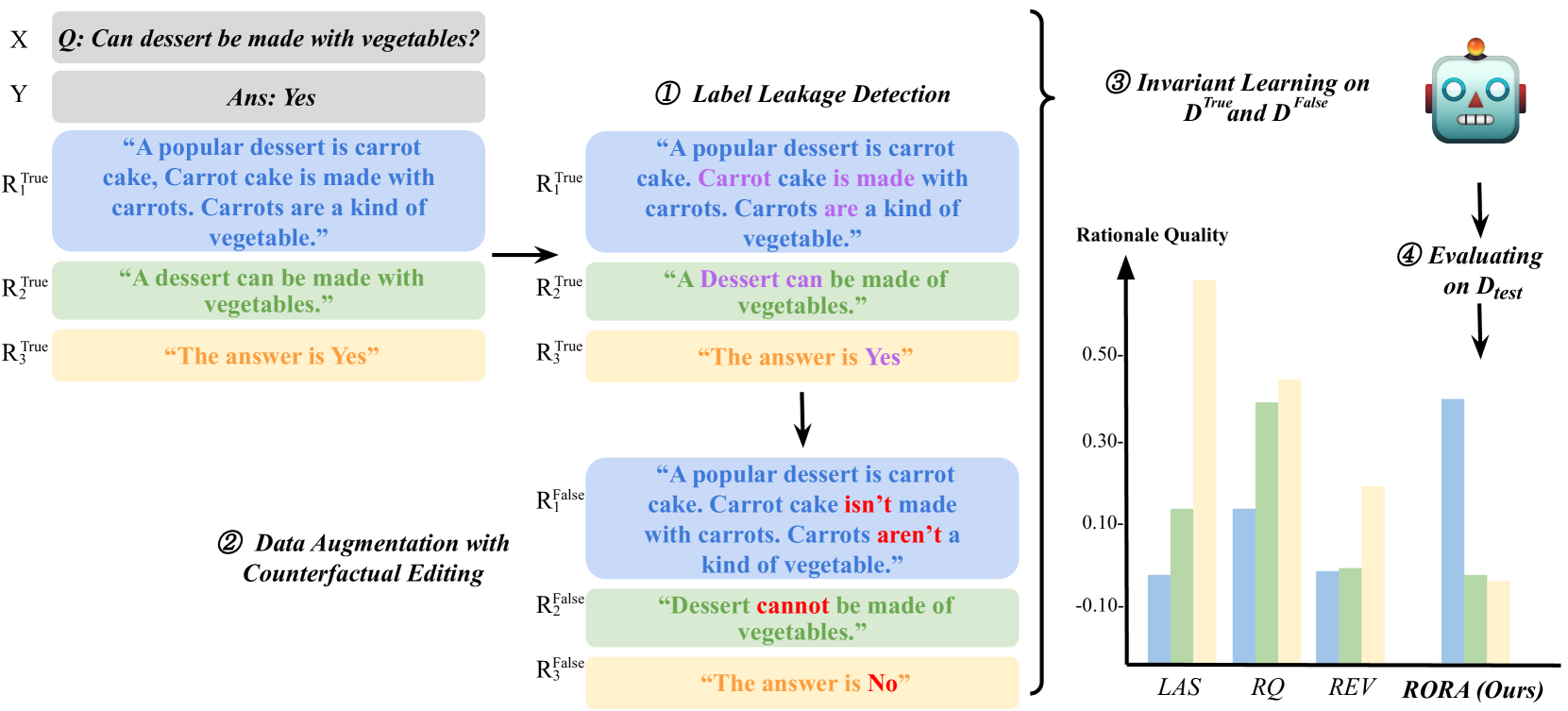
Free-text rationales play a pivotal role in explainable NLP, bridging the knowledge and reasoning gaps behind a model's decision-making. However, due to the diversity of potential reasoning paths and a corresponding lack of definitive ground truth, their evaluation remains a challenge. Existing evaluation metrics rely on the degree to which a rationale supports a target label, but we find these fall short in evaluating rationales that inadvertently leak the labels. To address this problem, we propose RORA, a Robust free-text Rationale evaluation against label leakage. RORA quantifies the new information supplied by a rationale to justify the label. This is achieved by assessing the conditional V-information citep{hewitt-etal-2021-conditional} with a predictive family robust against leaky features that can be exploited by a small model. RORA consistently outperforms existing approaches in evaluating human-written, synthetic, or model-generated rationales, particularly demonstrating robustness against label leakage. We also show that RORA aligns well with human judgment, providing a more reliable and accurate measurement across diverse free-text rationales.
Read more6/18/2024
0
Persuasiveness of Generated Free-Text Rationales in Subjective Decisions: A Case Study on Pairwise Argument Ranking
Mohamed Elaraby, Diane Litman, Xiang Lorraine Li, Ahmed Magooda
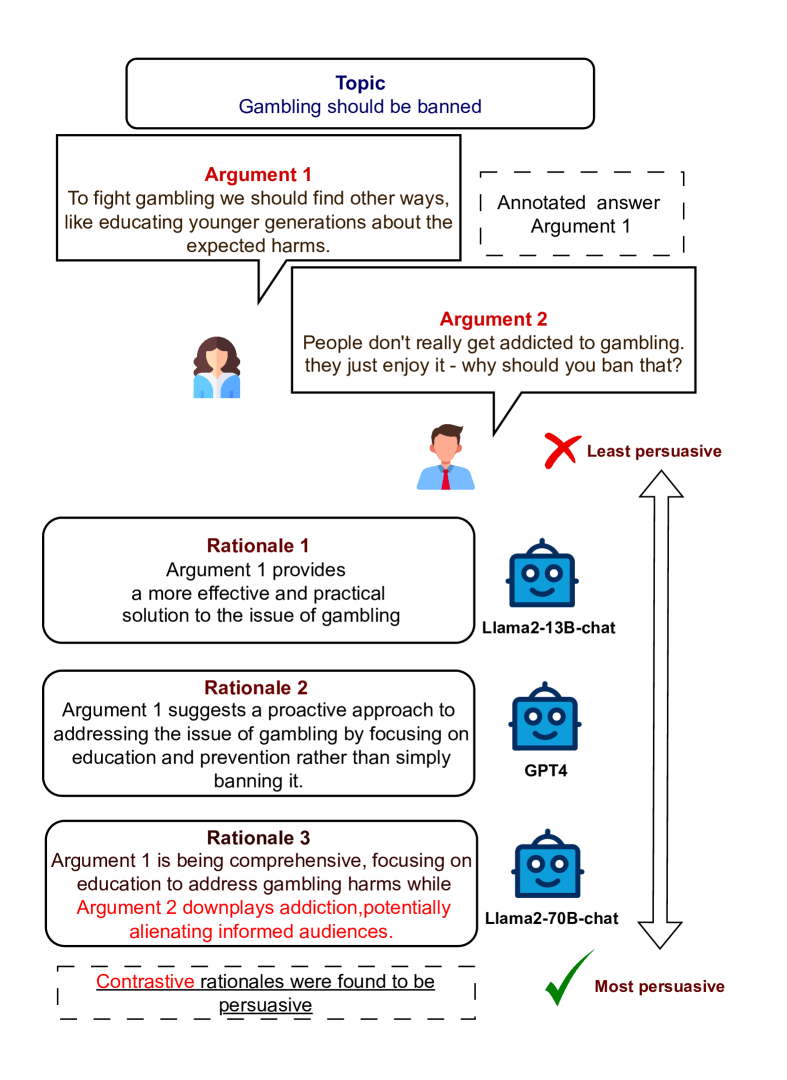
Generating free-text rationales is among the emergent capabilities of Large Language Models (LLMs). These rationales have been found to enhance LLM performance across various NLP tasks. Recently, there has been growing interest in using these rationales to provide insights for various important downstream tasks. In this paper, we analyze generated free-text rationales in tasks with subjective answers, emphasizing the importance of rationalization in such scenarios. We focus on pairwise argument ranking, a highly subjective task with significant potential for real-world applications, such as debate assistance. We evaluate the persuasiveness of rationales generated by nine LLMs to support their subjective choices. Our findings suggest that open-source LLMs, particularly Llama2-70B-chat, are capable of providing highly persuasive rationalizations, surpassing even GPT models. Additionally, our experiments show that rationale persuasiveness can be improved by controlling its parameters through prompting or through self-refinement.
Read more6/21/2024

0
Free-text Rationale Generation under Readability Level Control
Yi-Sheng Hsu, Nils Feldhus, Sherzod Hakimov
Free-text rationales justify model decisions in natural language and thus become likable and accessible among approaches to explanation across many tasks. However, their effectiveness can be hindered by misinterpretation and hallucination. As a perturbation test, we investigate how large language models (LLMs) perform the task of natural language explanation (NLE) under the effects of readability level control, i.e., being prompted for a rationale targeting a specific expertise level, such as sixth grade or college. We find that explanations are adaptable to such instruction, but the requested readability is often misaligned with the measured text complexity according to traditional readability metrics. Furthermore, the quality assessment shows that LLMs' ratings of rationales across text complexity exhibit a similar pattern of preference as observed in natural language generation (NLG). Finally, our human evaluation suggests a generally satisfactory impression on rationales at all readability levels, with high-school-level readability being most commonly perceived and favored.
Read more7/2/2024

0
Evaluating Human Alignment and Model Faithfulness of LLM Rationale
Mohsen Fayyaz, Fan Yin, Jiao Sun, Nanyun Peng
We study how well large language models (LLMs) explain their generations with rationales -- a set of tokens extracted from the input texts that reflect the decision process of LLMs. We examine LLM rationales extracted with two methods: 1) attribution-based methods that use attention or gradients to locate important tokens, and 2) prompting-based methods that guide LLMs to extract rationales using prompts. Through extensive experiments, we show that prompting-based rationales align better with human-annotated rationales than attribution-based rationales, and demonstrate reasonable alignment with humans even when model performance is poor. We additionally find that the faithfulness limitations of prompting-based methods, which are identified in previous work, may be linked to their collapsed predictions. By fine-tuning these models on the corresponding datasets, both prompting and attribution methods demonstrate improved faithfulness. Our study sheds light on more rigorous and fair evaluations of LLM rationales, especially for prompting-based ones.
Read more7/2/2024