RulePrompt: Weakly Supervised Text Classification with Prompting PLMs and Self-Iterative Logical Rules

0

Sign in to get full access
Overview
- This paper introduces RulePrompt, a weakly supervised text classification approach that combines prompting pre-trained language models (PLMs) with self-iterative logical rules.
- RulePrompt leverages seed words to bootstrap the classification process and then iteratively refines the classification rules using the model's predictions.
- The authors demonstrate the effectiveness of RulePrompt on various text classification tasks, showing it can achieve competitive performance with limited labeled data.
Plain English Explanation
RulePrompt is a new way to classify text when you don't have a lot of labeled data. It works by using a few example words, called "seed words," to get the classification process started. Then, it repeatedly refines the classification rules based on the model's own predictions, gradually improving the results.
The key idea is to combine two powerful techniques: prompting pre-trained language models and using logical rules. Prompting allows the model to generate relevant text based on the seed words, while the logical rules help the model learn patterns in the data and make better classifications over time.
This approach is particularly useful when you have a limited amount of labeled data for training a text classifier. By starting with just a few examples and iteratively improving the rules, RulePrompt can achieve competitive performance without needing a large, fully labeled dataset. [This is similar to how prompt-tuned embedding classification can effectively classify text with limited data.]
Technical Explanation
RulePrompt is a weakly supervised text classification method that leverages pre-trained language models (PLMs) and iterative logical rules. The approach starts by defining a set of "seed words" that represent the target classes. These seed words are used to prompt the PLM, generating text that is likely to be relevant to each class.
The generated text is then used to mine logical rules that capture patterns in the data. These rules are applied to the unlabeled data to generate pseudo-labels, which are used to fine-tune the PLM. The process then iterates, with the updated model being used to generate new text, mine new rules, and refine the pseudo-labels. [This is similar to how language models can leverage context to improve text classification.]
The authors evaluate RulePrompt on several text classification tasks, including topic classification, sentiment analysis, and named entity recognition. They demonstrate that RulePrompt can achieve competitive performance compared to fully supervised approaches, while requiring significantly less labeled data. [This is analogous to how generation-driven contrastive self-training can enable zero-shot learning with limited data.]
Critical Analysis
The RulePrompt approach shows promising results, but there are a few potential limitations and areas for further research:
-
The effectiveness of the method may depend on the quality and relevance of the seed words. If the seed words do not capture the key characteristics of the target classes, the rule mining and pseudo-labeling process may struggle to converge to accurate classifications.
-
The iterative rule refinement process can be computationally expensive, especially as the number of rules and the complexity of the logical expressions grow. Techniques to efficiently manage the rule space may be needed for scalability.
-
While the authors demonstrate RulePrompt's effectiveness on several tasks, it would be valuable to explore its performance on a wider range of text classification problems, including more complex, multi-label, or domain-specific tasks. [This could be similar to how text prompts can guide weakly supervised video classification.]
-
The paper does not provide a deep analysis of the types of logical rules that are most effective for different classification tasks. Further research into rule mining strategies and their relative strengths could help improve the overall performance and interpretability of the RulePrompt approach.
Conclusion
RulePrompt is a novel weakly supervised text classification method that combines the power of prompting pre-trained language models with the flexibility of iterative logical rules. By starting with just a few seed words and gradually refining the classification rules, RulePrompt can achieve competitive performance on a variety of text classification tasks without requiring a large, fully labeled dataset.
This approach represents an important step towards more efficient and scalable text classification, particularly in domains where labeled data is scarce. [Similar to how convolutional prompting meets language models can enable continual learning, RulePrompt's combination of prompting and logical rules could have broader applications in other areas of natural language processing.]
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RulePrompt: Weakly Supervised Text Classification with Prompting PLMs and Self-Iterative Logical Rules
Miaomiao Li, Jiaqi Zhu, Yang Wang, Yi Yang, Yilin Li, Hongan Wang
Weakly supervised text classification (WSTC), also called zero-shot or dataless text classification, has attracted increasing attention due to its applicability in classifying a mass of texts within the dynamic and open Web environment, since it requires only a limited set of seed words (label names) for each category instead of labeled data. With the help of recently popular prompting Pre-trained Language Models (PLMs), many studies leveraged manually crafted and/or automatically identified verbalizers to estimate the likelihood of categories, but they failed to differentiate the effects of these category-indicative words, let alone capture their correlations and realize adaptive adjustments according to the unlabeled corpus. In this paper, in order to let the PLM effectively understand each category, we at first propose a novel form of rule-based knowledge using logical expressions to characterize the meanings of categories. Then, we develop a prompting PLM-based approach named RulePrompt for the WSTC task, consisting of a rule mining module and a rule-enhanced pseudo label generation module, plus a self-supervised fine-tuning module to make the PLM align with this task. Within this framework, the inaccurate pseudo labels assigned to texts and the imprecise logical rules associated with categories mutually enhance each other in an alternative manner. That establishes a self-iterative closed loop of knowledge (rule) acquisition and utilization, with seed words serving as the starting point. Extensive experiments validate the effectiveness and robustness of our approach, which markedly outperforms state-of-the-art weakly supervised methods. What is more, our approach yields interpretable category rules, proving its advantage in disambiguating easily-confused categories.
Read more4/26/2024
0
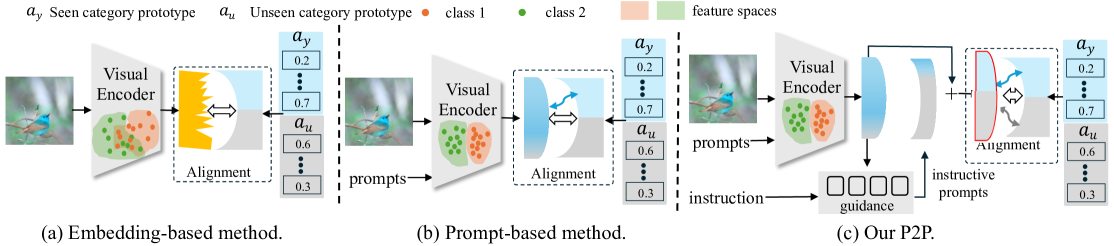
Instructing Prompt-to-Prompt Generation for Zero-Shot Learning
Man Liu, Huihui Bai, Feng Li, Chunjie Zhang, Yunchao Wei, Meng Wang, Tat-Seng Chua, Yao Zhao
Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a textbf{P}rompt-to-textbf{P}rompt generation methodology (textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
Read more6/6/2024

0
End User Authoring of Personalized Content Classifiers: Comparing Example Labeling, Rule Writing, and LLM Prompting
Leijie Wang, Kathryn Yurechko, Pranati Dani, Quan Ze Chen, Amy X. Zhang
Existing tools for laypeople to create personal classifiers often assume a motivated user working uninterrupted in a single, lengthy session. However, users tend to engage with social media casually, with many short sessions on an ongoing, daily basis. To make creating personal classifiers for content curation easier for such users, tools should support rapid initialization and iterative refinement. In this work, we compare three strategies -- (1) example labeling, (2) rule writing, and (3) large language model (LLM) prompting -- for end users to build personal content classifiers. From an experiment with 37 non-programmers tasked with creating personalized comment moderation filters, we found that with LLM prompting, participants reached 95% of peak performance in 5 minutes, beating other strategies due to higher recall, but all strategies struggled with iterative refinement. Despite LLM prompting's better performance, participants preferred different strategies in different contexts and, even when prompting, provided examples or wrote rule-like prompts, suggesting hybrid approaches.
Read more9/6/2024
🖼️
0
Pseudo-Prompt Generating in Pre-trained Vision-Language Models for Multi-Label Medical Image Classification
Yaoqin Ye, Junjie Zhang, Hongwei Shi
The task of medical image recognition is notably complicated by the presence of varied and multiple pathological indications, presenting a unique challenge in multi-label classification with unseen labels. This complexity underlines the need for computer-aided diagnosis methods employing multi-label zero-shot learning. Recent advancements in pre-trained vision-language models (VLMs) have showcased notable zero-shot classification abilities on medical images. However, these methods have limitations on leveraging extensive pre-trained knowledge from broader image datasets, and often depend on manual prompt construction by expert radiologists. By automating the process of prompt tuning, prompt learning techniques have emerged as an efficient way to adapt VLMs to downstream tasks. Yet, existing CoOp-based strategies fall short in performing class-specific prompts on unseen categories, limiting generalizability in fine-grained scenarios. To overcome these constraints, we introduce a novel prompt generation approach inspirited by text generation in natural language processing (NLP). Our method, named Pseudo-Prompt Generating (PsPG), capitalizes on the priori knowledge of multi-modal features. Featuring a RNN-based decoder, PsPG autoregressively generates class-tailored embedding vectors, i.e., pseudo-prompts. Comparative evaluations on various multi-label chest radiograph datasets affirm the superiority of our approach against leading medical vision-language and multi-label prompt learning methods. The source code is available at https://github.com/fallingnight/PsPG
Read more9/16/2024