Safe Multi-agent Reinforcement Learning with Natural Language Constraints
2405.20018
0
0
🏅
Abstract
The role of natural language constraints in Safe Multi-agent Reinforcement Learning (MARL) is crucial, yet often overlooked. While Safe MARL has vast potential, especially in fields like robotics and autonomous vehicles, its full potential is limited by the need to define constraints in pre-designed mathematical terms, which requires extensive domain expertise and reinforcement learning knowledge, hindering its broader adoption. To address this limitation and make Safe MARL more accessible and adaptable, we propose a novel approach named Safe Multi-agent Reinforcement Learning with Natural Language constraints (SMALL). Our method leverages fine-tuned language models to interpret and process free-form textual constraints, converting them into semantic embeddings that capture the essence of prohibited states and behaviours. These embeddings are then integrated into the multi-agent policy learning process, enabling agents to learn policies that minimize constraint violations while optimizing rewards. To evaluate the effectiveness of SMALL, we introduce the LaMaSafe, a multi-task benchmark designed to assess the performance of multiple agents in adhering to natural language constraints. Empirical evaluations across various environments demonstrate that SMALL achieves comparable rewards and significantly fewer constraint violations, highlighting its effectiveness in understanding and enforcing natural language constraints.
Create account to get full access
Overview
- The paper proposes a novel approach called Safe Multi-agent Reinforcement Learning with Natural Language constraints (SMALL) to make Safe Multi-agent Reinforcement Learning (MARL) more accessible and adaptable.
- Safe MARL has significant potential in fields like robotics and autonomous vehicles, but its adoption is limited by the need for extensive domain expertise to define constraints in mathematical terms.
- SMALL leverages fine-tuned language models to interpret and process free-form textual constraints, converting them into semantic embeddings that capture the essence of prohibited states and behaviors.
- These embeddings are then integrated into the multi-agent policy learning process, enabling agents to learn policies that minimize constraint violations while optimizing rewards.
Plain English Explanation
Safe MARL is a powerful technique that could be used to train teams of autonomous agents, like robots or self-driving cars, to operate safely and reliably. However, the current approach requires experts to define the rules or constraints for safe behavior in complex mathematical terms, which can be challenging and time-consuming.
The SMALL method proposed in this paper provides a more user-friendly solution. It uses advanced language models to understand natural language descriptions of the desired safe behaviors, like "don't drive too fast" or "avoid collisions." The system then translates these descriptions into a format that the reinforcement learning algorithms can use to guide the agents' learning process, helping them learn policies that maximize rewards while minimizing violations of the specified constraints.
This makes Safe MARL much more accessible to a wider range of users, as they no longer need to be experts in reinforcement learning or have a deep understanding of the mathematical details. Instead, they can simply describe the safety requirements in plain language, and the SMALL system will handle the rest.
Technical Explanation
The core idea behind SMALL is to leverage large language models to interpret and process free-form textual constraints, converting them into semantic embeddings that capture the essence of prohibited states and behaviors. These embeddings are then integrated into the multi-agent policy learning process, enabling agents to learn policies that minimize constraint violations while optimizing rewards.
The authors introduce a new benchmark, called LaMaSafe, to evaluate the performance of SMALL across various environments. The LaMaSafe benchmark includes multiple tasks designed to assess the agents' ability to adhere to natural language constraints.
Empirical evaluations show that SMALL achieves comparable rewards to existing methods while significantly reducing the number of constraint violations. This highlights the effectiveness of the approach in understanding and enforcing natural language constraints in the context of Safe MARL.
Critical Analysis
The SMALL approach addresses an important limitation of current Safe MARL methods by making it more accessible to a wider range of users. However, the paper does not discuss the potential limitations or challenges of using language models for this purpose.
For example, language models can sometimes produce biased or inconsistent outputs, which could lead to issues in translating natural language constraints into effective policy guidance. Additionally, the performance of SMALL may be sensitive to the quality and diversity of the training data used to fine-tune the language model.
Further research is needed to explore the robustness and reliability of SMALL in handling a wide range of natural language constraints, especially in complex, dynamic environments. Evaluating the system's performance on real-world tasks, such as autonomous vehicle control or robotic navigation, would also provide valuable insights into its practical applicability.
Conclusion
The SMALL approach proposed in this paper represents a significant step forward in making Safe MARL more accessible and adaptable. By leveraging language models to interpret natural language constraints, the method reduces the barrier to entry for users who lack extensive domain expertise in reinforcement learning and optimization.
The successful demonstration of SMALL's performance in the LaMaSafe benchmark suggests that this approach could pave the way for wider adoption of Safe MARL, unlocking its potential in a variety of applications, such as robotics, autonomous vehicles, and other safety-critical domains. As the field continues to evolve, further research and refinement of SMALL and similar techniques will be crucial in realizing the full potential of Safe MARL.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
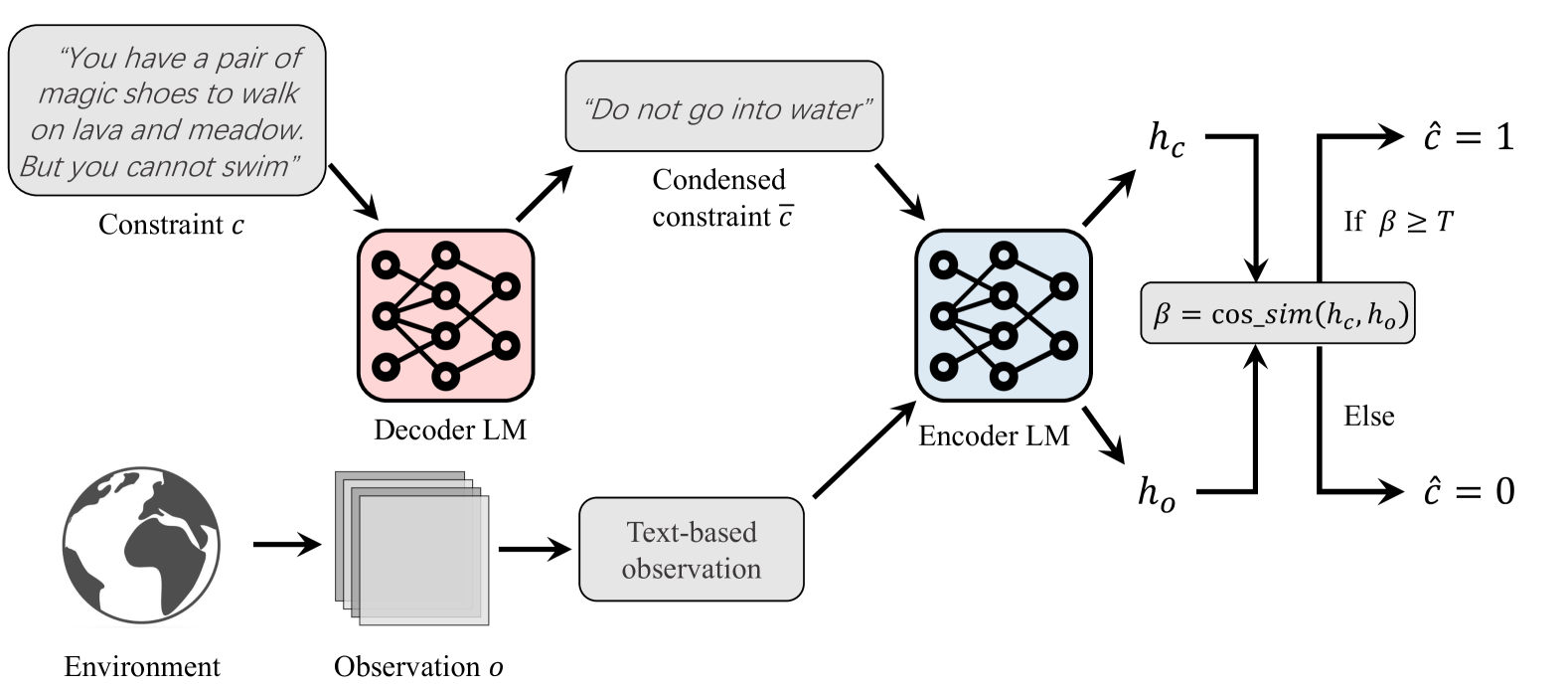
Safe Reinforcement Learning with Free-form Natural Language Constraints and Pre-Trained Language Models
Xingzhou Lou, Junge Zhang, Ziyan Wang, Kaiqi Huang, Yali Du
0
0
Safe reinforcement learning (RL) agents accomplish given tasks while adhering to specific constraints. Employing constraints expressed via easily-understandable human language offers considerable potential for real-world applications due to its accessibility and non-reliance on domain expertise. Previous safe RL methods with natural language constraints typically adopt a recurrent neural network, which leads to limited capabilities when dealing with various forms of human language input. Furthermore, these methods often require a ground-truth cost function, necessitating domain expertise for the conversion of language constraints into a well-defined cost function that determines constraint violation. To address these issues, we proposes to use pre-trained language models (LM) to facilitate RL agents' comprehension of natural language constraints and allow them to infer costs for safe policy learning. Through the use of pre-trained LMs and the elimination of the need for a ground-truth cost, our method enhances safe policy learning under a diverse set of human-derived free-form natural language constraints. Experiments on grid-world navigation and robot control show that the proposed method can achieve strong performance while adhering to given constraints. The usage of pre-trained LMs allows our method to comprehend complicated constraints and learn safe policies without the need for ground-truth cost at any stage of training or evaluation. Extensive ablation studies are conducted to demonstrate the efficacy of each part of our method.
5/16/2024
🏅
LLM-based Multi-Agent Reinforcement Learning: Current and Future Directions
Chuanneng Sun, Songjun Huang, Dario Pompili
0
0
In recent years, Large Language Models (LLMs) have shown great abilities in various tasks, including question answering, arithmetic problem solving, and poem writing, among others. Although research on LLM-as-an-agent has shown that LLM can be applied to Reinforcement Learning (RL) and achieve decent results, the extension of LLM-based RL to Multi-Agent System (MAS) is not trivial, as many aspects, such as coordination and communication between agents, are not considered in the RL frameworks of a single agent. To inspire more research on LLM-based MARL, in this letter, we survey the existing LLM-based single-agent and multi-agent RL frameworks and provide potential research directions for future research. In particular, we focus on the cooperative tasks of multiple agents with a common goal and communication among them. We also consider human-in/on-the-loop scenarios enabled by the language component in the framework.
5/21/2024

Safe Multi-Agent Reinforcement Learning with Bilevel Optimization in Autonomous Driving
Zhi Zheng, Shangding Gu
0
0
Ensuring safety in MARL, particularly when deploying it in real-world applications such as autonomous driving, emerges as a critical challenge. To address this challenge, traditional safe MARL methods extend MARL approaches to incorporate safety considerations, aiming to minimize safety risk values. However, these safe MARL algorithms often fail to model other agents and lack convergence guarantees, particularly in dynamically complex environments. In this study, we propose a safe MARL method grounded in a Stackelberg model with bi-level optimization, for which convergence analysis is provided. Derived from our theoretical analysis, we develop two practical algorithms, namely Constrained Stackelberg Q-learning (CSQ) and Constrained Stackelberg Multi-Agent Deep Deterministic Policy Gradient (CS-MADDPG), designed to facilitate MARL decision-making in autonomous driving applications. To evaluate the effectiveness of our algorithms, we developed a safe MARL autonomous driving benchmark and conducted experiments on challenging autonomous driving scenarios, such as merges, roundabouts, intersections, and racetracks. The experimental results indicate that our algorithms, CSQ and CS-MADDPG, outperform several strong MARL baselines, such as Bi-AC, MACPO, and MAPPO-L, regarding reward and safety performance. The demos and source code are available at {https://github.com/SafeRL-Lab/Safe-MARL-in-Autonomous-Driving.git}.
5/29/2024
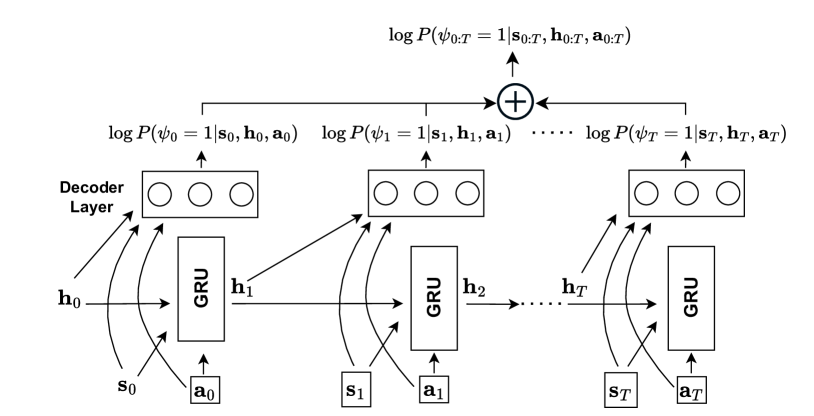
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
0
0
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
5/7/2024