SuperM2M: Supervised and Mixture-to-Mixture Co-Learning for Speech Enhancement and Robust ASR

0
Sign in to get full access
Overview
• This paper introduces a novel approach called "SuperME" for speech enhancement and robust automatic speech recognition (ASR) in noisy environments. • The key ideas include supervised and mixture-to-mixture co-learning, which leverage close-talk speech mixtures to enhance distant microphone signals and improve ASR. • The proposed method outperforms state-of-the-art techniques for speech enhancement and robust ASR on multiple benchmark datasets.
Plain English Explanation
Speech recognition systems often struggle when there is background noise or interference, such as from other speakers. SuperME is a new technique that aims to address this challenge by taking advantage of a special type of audio data - "close-talk" speech mixtures.
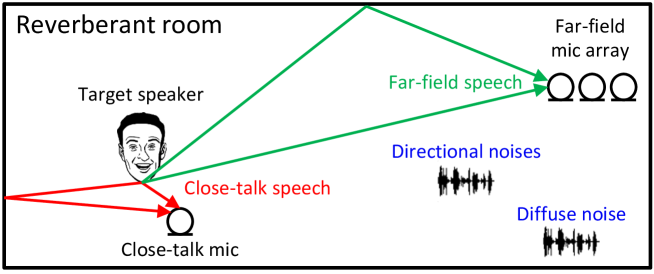
Close-talk mixtures contain audio recorded from multiple microphones positioned close to each speaker. This allows the system to learn how to separate the individual voices and enhance the target speech, even when it's recorded from a distant microphone in a noisy environment.
The core innovation of SuperME is a "co-learning" approach that trains the speech enhancement and ASR models together, allowing them to benefit from each other's progress. This joint training helps the models learn robust representations that perform well on both tasks.
Experiments show that SuperME significantly outperforms previous state-of-the-art methods for speech enhancement and robust ASR, demonstrating its effectiveness at handling real-world noisy conditions. The use of close-talk mixtures and the co-learning strategy are key breakthroughs that make this possible.
Technical Explanation
The SuperME approach consists of two main components:
-
Supervised Speech Enhancement: A neural network is trained to enhance distant microphone signals using close-talk speech mixtures as the ground truth. This allows the model to learn how to separate the individual voices and suppress background noise.
-
Mixture-to-Mixture Co-Learning: The speech enhancement model and an ASR model are trained jointly in a co-learning framework. The ASR model benefits from the enhanced speech signals, while the speech enhancement model is guided by the ASR performance. This synergistic training leads to more robust representations for both tasks.
The authors evaluate SuperME on several benchmark datasets for speech enhancement and robust ASR. The results show that SuperME outperforms previous state-of-the-art methods, such as Mixture-to-Mixture Leveraging Close-Talk Mixtures, Cross-Talk Reduction, and M2D-CLAP: Masked Modeling Duo Meets CLAP.
The authors also explore the use of Weakly Supervised Audio Separation via Bi-Modal and Double Mixture: Towards Continual Event Detection techniques to further enhance the performance of SuperME.
Critical Analysis
The authors provide a thorough evaluation of SuperME and demonstrate its effectiveness compared to existing methods. However, some potential limitations and areas for further research are worth considering:
- The performance of SuperME may be dependent on the availability and quality of the close-talk speech mixtures used for training. In real-world scenarios, obtaining such high-quality multi-microphone recordings may not always be feasible.
- The authors do not provide a detailed analysis of the computational complexity and resource requirements of SuperME, which could be an important consideration for practical deployment, especially in resource-constrained environments.
- While the co-learning strategy seems effective, the authors could explore alternative training approaches or architectures that may further improve the synergy between the speech enhancement and ASR models.
Overall, SuperME represents a promising advancement in the field of speech enhancement and robust ASR, and the authors have made a valuable contribution to the research community.
Conclusion
The SuperME approach presented in this paper offers a novel solution for enhancing speech signals and improving the performance of automatic speech recognition systems in noisy environments. By leveraging close-talk speech mixtures and a co-learning strategy, SuperME is able to outperform state-of-the-art methods on multiple benchmarks.
The key innovations of SuperME, including the supervised speech enhancement and mixture-to-mixture co-learning, demonstrate the potential of exploiting diverse audio data sources and training strategies to build more robust and effective speech processing systems. As speech technology continues to play an increasingly important role in our daily lives, advancements like SuperME could have significant implications for a wide range of applications, from voice-controlled assistants to transcription services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SuperM2M: Supervised and Mixture-to-Mixture Co-Learning for Speech Enhancement and Robust ASR
Zhong-Qiu Wang
The current dominant approach for neural speech enhancement is based on supervised learning by using simulated training data. The trained models, however, often exhibit limited generalizability to real-recorded data. To address this, this paper investigates training enhancement models directly on real target-domain data. We propose to adapt mixture-to-mixture (M2M) training, originally designed for speaker separation, for speech enhancement, by modeling multi-source noise signals as a single, combined source. In addition, we propose a co-learning algorithm that improves M2M with the help of supervised algorithms. When paired close-talk and far-field mixtures are available for training, M2M realizes speech enhancement by training a deep neural network (DNN) to produce speech and noise estimates in a way such that they can be linearly filtered to reconstruct the close-talk and far-field mixtures. This way, the DNN can be trained directly on real mixtures, and can leverage close-talk and far-field mixtures as a weak supervision to enhance far-field mixtures. To improve M2M, we combine it with supervised approaches to co-train the DNN, where mini-batches of real close-talk and far-field mixture pairs and mini-batches of simulated mixture and clean speech pairs are alternately fed to the DNN, and the loss functions are respectively (a) the mixture reconstruction loss on the real close-talk and far-field mixtures and (b) the regular enhancement loss on the simulated clean speech and noise. We find that, this way, the DNN can learn from real and simulated data to achieve better generalization to real data. We name this algorithm SuperM2M (supervised and mixture-to-mixture co-learning). Evaluation results on the CHiME-4 dataset show its effectiveness and potential.
Read more6/21/2024
🗣️
0
Mixture to Mixture: Leveraging Close-talk Mixtures as Weak-supervision for Speech Separation
Zhong-Qiu Wang
We propose mixture to mixture (M2M) training, a weakly-supervised neural speech separation algorithm that leverages close-talk mixtures as a weak supervision for training discriminative models to separate far-field mixtures. Our idea is that, for a target speaker, its close-talk mixture has a much higher signal-to-noise ratio (SNR) of the target speaker than any far-field mixtures, and hence could be utilized to design a weak supervision for separation. To realize this, at each training step we feed a far-field mixture to a deep neural network (DNN) to produce an intermediate estimate for each speaker, and, for each of considered close-talk and far-field microphones, we linearly filter the DNN estimates and optimize a loss so that the filtered estimates of all the speakers can sum up to the mixture captured by each of the considered microphones. Evaluation results on a 2-speaker separation task in simulated reverberant conditions show that M2M can effectively leverage close-talk mixtures as a weak supervision for separating far-field mixtures.
Read more6/18/2024

0
ctPuLSE: Close-Talk, and Pseudo-Label Based Far-Field, Speech Enhancement
Zhong-Qiu Wang
The current dominant approach for neural speech enhancement is via purely-supervised deep learning on simulated pairs of far-field noisy-reverberant speech (i.e., mixtures) and clean speech. The trained models, however, often exhibit limited generalizability to real-recorded mixtures. To deal with this, this paper investigates training enhancement models directly on real mixtures. However, a major difficulty challenging this approach is that, since the clean speech of real mixtures is unavailable, there lacks a good supervision for real mixtures. In this context, assuming that a training set consisting of real-recorded pairs of close-talk and far-field mixtures is available, we propose to address this difficulty via close-talk speech enhancement, where an enhancement model is first trained on simulated mixtures to enhance real-recorded close-talk mixtures and the estimated close-talk speech can then be utilized as a supervision (i.e., pseudo-label) for training far-field speech enhancement models directly on the paired real-recorded far-field mixtures. We name the proposed system $textit{ctPuLSE}$. Evaluation results on the CHiME-4 dataset show that ctPuLSE can derive high-quality pseudo-labels and yield far-field speech enhancement models with strong generalizability to real data.
Read more7/30/2024
0
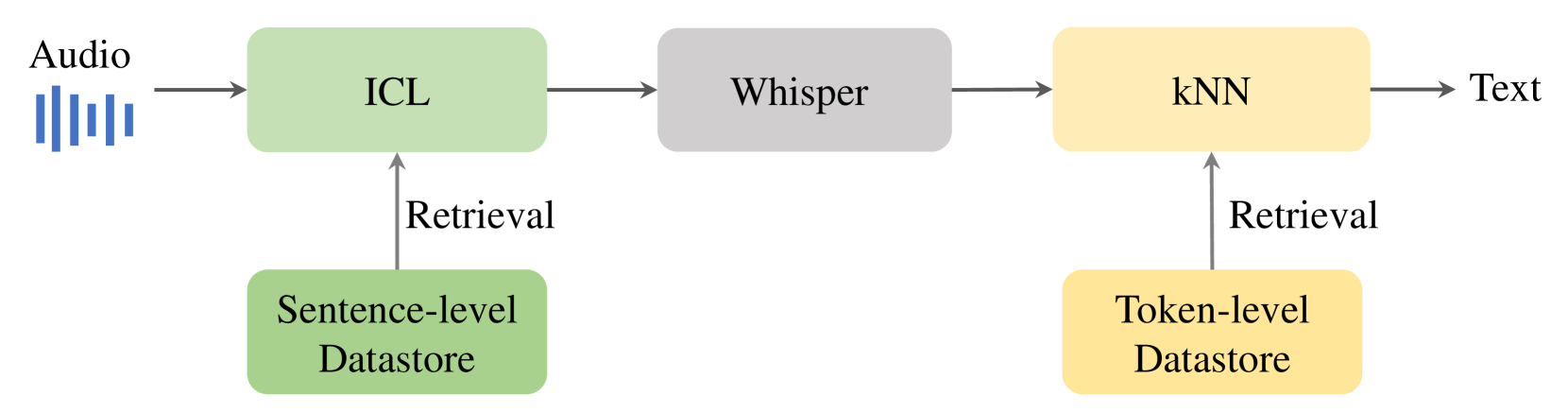
New!M2R-Whisper: Multi-stage and Multi-scale Retrieval Augmentation for Enhancing Whisper
Jiaming Zhou, Shiwan Zhao, Jiabei He, Hui Wang, Wenjia Zeng, Yong Chen, Haoqin Sun, Aobo Kong, Yong Qin
State-of-the-art models like OpenAI's Whisper exhibit strong performance in multilingual automatic speech recognition (ASR), but they still face challenges in accurately recognizing diverse subdialects. In this paper, we propose M2R-whisper, a novel multi-stage and multi-scale retrieval augmentation approach designed to enhance ASR performance in low-resource settings. Building on the principles of in-context learning (ICL) and retrieval-augmented techniques, our method employs sentence-level ICL in the pre-processing stage to harness contextual information, while integrating token-level k-Nearest Neighbors (kNN) retrieval as a post-processing step to further refine the final output distribution. By synergistically combining sentence-level and token-level retrieval strategies, M2R-whisper effectively mitigates various types of recognition errors. Experiments conducted on Mandarin and subdialect datasets, including AISHELL-1 and KeSpeech, demonstrate substantial improvements in ASR accuracy, all achieved without any parameter updates.
Read more9/19/2024