Caterpillar: A Pure-MLP Architecture with Shifted-Pillars-Concatenation

0
🖼️
Sign in to get full access
Overview
- Modeling in computer vision has evolved to use multilayer perceptrons (MLPs).
- Vision MLPs lack the ability to model local features, which is typically addressed by combining them with convolutional layers.
- Convolution also has drawbacks, such as redundancy and lower parallel computation due to the sliding window scheme.
- This paper proposes a new MLP module called Shifted-Pillars-Concatenation (SPC) to address these issues.
Plain English Explanation
The paper explains how modern computer vision models have moved from using traditional convolutional neural networks (CNNs) to using multilayer perceptrons (MLPs). However, one downside of using pure MLPs for vision tasks is that they lack the ability to capture local spatial relationships in the input data, which is an important capability for tasks like image classification.
To address this, the researchers propose a new MLP module called Shifted-Pillars-Concatenation (SPC). SPC works by first generating four "shifted" versions of the input image, each shifted in a different direction. It then applies linear transformations to these shifted versions and concatenates the results to aggregate local features.
The researchers show that this SPC module provides superior local modeling power compared to traditional convolutional layers, while also being more parallelizable and efficient. They then build a pure-MLP architecture called "Caterpillar" by replacing the convolutional layers in a hybrid model with the SPC module. Extensive experiments demonstrate that Caterpillar achieves excellent performance on both small-scale and large-scale image classification benchmarks, with the added benefits of remarkable scalability and transferability.
Technical Explanation
The paper proposes a new MLP module called Shifted-Pillars-Concatenation (SPC) to address the local modeling limitations of traditional vision MLPs. SPC consists of two key steps:
- Pillars-Shift: This step generates four neighboring feature maps by shifting the input image along the four cardinal directions (up, down, left, right).
- Pillars-Concatenation: This step applies linear transformations to the shifted feature maps and concatenates the results to aggregate local features.
By incorporating this SPC module, the researchers build a pure-MLP architecture called "Caterpillar" that replaces the convolutional layers in a hybrid model (sMLPNet) with the SPC module. Extensive experiments on both small-scale and ImageNet-1k classification benchmarks demonstrate that Caterpillar achieves excellent performance, with remarkable scalability and transfer capability.
Critical Analysis
The paper presents a novel approach to improving the local modeling capabilities of vision MLPs, which is a critical limitation of these models. The proposed Shifted-Pillars-Concatenation (SPC) module is a clever and relatively simple solution that effectively captures local spatial relationships without the drawbacks of traditional convolutional layers.
However, the paper does not provide a detailed analysis of the computational and memory efficiency of the SPC module compared to convolutional layers. While the researchers claim that SPC is more parallelizable, they do not quantify the potential speedups or memory savings. Additionally, the paper does not explore the limitations of the SPC module, such as its ability to model long-range dependencies or its performance on more complex vision tasks beyond classification.
Further research could investigate the performance of SPC-based architectures on tasks like object detection, segmentation, or generative modeling, as well as compare its efficiency to other recently proposed MLP-based vision models, such as SpiralMLP or SA-MLP. Exploring the biological inspiration behind the SPC module could also yield interesting insights.
Conclusion
This paper presents a promising solution to the local modeling limitations of vision MLPs through the introduction of the Shifted-Pillars-Concatenation (SPC) module. By combining shifted feature maps and concatenation, SPC offers superior local modeling power and performance gains, making it a compelling alternative to traditional convolutional layers.
The pure-MLP "Caterpillar" architecture built using the SPC module demonstrates excellent results on both small-scale and large-scale image classification benchmarks, while also exhibiting impressive scalability and transfer capabilities. This work contributes to the ongoing research on developing efficient and effective MLP-based models for computer vision tasks, with potential implications for the broader field of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Caterpillar: A Pure-MLP Architecture with Shifted-Pillars-Concatenation
Jin Sun, Xiaoshuang Shi, Zhiyuan Wang, Kaidi Xu, Heng Tao Shen, Xiaofeng Zhu
Modeling in Computer Vision has evolved to MLPs. Vision MLPs naturally lack local modeling capability, to which the simplest treatment is combined with convolutional layers. Convolution, famous for its sliding window scheme, also suffers from this scheme of redundancy and lower parallel computation. In this paper, we seek to dispense with the windowing scheme and introduce a more elaborate and parallelizable method to exploit locality. To this end, we propose a new MLP module, namely Shifted-Pillars-Concatenation (SPC), that consists of two steps of processes: (1) Pillars-Shift, which generates four neighboring maps by shifting the input image along four directions, and (2) Pillars-Concatenation, which applies linear transformations and concatenation on the maps to aggregate local features. SPC module offers superior local modeling power and performance gains, making it a promising alternative to the convolutional layer. Then, we build a pure-MLP architecture called Caterpillar by replacing the convolutional layer with the SPC module in a hybrid model of sMLPNet. Extensive experiments show Caterpillar's excellent performance on both small-scale and ImageNet-1k classification benchmarks, with remarkable scalability and transfer capability possessed as well. The code is available at https://github.com/sunjin19126/Caterpillar.
Read more9/11/2024
0
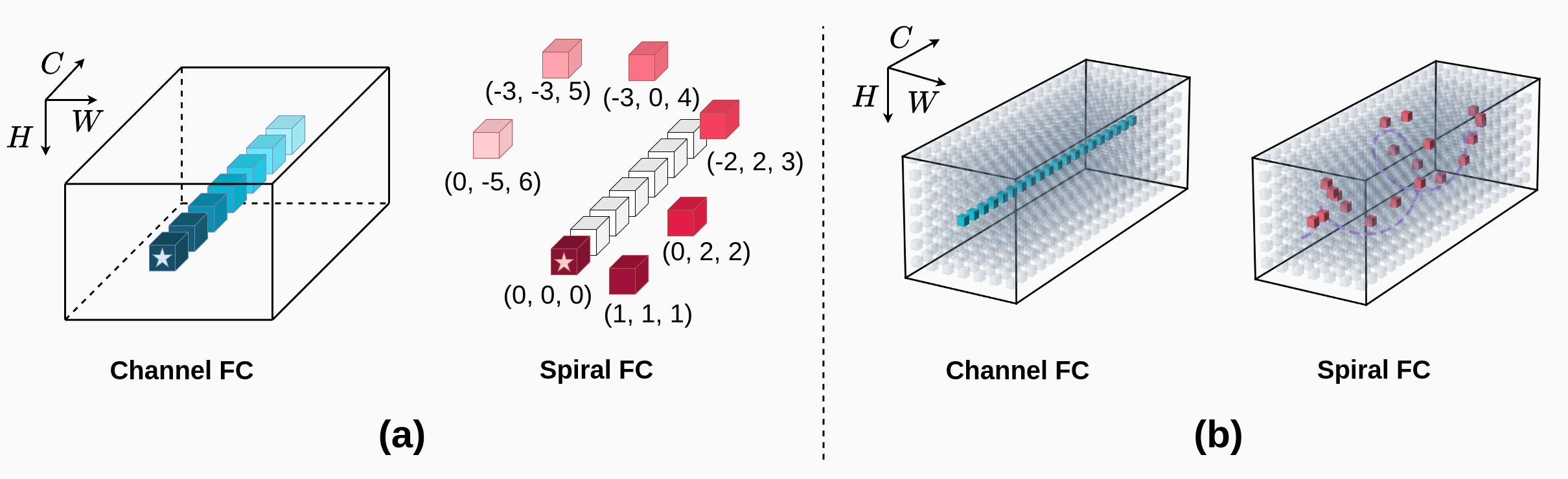
SpiralMLP: A Lightweight Vision MLP Architecture
Haojie Mu, Burhan Ul Tayyab, Nicholas Chua
We present SpiralMLP, a novel architecture that introduces a Spiral FC layer as a replacement for the conventional Token Mixing approach. Differing from several existing MLP-based models that primarily emphasize axes, our Spiral FC layer is designed as a deformable convolution layer with spiral-like offsets. We further adapt Spiral FC into two variants: Self-Spiral FC and Cross-Spiral FC, which enable both local and global feature integration seamlessly, eliminating the need for additional processing steps. To thoroughly investigate the effectiveness of the spiral-like offsets and validate our design, we conduct ablation studies and explore optimal configurations. In empirical tests, SpiralMLP reaches state-of-the-art performance, similar to Transformers, CNNs, and other MLPs, benchmarking on ImageNet-1k, COCO and ADE20K. SpiralMLP still maintains linear computational complexity O(HW) and is compatible with varying input image resolutions. Our study reveals that targeting the full receptive field is not essential for achieving high performance, instead, adopting a refined approach offers better results.
Read more9/5/2024
0
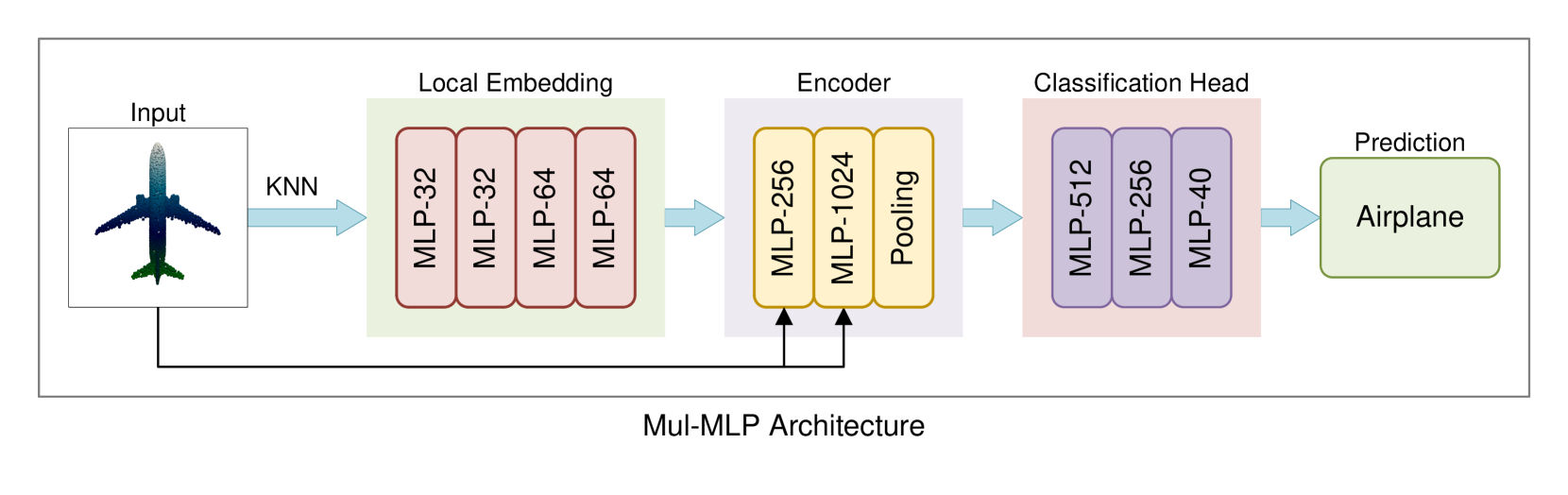
SA-MLP: Enhancing Point Cloud Classification with Efficient Addition and Shift Operations in MLP Architectures
Qiang Zheng, Chao Zhang, Jian Sun
This study addresses the computational inefficiencies in point cloud classification by introducing novel MLP-based architectures inspired by recent advances in CNN optimization. Traditional neural networks heavily rely on multiplication operations, which are computationally expensive. To tackle this, we propose Add-MLP and Shift-MLP, which replace multiplications with addition and shift operations, respectively, significantly enhancing computational efficiency. Building on this, we introduce SA-MLP, a hybrid model that intermixes alternately distributed shift and adder layers to replace MLP layers, maintaining the original number of layers without freezing shift layer weights. This design contrasts with the ShiftAddNet model from previous literature, which replaces convolutional layers with shift and adder layers, leading to a doubling of the number of layers and limited representational capacity due to frozen shift weights. Moreover, SA-MLP optimizes learning by setting distinct learning rates and optimizers specifically for the adder and shift layers, fully leveraging their complementary strengths. Extensive experiments demonstrate that while Add-MLP and Shift-MLP achieve competitive performance, SA-MLP significantly surpasses the multiplication-based baseline MLP model and achieves performance comparable to state-of-the-art MLP-based models. This study offers an efficient and effective solution for point cloud classification, balancing performance with computational efficiency.
Read more9/4/2024

0
Lateralization MLP: A Simple Brain-inspired Architecture for Diffusion
Zizhao Hu, Mohammad Rostami
The Transformer architecture has dominated machine learning in a wide range of tasks. The specific characteristic of this architecture is an expensive scaled dot-product attention mechanism that models the inter-token interactions, which is known to be the reason behind its success. However, such a mechanism does not have a direct parallel to the human brain which brings the question if the scaled-dot product is necessary for intelligence with strong expressive power. Inspired by the lateralization of the human brain, we propose a new simple but effective architecture called the Lateralization MLP (L-MLP). Stacking L-MLP blocks can generate complex architectures. Each L-MLP block is based on a multi-layer perceptron (MLP) that permutes data dimensions, processes each dimension in parallel, merges them, and finally passes through a joint MLP. We discover that this specific design outperforms other MLP variants and performs comparably to a transformer-based architecture in the challenging diffusion task while being highly efficient. We conduct experiments using text-to-image generation tasks to demonstrate the effectiveness and efficiency of L-MLP. Further, we look into the model behavior and discover a connection to the function of the human brain. Our code is publicly available: url{https://github.com/zizhao-hu/L-MLP}
Read more5/28/2024