Tailoring Self-Rationalizers with Multi-Reward Distillation
2311.02805
0
0
🏋️
Abstract
Large language models (LMs) are capable of generating free-text rationales to aid question answering. However, prior work 1) suggests that useful self-rationalization is emergent only at significant scales (e.g., 175B parameter GPT-3); and 2) focuses largely on downstream performance, ignoring the semantics of the rationales themselves, e.g., are they faithful, true, and helpful for humans? In this work, we enable small-scale LMs (approx. 200x smaller than GPT-3) to generate rationales that not only improve downstream task performance, but are also more plausible, consistent, and diverse, assessed both by automatic and human evaluation. Our method, MaRio (Multi-rewArd RatIOnalization), is a multi-reward conditioned self-rationalization algorithm that optimizes multiple distinct properties like plausibility, diversity and consistency. Results on five difficult question-answering datasets StrategyQA, QuaRel, OpenBookQA, NumerSense and QASC show that not only does MaRio improve task accuracy, but it also improves the self-rationalization quality of small LMs across the aforementioned axes better than a supervised fine-tuning (SFT) baseline. Extensive human evaluations confirm that MaRio rationales are preferred vs. SFT rationales, as well as qualitative improvements in plausibility and consistency.
Create account to get full access
Overview
- Large language models (LMs) can generate free-text rationales to help with answering questions
- However, prior work suggests that useful self-rationalization only emerges at very large scales (e.g., 175 billion parameter GPT-3)
- The focus has been on downstream performance, but not on the semantics of the rationales themselves, such as their plausibility, truthfulness, and helpfulness for humans
- This paper presents a method called MaRio that enables smaller-scale LMs (200x smaller than GPT-3) to generate high-quality rationales that improve task performance and are also more plausible, consistent, and diverse
Plain English Explanation
Large language models, which are AI systems trained on vast amounts of text data, have shown the ability to generate free-text explanations or "rationales" to support their answers to questions. This paper explores how to get these rationales to be more useful, even when working with smaller and less powerful language models compared to the largest available ones.
Prior research has found that generating truly helpful self-rationalization only becomes possible at very large model scales, like the 175 billion parameter GPT-3 model. Additionally, the focus has been more on the end task performance, rather than on the quality and characteristics of the rationales themselves. This paper aims to change that by developing a method called MaRio that can produce high-quality rationales from smaller language models.
The key idea behind MaRio is to train the model to optimize for multiple desirable properties of the rationales, like plausibility (whether the reasoning makes sense), consistency (whether the rationale aligns with the answer), and diversity (whether the rationales are varied and not repetitive). By training the model to generate rationales that score well on these attributes, the researchers were able to produce smaller language models that not only improved on the original tasks, but also generated rationales that humans found to be more helpful and convincing.
This work shows that it's possible to get high-quality self-rationalization from language models that are much smaller than the largest available ones, which could make this capability more accessible and useful in practice. The researchers demonstrated this across several challenging question-answering datasets, providing both automatic and human evaluations to validate the improvements.
Technical Explanation
This paper presents a method called MaRio (Multi-reward Rationalization) that enables smaller-scale language models (around 200x smaller than GPT-3) to generate high-quality rationales that not only improve downstream task performance, but also exhibit desirable properties like plausibility, consistency, and diversity.
The key insight is that prior work has largely focused on the end task performance of large language models, without much consideration for the semantics and quality of the rationales themselves. This paper argues that useful self-rationalization is only emergent at very large scales (e.g., 175 billion parameter GPT-3), and sets out to address this by developing a multi-objective training approach.
MaRio is a self-rationalization algorithm that optimizes the language model to generate rationales that score well on multiple distinct properties, including plausibility, diversity, and consistency. This is done by incorporating these attributes as separate reward signals during training, in addition to the standard task-specific objective.
The researchers evaluate MaRio on five challenging question-answering datasets: StrategyQA, QuaRel, OpenBookQA, NumerSense, and QASC. They find that not only does MaRio improve task accuracy compared to a supervised fine-tuning baseline, but it also produces rationales that are rated as more plausible, consistent, and diverse by both automatic metrics and human evaluations.
This work demonstrates that it is possible to obtain high-quality self-rationalization capabilities from much smaller language models than the largest available ones, which could make this functionality more accessible and practical. The explicit modeling of desirable rationale properties during training appears to be a promising approach for improving the interpretability and trustworthiness of language model reasoning.
Critical Analysis
The paper presents a compelling approach for enabling smaller-scale language models to generate high-quality rationales that improve task performance and exhibit desirable properties like plausibility, consistency, and diversity. This is an important contribution, as prior work had suggested that useful self-rationalization was only possible at very large model scales.
One potential limitation of the work is that the evaluation is focused on question-answering tasks, and it's unclear how well the MaRio approach would generalize to other types of language modeling problems. The authors acknowledge this and suggest that exploring the generalizability of their method is an important area for future research.
Additionally, while the human evaluations provide valuable insights into the perceived quality of the rationales, the paper does not delve deeply into the potential biases or limitations of these evaluations. It would be useful to understand more about the demographics and backgrounds of the human raters, as well as any potential cognitive biases that could influence their assessments.
Another potential area for further exploration is the interaction between the task-specific objective and the rationale-focused objectives during training. The paper acknowledges that balancing these different objectives is a challenge, and it would be interesting to see more analysis on how this trade-off is managed and its impact on the final model performance and rationale quality.
Overall, this paper represents an important step forward in improving the interpretability and trustworthiness of language model reasoning, and the MaRio approach appears to be a promising direction for future research. Continued work in this area, such as exploring the applicability of these techniques to larger language models and investigating the potential impacts on downstream applications, could yield valuable insights and advancements for the field.
Conclusion
This paper presents a novel method called MaRio that enables smaller-scale language models to generate high-quality rationales that not only improve downstream task performance, but also exhibit desirable properties like plausibility, consistency, and diversity.
The key innovation is the use of a multi-reward training approach that optimizes the model to produce rationales that score well on these various attributes, in contrast to prior work that has focused more on end task performance alone.
The results show that this approach can yield substantial improvements in the quality of the generated rationales, as measured by both automatic metrics and human evaluations. This is a significant advancement, as prior research had suggested that useful self-rationalization was only possible at very large model scales.
The implications of this work are potentially far-reaching, as the ability to obtain high-quality rationales from smaller and more accessible language models could make this functionality more practical and widely adoptable. Continued research in this direction, exploring the generalizability of the approach and its impact on downstream applications, could lead to important advancements in the interpretability and trustworthiness of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
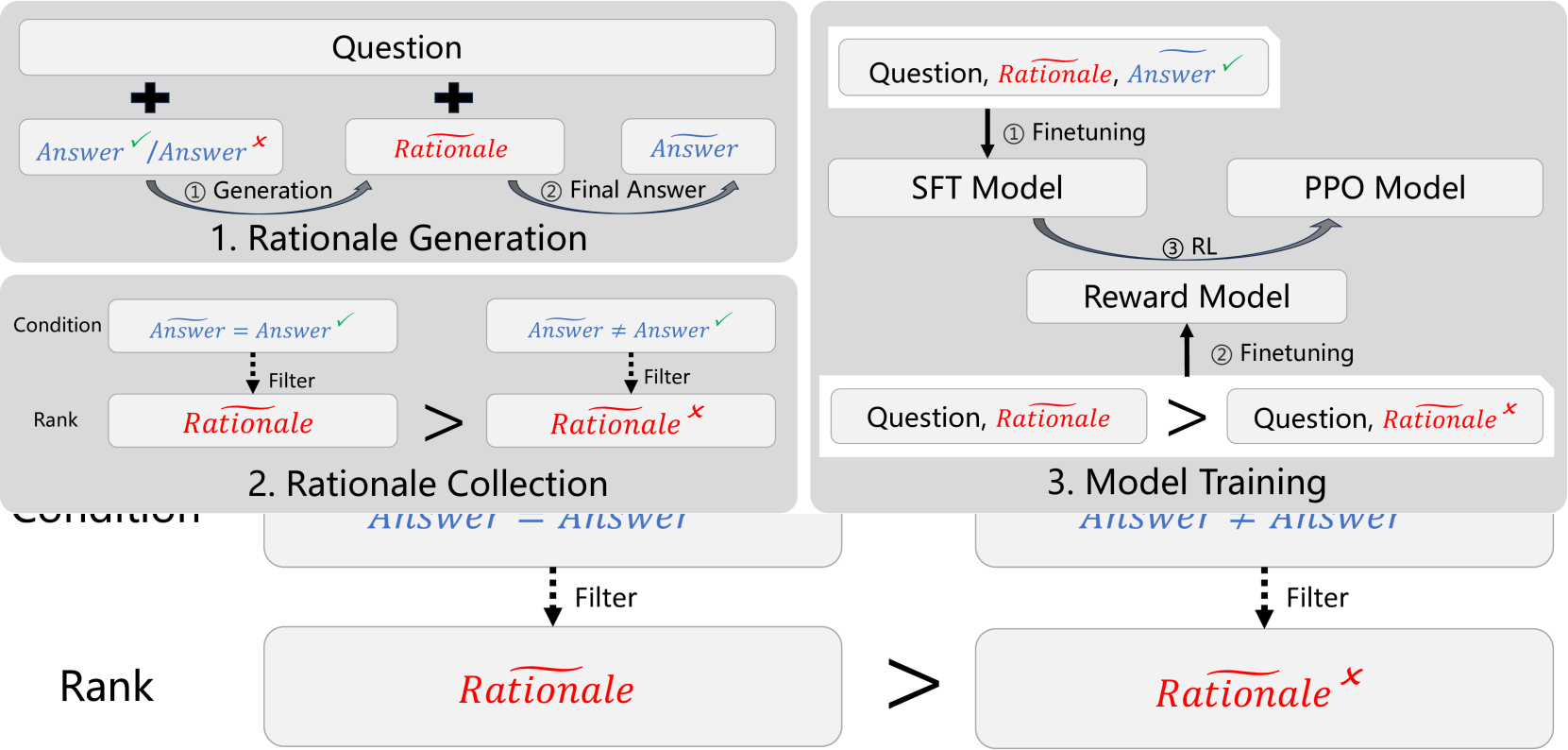
Improving Language Model Reasoning with Self-motivated Learning
Yunlong Feng, Yang Xu, Libo Qin, Yasheng Wang, Wanxiang Che
0
0
Large-scale high-quality training data is important for improving the performance of models. After trained with data that has rationales (reasoning steps), models gain reasoning capability. However, the dataset with high-quality rationales is relatively scarce due to the high annotation cost. To address this issue, we propose textit{Self-motivated Learning} framework. The framework motivates the model itself to automatically generate rationales on existing datasets. Based on the inherent rank from correctness across multiple rationales, the model learns to generate better rationales, leading to higher reasoning capability. Specifically, we train a reward model with the rank to evaluate the quality of rationales, and improve the performance of reasoning through reinforcement learning. Experiment results of Llama2 7B on multiple reasoning datasets show that our method significantly improves the reasoning ability of models, even outperforming text-davinci-002 in some datasets.
5/1/2024
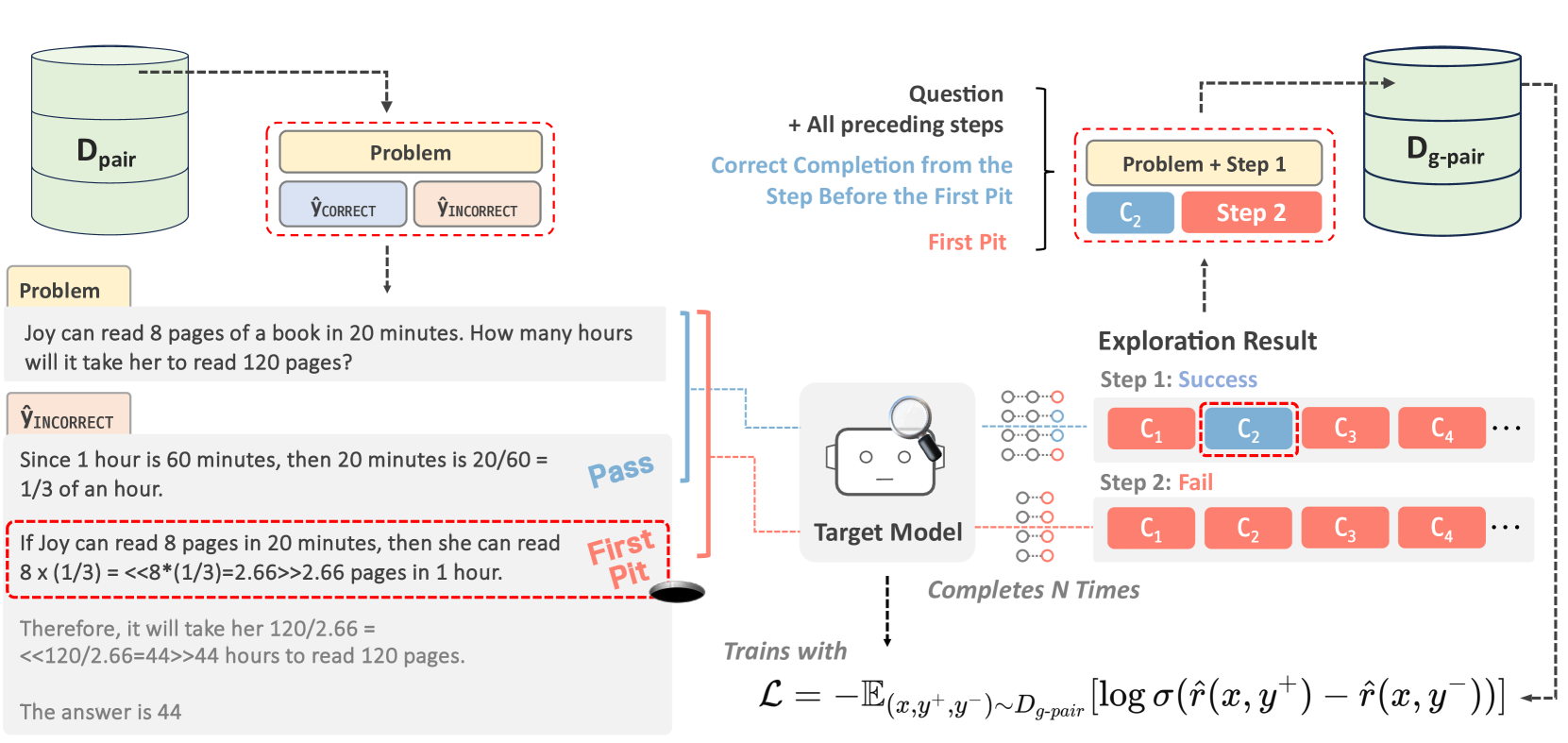
Self-Explore to Avoid the Pit: Improving the Reasoning Capabilities of Language Models with Fine-grained Rewards
Hyeonbin Hwang, Doyoung Kim, Seungone Kim, Seonghyeon Ye, Minjoon Seo
0
0
Training on large amounts of rationales (i.e., CoT Fine-tuning) is effective at improving the reasoning capabilities of large language models (LLMs). However, acquiring human-authored rationales or augmenting rationales from proprietary models is costly and not scalable. In this paper, we study the problem of whether LLMs could self-improve their reasoning capabilities. To this end, we propose Self-Explore, where the LLM is tasked to explore the first wrong step (i.e., the first pit) within the rationale and use such signals as fine-grained rewards for further improvement. On the GSM8K and MATH test set, Self-Explore achieves 11.57% and 2.89% improvement on average across three LLMs compared to supervised fine-tuning (SFT). Our code is available at https://github.com/hbin0701/Self-Explore.
5/17/2024
💬
QCRD: Quality-guided Contrastive Rationale Distillation for Large Language Models
Wei Wang, Zhaowei Li, Qi Xu, Yiqing Cai, Hang Song, Qi Qi, Ran Zhou, Zhida Huang, Tao Wang, Li Xiao
0
0
Deploying large language models (LLMs) poses challenges in terms of resource limitations and inference efficiency. To address these challenges, recent research has focused on using smaller task-specific language models, which are enhanced by distilling the knowledge rationales generated by LLMs. However, previous works mostly emphasize the effectiveness of positive knowledge, while overlooking the knowledge noise and the exploration of negative knowledge. In this paper, we first propose a general approach called quality-guided contrastive rationale distillation for reasoning capacity learning, considering contrastive learning perspectives. For the learning of positive knowledge, we collect positive rationales through self-consistency to denoise the LLM rationales generated by temperature sampling. For the negative knowledge distillation, we generate negative rationales using temperature sampling for the iteration-before smaller language models themselves. Finally, a contrastive loss is designed to better distill the positive and negative rationales into the smaller language model, where an online-update discriminator is used to judge the qualities of rationales and assign weights for better optimizing the training process. Through extensive experiments on multiple reasoning tasks, we demonstrate that our method consistently outperforms the previous distillation methods and produces higher-quality rationales.
5/24/2024
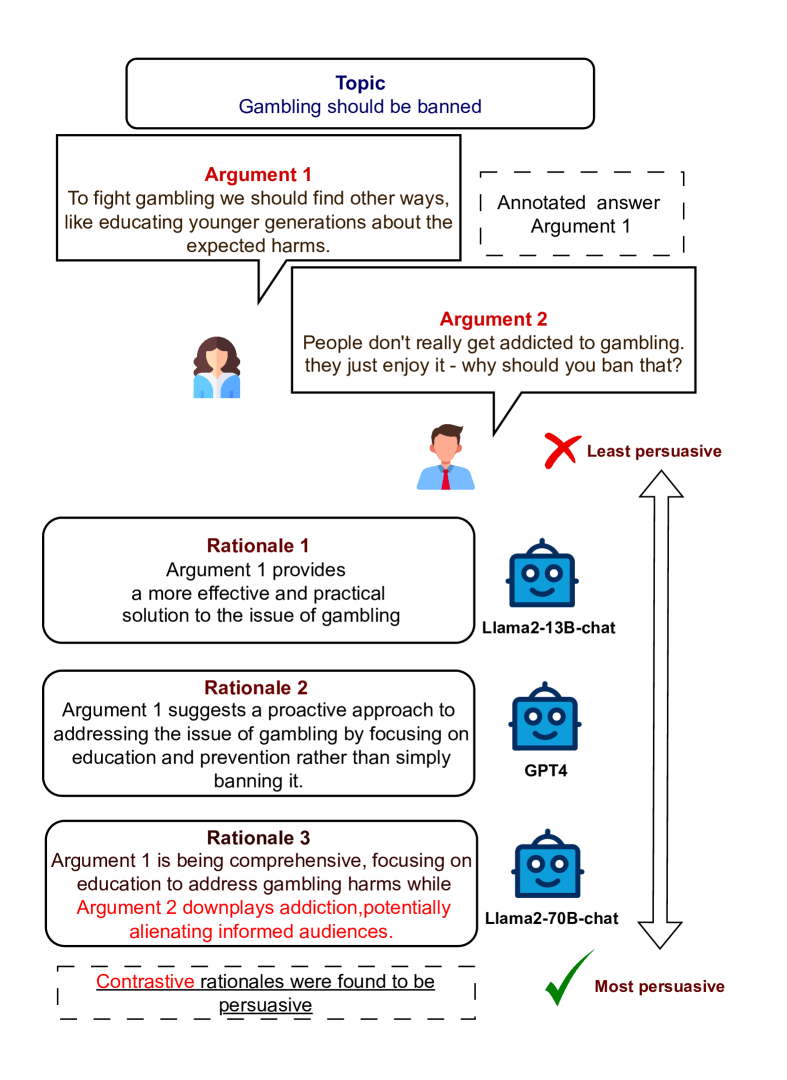
Persuasiveness of Generated Free-Text Rationales in Subjective Decisions: A Case Study on Pairwise Argument Ranking
Mohamed Elaraby, Diane Litman, Xiang Lorraine Li, Ahmed Magooda
0
0
Generating free-text rationales is among the emergent capabilities of Large Language Models (LLMs). These rationales have been found to enhance LLM performance across various NLP tasks. Recently, there has been growing interest in using these rationales to provide insights for various important downstream tasks. In this paper, we analyze generated free-text rationales in tasks with subjective answers, emphasizing the importance of rationalization in such scenarios. We focus on pairwise argument ranking, a highly subjective task with significant potential for real-world applications, such as debate assistance. We evaluate the persuasiveness of rationales generated by nine LLMs to support their subjective choices. Our findings suggest that open-source LLMs, particularly Llama2-70B-chat, are capable of providing highly persuasive rationalizations, surpassing even GPT models. Additionally, our experiments show that rationale persuasiveness can be improved by controlling its parameters through prompting or through self-refinement.
6/21/2024