SA-WavLM: Speaker-Aware Self-Supervised Pre-training for Mixture Speech

0

Sign in to get full access
Overview
- This paper introduces SA-WavLM, a speaker-aware self-supervised pre-training approach for speech processing tasks, particularly mixture speech.
- SA-WavLM builds upon the WavLM model and incorporates speaker-aware pre-training to improve performance on downstream tasks involving speech mixtures.
- The authors demonstrate the effectiveness of SA-WavLM on tasks such as speech separation, speaker diarization, and speech emotion recognition, outperforming previous state-of-the-art methods.
Plain English Explanation
The paper presents a new way of training a speech processing model called SA-WavLM, which stands for "Speaker-Aware WavLM." The key idea is to make the model more aware of the different speakers in the audio it processes, especially when dealing with situations where multiple people are speaking at the same time (known as "speech mixtures").
The researchers built SA-WavLM by modifying an existing speech model called WavLM, which was already good at processing speech. They added some extra training steps to help the model learn to identify and distinguish between different speakers. This allows SA-WavLM to perform better on tasks like separating the voices in a speech mixture, determining who is speaking when (speaker diarization), and recognizing the emotions in someone's speech.
The key benefit of this approach is that it can improve the performance of speech processing systems in real-world scenarios where multiple people are speaking at the same time, which is a common challenge. By making the model more "speaker-aware," it can better handle these complex audio environments.
Technical Explanation
The paper introduces a speaker-aware self-supervised pre-training approach called SA-WavLM, which builds upon the WavLM model. WavLM is a pre-trained speech representation model that has shown strong performance on various speech processing tasks.
The key innovation in SA-WavLM is the addition of speaker-aware pre-training, which aims to make the model more sensitive to speaker information. This is achieved by incorporating two new pre-training tasks:
- Speaker Classification: The model is trained to classify the speaker identity from the input speech. This helps the model learn speaker-discriminative features.
- Speaker Verification: The model is trained to determine whether two speech segments belong to the same speaker or not. This further reinforces the model's ability to distinguish between different speakers.
These speaker-aware pre-training tasks are performed in addition to the original WavLM pre-training objectives, which include masked speech modeling and contrastive loss.
The authors evaluate SA-WavLM on several downstream tasks, including:
- Speech Separation: Separating the individual speech signals from a mixture of speakers.
- Speaker Diarization: Determining who is speaking when in a multi-speaker audio recording.
- Speech Emotion Recognition: Recognizing the emotional state of the speaker.
The results show that SA-WavLM outperforms previous state-of-the-art methods on these tasks, demonstrating the effectiveness of the speaker-aware pre-training approach.
Critical Analysis
The paper presents a well-designed and thorough study on the benefits of incorporating speaker-aware pre-training for speech processing tasks, particularly those involving speech mixtures. The authors have carefully compared SA-WavLM against relevant baselines and state-of-the-art methods, providing a comprehensive evaluation.
One potential limitation of the study is that it focuses primarily on evaluating SA-WavLM on a limited set of tasks, namely speech separation, speaker diarization, and speech emotion recognition. While these are important and relevant applications, it would be valuable to see how the model performs on a wider range of speech processing tasks, such as speech recognition, speech translation, or speech synthesis.
Additionally, the authors do not provide a detailed analysis of the model's performance in complex real-world scenarios, such as noisy environments, distant microphone settings, or multi-lingual settings. Evaluating the model's robustness and generalization capabilities in these more challenging conditions would further strengthen the claims about the model's effectiveness.
Overall, the paper presents a promising approach to improving speech processing systems by leveraging speaker-aware pre-training. The results are compelling, and the authors have made a valuable contribution to the field of speech processing. Further exploration of the model's capabilities and limitations could lead to even more impactful applications.
Conclusion
This paper introduces SA-WavLM, a speaker-aware self-supervised pre-training approach for speech processing tasks, particularly those involving speech mixtures. By incorporating speaker-aware pre-training tasks, the model is able to learn more speaker-discriminative features, which leads to improved performance on downstream tasks such as speech separation, speaker diarization, and speech emotion recognition.
The key significance of this research is its potential to enhance the robustness and performance of speech processing systems in real-world scenarios where multiple speakers are present. By making the model more "speaker-aware," it can better handle the challenges posed by speech mixtures, a common occurrence in many practical applications.
The promising results presented in this paper suggest that further exploration of speaker-aware pre-training techniques could lead to even more advancements in the field of speech processing, with far-reaching implications for a wide range of applications, from voice assistants to meeting transcription systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SA-WavLM: Speaker-Aware Self-Supervised Pre-training for Mixture Speech
Jingru Lin, Meng Ge, Junyi Ao, Liqun Deng, Haizhou Li
It was shown that pre-trained models with self-supervised learning (SSL) techniques are effective in various downstream speech tasks. However, most such models are trained on single-speaker speech data, limiting their effectiveness in mixture speech. This motivates us to explore pre-training on mixture speech. This work presents SA-WavLM, a novel pre-trained model for mixture speech. Specifically, SA-WavLM follows an extract-merge-predict pipeline in which the representations of each speaker in the input mixture are first extracted individually and then merged before the final prediction. In this pipeline, SA-WavLM performs speaker-informed extractions with the consideration of the interactions between different speakers. Furthermore, a speaker shuffling strategy is proposed to enhance the robustness towards the speaker absence. Experiments show that SA-WavLM either matches or improves upon the state-of-the-art pre-trained models.
Read more7/4/2024
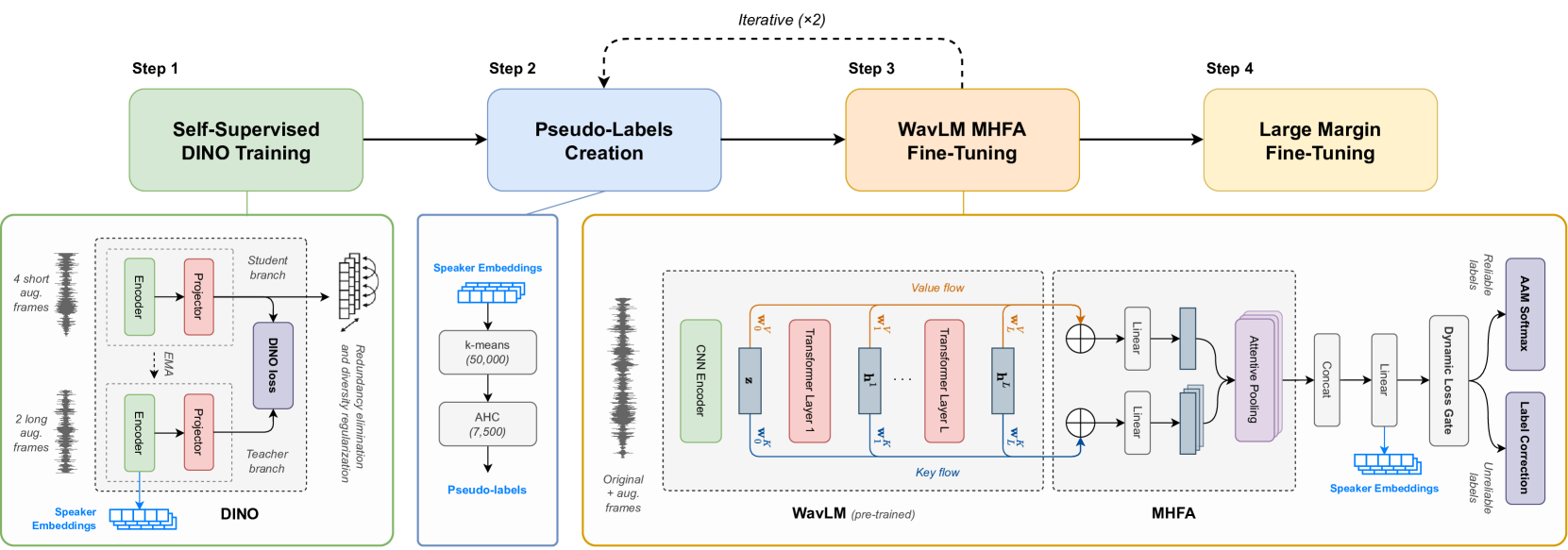
0
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
Read more6/5/2024

0
Attentive Merging of Hidden Embeddings from Pre-trained Speech Model for Anti-spoofing Detection
Zihan Pan, Tianchi Liu, Hardik B. Sailor, Qiongqiong Wang
Self-supervised learning (SSL) speech representation models, trained on large speech corpora, have demonstrated effectiveness in extracting hierarchical speech embeddings through multiple transformer layers. However, the behavior of these embeddings in specific tasks remains uncertain. This paper investigates the multi-layer behavior of the WavLM model in anti-spoofing and proposes an attentive merging method to leverage the hierarchical hidden embeddings. Results demonstrate the feasibility of fine-tuning WavLM to achieve the best equal error rate (EER) of 0.65%, 3.50%, and 3.19% on the ASVspoof 2019LA, 2021LA, and 2021DF evaluation sets, respectively. Notably, We find that the early hidden transformer layers of the WavLM large model contribute significantly to anti-spoofing task, enabling computational efficiency by utilizing a partial pre-trained model.
Read more6/18/2024

0
Progressive Residual Extraction based Pre-training for Speech Representation Learning
Tianrui Wang, Jin Li, Ziyang Ma, Rui Cao, Xie Chen, Longbiao Wang, Meng Ge, Xiaobao Wang, Yuguang Wang, Jianwu Dang, Nyima Tashi
Self-supervised learning (SSL) has garnered significant attention in speech processing, excelling in linguistic tasks such as speech recognition. However, jointly improving the performance of pre-trained models on various downstream tasks, each requiring different speech information, poses significant challenges. To this purpose, we propose a progressive residual extraction based self-supervised learning method, named ProgRE. Specifically, we introduce two lightweight and specialized task modules into an encoder-style SSL backbone to enhance its ability to extract pitch variation and speaker information from speech. Furthermore, to prevent the interference of reinforced pitch variation and speaker information with irrelevant content information learning, we residually remove the information extracted by these two modules from the main branch. The main branch is then trained using HuBERT's speech masking prediction to ensure the performance of the Transformer's deep-layer features on content tasks. In this way, we can progressively extract pitch variation, speaker, and content representations from the input speech. Finally, we can combine multiple representations with diverse speech information using different layer weights to obtain task-specific representations for various downstream tasks. Experimental results indicate that our proposed method achieves joint performance improvements on various tasks, such as speaker identification, speech recognition, emotion recognition, speech enhancement, and voice conversion, compared to excellent SSL methods such as wav2vec2.0, HuBERT, and WavLM.
Read more9/4/2024