ROSE: A Recognition-Oriented Speech Enhancement Framework in Air Traffic Control Using Multi-Objective Learning

0

Sign in to get full access
Overview
- The paper presents a framework called ROSE (Recognition-Oriented Speech Enhancement) for improving speech recognition in air traffic control environments.
- ROSE uses a multi-objective learning approach to jointly optimize speech enhancement and speech recognition.
- The framework includes an attention-based skip-fusion module to effectively combine clean and enhanced speech representations.
- Experiments show that ROSE outperforms conventional speech enhancement methods in terms of both speech quality and recognition accuracy.
Plain English Explanation
ROSE: A Recognition-Oriented Speech Enhancement Framework in Air Traffic Control Using Multi-Objective Learning addresses the challenge of improving speech recognition accuracy in noisy air traffic control environments. The researchers developed a framework called ROSE that takes a novel approach to this problem.
Typically, speech enhancement and speech recognition are treated as separate tasks. ROSE, on the other hand, uses a multi-objective learning approach to optimize both tasks simultaneously. This means the system is trained to not only enhance the quality of the speech signal, but also to improve the accuracy of the speech recognition.
A key component of ROSE is the attention-based skip-fusion module, which allows the system to effectively combine the clean speech representation and the enhanced speech representation. This helps the model leverage the strengths of both the original and processed speech signals.
Through experiments, the researchers found that ROSE outperforms conventional speech enhancement methods in terms of both speech quality and speech recognition accuracy. This suggests that the joint optimization of these two tasks can lead to significant improvements in the performance of speech-based systems in challenging real-world environments like air traffic control.
Technical Explanation
The ROSE framework proposed in the paper takes a multi-objective learning approach to simultaneously optimize speech enhancement and speech recognition. This is in contrast to the conventional approach of treating these as separate tasks.
The core of the ROSE architecture is an attention-based skip-fusion module. This module allows the model to effectively combine the clean speech representation and the enhanced speech representation. The attention mechanism helps the model learn the optimal way to fuse these two sources of information.
The multi-objective learning objective function includes terms for both speech quality (e.g., signal-to-noise ratio) and speech recognition accuracy. By optimizing these objectives jointly, the model is able to produce enhanced speech that is not only of high quality, but also well-suited for accurate recognition.
The researchers evaluated ROSE on a dataset of air traffic control speech, and found that it outperformed conventional speech enhancement methods in terms of both objective speech quality metrics and speech recognition accuracy. This demonstrates the benefits of the joint optimization approach used in ROSE.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the ROSE framework, including comparisons to several baseline methods. However, the authors do not discuss any major limitations or caveats of their approach.
One potential issue that could be explored further is the generalization of ROSE to other noisy environments beyond air traffic control. The researchers should investigate how well the framework performs when applied to different domains with different types of background noise and speaking styles.
Additionally, the authors could explore the interpretability of the attention-based skip-fusion module. Understanding how the model is combining the clean and enhanced speech representations could provide insights into the strengths and weaknesses of the approach.
Overall, the ROSE framework represents a promising advance in the field of speech enhancement for improved recognition accuracy in challenging real-world environments. Further research to address the potential limitations could help strengthen the impact of this work.
Conclusion
The ROSE framework presented in this paper offers a novel approach to speech enhancement for air traffic control applications. By jointly optimizing speech quality and recognition accuracy using a multi-objective learning strategy, ROSE is able to outperform conventional speech enhancement methods.
The attention-based skip-fusion module is a key innovation that allows ROSE to effectively combine clean and enhanced speech representations. This helps the system leverage the strengths of both the original and processed speech signals.
The promising results of this work suggest that the joint optimization of speech enhancement and recognition can lead to significant improvements in the performance of speech-based systems in challenging real-world environments. Further research to address potential limitations and expand the generalization of ROSE could help unlock even greater benefits for applications like air traffic control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ROSE: A Recognition-Oriented Speech Enhancement Framework in Air Traffic Control Using Multi-Objective Learning
Xincheng Yu, Dongyue Guo, Jianwei Zhang, Yi Lin
Radio speech echo is a specific phenomenon in the air traffic control (ATC) domain, which degrades speech quality and further impacts automatic speech recognition (ASR) accuracy. In this work, a time-domain recognition-oriented speech enhancement (ROSE) framework is proposed to improve speech intelligibility and also advance ASR accuracy based on convolutional encoder-decoder-based U-Net framework, which serves as a plug-and-play tool in ATC scenarios and does not require additional retraining of the ASR model. Specifically, 1) In the U-Net architecture, an attention-based skip-fusion (ABSF) module is applied to mine shared features from encoders using an attention mask, which enables the model to effectively fuse the hierarchical features. 2) A channel and sequence attention (CSAtt) module is innovatively designed to guide the model to focus on informative features in dual parallel attention paths, aiming to enhance the effective representations and suppress the interference noises. 3) Based on the handcrafted features, ASR-oriented optimization targets are designed to improve recognition performance in the ATC environment by learning robust feature representations. By incorporating both the SE-oriented and ASR-oriented losses, ROSE is implemented in a multi-objective learning manner by optimizing shared representations across the two task objectives. The experimental results show that the ROSE significantly outperforms other state-of-the-art methods for both the SE and ASR tasks, in which all the proposed improvements are confirmed by designed experiments. In addition, the proposed approach can contribute to the desired performance improvements on public datasets.
Read more7/31/2024

0
Joint vs Sequential Speaker-Role Detection and Automatic Speech Recognition for Air-traffic Control
Alexander Blatt, Aravind Krishnan, Dietrich Klakow
Utilizing air-traffic control (ATC) data for downstream natural-language processing tasks requires preprocessing steps. Key steps are the transcription of the data via automatic speech recognition (ASR) and speaker diarization, respectively speaker role detection (SRD) to divide the transcripts into pilot and air-traffic controller (ATCO) transcripts. While traditional approaches take on these tasks separately, we propose a transformer-based joint ASR-SRD system that solves both tasks jointly while relying on a standard ASR architecture. We compare this joint system against two cascaded approaches for ASR and SRD on multiple ATC datasets. Our study shows in which cases our joint system can outperform the two traditional approaches and in which cases the other architectures are preferable. We additionally evaluate how acoustic and lexical differences influence all architectures and show how to overcome them for our joint architecture.
Read more6/21/2024
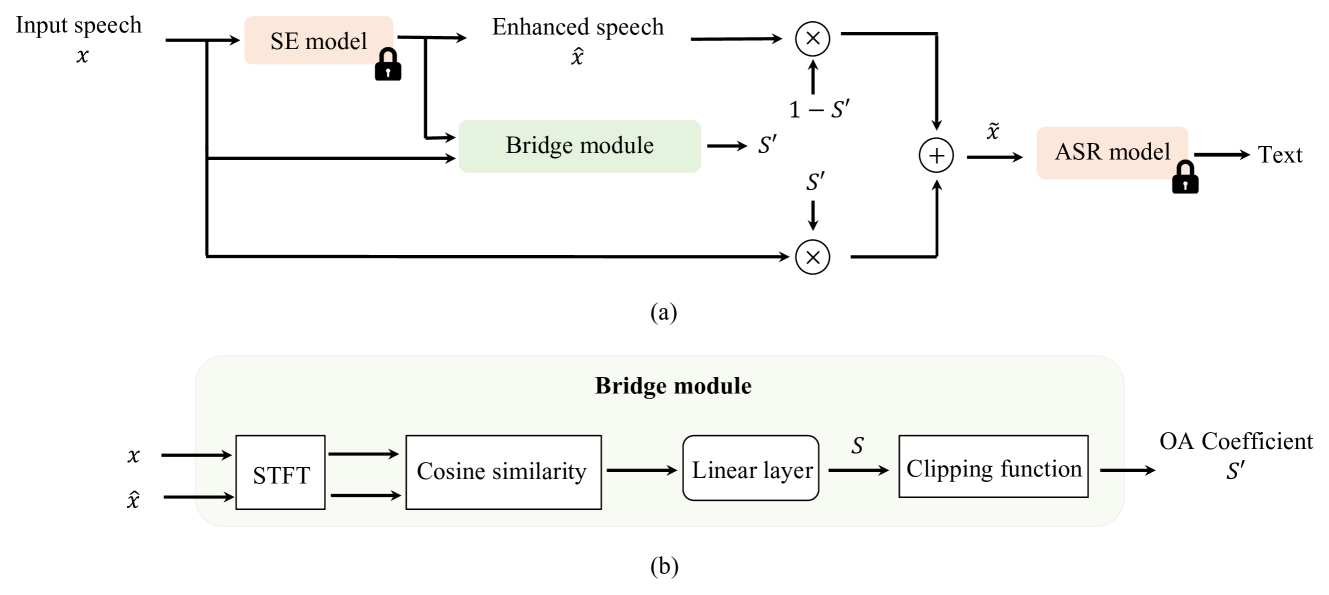
0
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
Read more6/19/2024
🗣️
0
Flexible Multichannel Speech Enhancement for Noise-Robust Frontend
Ante Juki'c, Jagadeesh Balam, Boris Ginsburg
This paper proposes a flexible multichannel speech enhancement system with the main goal of improving robustness of automatic speech recognition (ASR) in noisy conditions. The proposed system combines a flexible neural mask estimator applicable to different channel counts and configurations and a multichannel filter with automatic reference selection. A transform-attend-concatenate layer is proposed to handle cross-channel information in the mask estimator, which is shown to be effective for arbitrary microphone configurations. The presented evaluation demonstrates the effectiveness of the flexible system for several seen and unseen compact array geometries, matching the performance of fixed configuration-specific systems. Furthermore, a significantly improved ASR performance is observed for configurations with randomly-placed microphones.
Read more6/10/2024